在工业级大语言模型(LLM)应用中,动态适配任务与保留既有能力的 “自进化” 需求日益迫切。真实场景中,不同领域语言模式差异显著,LLM 需在学习新场景合规规则的同时,不丢失旧场景的判断能力。这正是大模型自进化核心诉求,即 “自主优化跨任务知识整合,适应动态环境而无需大量外部干预”。
为解决此问题,北邮百家 AI 团队与腾讯 AI Lab 团队提出参数高效的对抗性混合专家架构 MoE-CL,专门用于 LLM 的自进化持续指令微调。其核心设计在于 “解耦 LoRA 专家” 与 “GAN 对抗降噪” 的结合:为每个任务配置专属 LoRA 专家以保留任务特定知识,避免参数更新相互干扰;同时设置共享 LoRA 专家,通过生成对抗网络(GAN)中的任务感知鉴别器抑制无关噪声,确保跨任务知识高效且精准传递,最终实现 “知识保留” 与 “跨任务泛化” 的平衡,这也是 LLM 自进化的核心逻辑。
从实验效果来看,MoE-CL 的自进化能力已在实际场景与基准测试中得到验证。在腾讯真实业务场景 A/B 测试中,它将人工介入成本降低 15.3%;在公开 MTL5 跨域基准与工业级 Tencent3 基准测试中,其平均准确率优于现有主流方法,且在不同任务训练顺序下保持稳定,证明其无需人工调整即可适配任务动态变化。

论文标题: Self-Evolving LLMs via Continual Instruction Tuning
论文链接: https://arxiv.org/abs/2509.18133
代码仓库:https://github.com/BAI-LAB/MoE-CL
01 引言
在数字经济蓬勃发展的当下,海量文本数据如潮水般涌入互联网平台。例如,新闻资讯的快速更新、电商平台的海量评论等多源异构数据每日激增,面临跨领域、高时效、强精度的多重挑战。若采用传统方案,为每种文本类型单独训练模型,将消耗巨大的计算资源与人力成本;而使用单一模型处理全领域文本,又因数据分布差异导致性能失衡,难以满足业务需求。在此背景下,亟需一种既能高效处理新任务,又能保留旧任务知识的通用技术方案。为此,我们提出 MoE-CL 大模型混合专家(MoE)持续学习架构,致力于打破传统方法的局限,以实现多领域文本任务的高效协同处理。使得大模型具备自进化能力:动态适应训练数据,自主优化跨任务知识整合。
02 方法
混合专家持续学习(MoE-CL)框架聚焦多任务学习中的知识积累与任务适应难题。其核心采用 Transformer 块的 LoRA 增强技术,重点优化前馈神经网络(FFN)层,通过引入低秩矩阵降低参数更新量与计算成本,同时提升学习效率。
MoE-CL 将 LoRA 专家分为任务特定与任务共享两类:前者专攻特定任务知识,后者提取跨任务通用信息。结合生成对抗网络(GAN)分离任务特定与共享信息,确保模型获取高质量共享知识。
架构上,N 层 LoRA 增强的 Transformer 块级联提取信息,最终由门控网络融合两类信息,为任务预测提供支撑。这种设计使模型既能满足任务特异性需求,又能利用任务共性,实现高效持续学习。

图 1:MoE-CL 的整体框架。MoE-CL 通过采用带有任务感知判别器的对抗性 MoE-LoRA 架构,缓解了灾难性遗忘问题。MoE-CL 主要由两部分组成,任务感知判别器优化和指令调整优化。
2.1 任务感知判别器优化
任务感知判别器作为 MoE-CL 框架中的关键组件,其核心功能是识别任务标签。在 Transformer 块中,设第 i 个前馈层的输入向量为  ,针对任务 t,MoE-CL 通过 LoRA 技术分别生成任务共享表示
,针对任务 t,MoE-CL 通过 LoRA 技术分别生成任务共享表示 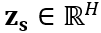 与任务特定表示
与任务特定表示  ,具体计算如下:
,具体计算如下:
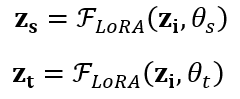
其中,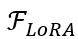 为 LoRA 模块的运算函数,作用于大语言模型中已冻结的参数;
为 LoRA 模块的运算函数,作用于大语言模型中已冻结的参数; 和
和  分别对应任务共享 LoRA 专家与任务 t 专属 LoRA 专家的可学习参数,实现知识的分离与共享。
分别对应任务共享 LoRA 专家与任务 t 专属 LoRA 专家的可学习参数,实现知识的分离与共享。
基于上述表示,任务感知判别器通过 softmax 函数  预测任务标签
预测任务标签  :
:
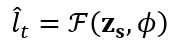
其中,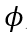 为任务分类器的学习参数,通过训练优化以提升标签预测准确性。
为任务分类器的学习参数,通过训练优化以提升标签预测准确性。
在生成对抗网络(GAN)模块中,为确保任务共享信息的质量,模型通过交叉熵损失函数  计算预测标签
计算预测标签  与真实标签
与真实标签 之间的差异,从而构建损失函数
之间的差异,从而构建损失函数  :
:

通过最小化  ,模型能够有