在大模型时代,算力需求如潮水般上涨。然而,现实中的生产集群往往并非清一色的顶级显卡,而是由A100、3090甚至老旧的P100等不同性能和内存配置的 GPU 混搭而成——这种异构 GPU 集群虽能降低成本,却给大语言模型(LLM)服务带来了巨大挑战:高配 GPU 空转等待,低配 GPU 内存耗尽,整体效率大打折扣。
面对这一行业痛点,最新研究提出了一套颠覆性解决方案。来自澳门大学与中山大学的研究团队在 SC '25 上发表论文,推出了名为 Hetis 的新型 LLM 服务系统。该系统不仅将服务吞吐量最高提升了2.25 倍,还将推理延迟降低了1.49 倍,其背后究竟有何创新玄机?
核心看点

Hetis 的核心突破在于彻底改变了传统 LLM 服务中“一刀切”的并行策略。它首次提出了细粒度动态并行机制,精准匹配异构硬件资源与模型模块特性。具体而言,Hetis 通过主工作节点并行化(Primary Worker Parallelism)优化计算密集型模块(如 MLP),仅在高性能 GPU 间进行协作;同时引入动态头级注意力并行化(Dynamic Head-wise Attention Parallelism),将轻量级的Attention计算灵活分发至所有 GPU,包括低性能设备。在此基础上,系统还设计了在线调度算法,实时平衡网络、计算与内存负载,从而实现了资源利用率的全局最优化。
研究背景
当前主流的 LLM 服务系统在异构环境下面临两大核心瓶颈:内存效率低下与计算资源错配。以 Splitwise 为代表的阶段拆分方案,将预填充(Prefill)与解码(Decode)任务分别交给高/低性能 GPU 执行,虽缓解了计算压力,却导致 KV 缓存空间严重不足。而 Hexgen 等采用非对称参数划分的系统,则因计算能力与内存容量的不匹配,造成高端 GPU 内存大量闲置。

更深层的问题在于,现有方法普遍采用静态并行策略,无法适应请求长度、批次大小等动态变化。例如,MLP 模块在 A100 与 P100 上的运算速度差距可达 24.5 倍,若强行统一并行,低效设备将成为拖累整体性能的“短板”。与此同时,Attention 模块因其无参数特性和较低的计算强度,在各类 GPU 上表现相对均衡,具备更高的并行灵活性。Hetis 正是抓住了这一关键差异,开启了精细化调度的新思路。
核心贡献
方法创新:模块级差异化并行架构

Hetis 的核心是“按需分配”的并行哲学。对于计算密集的 MLP 和预填充阶段的 Attention,系统通过一个层次化搜索过程,自动筛选出最优的主工作节点组合,并在此子集内应用数据、流水线与张量并行(DP/PP/TP),力求最小化通信开销与计算延迟。那些未被选中的低端 GPU 则被划为注意力工作节点(Attention Workers),专司 Attention 计算任务。
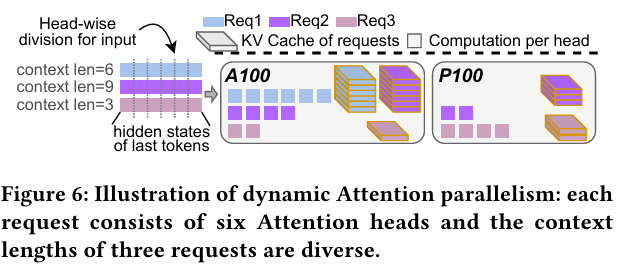
针对 Attention 模块,Hetis 创新性地采用头维度(head-wise)进行分割。相比按请求或序列长度拆分,头级并行能显著减少跨设备通信量。实验表明,在仅卸载 20%负载时,头级分割的通信开销比序列级分割降低近2.68 倍;当使用 4 个注意力工作节点时,延迟优势可达3.55 倍。
实证成果:吞吐与延迟双重突破
在包含 A100、3090 和 P100 的真实异构集群上,Hetis 展现了卓越性能。测试涵盖Llama-13B、OPT-30B和Llama-70B等多种模型及真实工作负载(聊天、代码生成、长文本摘要)。结果显示:
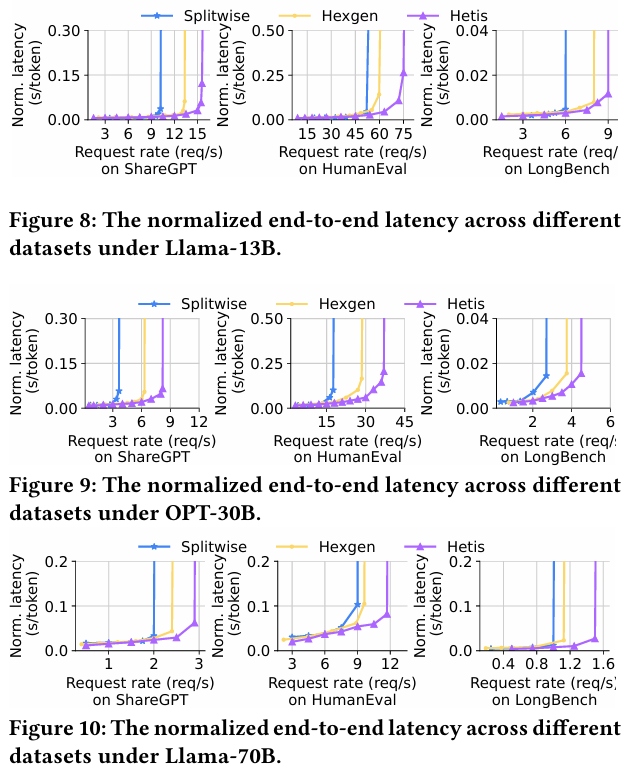
吞吐量最高提升至基线系统的2.25 倍(对比 Splitwise)和1.33 倍(对比 Hexgen); 推理延迟方面,P95 的TTFT(首令牌时间)和TPOT(每令牌处理时间)分别改善最多1.47 倍和1.39 倍; KV 缓存空间利用率提升显著,最大可用缓存空间比基线多出1.87 倍,有效支持更多并发请求。
这些数据充分验证了 Hetis 在复杂动态环境下的鲁棒性与高效性。

在方法创新的基础上,团队进一步验证了系统的自适应能力。Hetis 内置的在线调度器(Dispatcher)基于对计算与通信成本的显式建模,实时决策每个请求的注意力头分配方案。当遇到超长上下文导致负载不均时,系统还能触发重调度机制(Re-dispatching),动态迁移部分计算任务,避免单点瓶颈。
此外,为支撑头级并行,Hetis 实现了头粒度 KV 缓存管理,开发了新的 CUDA 内核以高效索引与传输缓存块。尽管存储元数据开销增加13% ,但得益于 CPU 多核加速,缓存获取时间反而减少了26% ,实现了总体性能净增益。
行业意义
Hetis 的出现,为异构算力环境下的大模型部署提供了全新的技术范式。它标志着 LLM 服务正从粗放式的资源堆砌,迈向精细化、动态化的智能调度时代。这一思路与国家倡导的绿色计算和算力普惠政策高度契合,有助于盘活存量算力资产,降低 AI 应用门槛。
未来,Hetis 所验证的模块感知并行(Module-aware Parallelism)理念有望推动整个分布式推理技术路线的演进。无论是边缘计算中的混合芯片,还是云平台上的抢占式实例,此类动态适配机制都将成为提升资源利用效率的关键。可以预见,随着大模型应用场景的不断下沉,像 Hetis 这样的智能调度系统,将在构建高效、可持续的 AI 基础设施中扮演变革性角色。
论文原文:Hetis: Serving LLMs in Heterogeneous GPU Clusters with Fine-grained and Dynamic Parallelism[1]
Hetis: Serving LLMs in Heterogeneous GPU Clusters with Fine-grained and Dynamic Parallelism: https://arxiv.org/abs/2509.08309
-- 完 --
机智流推荐阅读:
1. 聊聊阿里的新深度研究框架:WebWeaver 如何通过双智能体突破传统开源方案“先搜后写”和““静态大纲引导搜索”两种范式
2. SGLang case study:W4A8 GroupGEMM 学习
3. LLM真能读懂报表吗?EMNLP'25首个工业级表格生成报告基准T2R-bench:最强大模型仅得62分
4. 抢先 Qwen Next?腾讯自研 FastMTP 重磅开源:推理速度暴涨 203%,消费级显卡也能跑出无损速度翻倍!
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群










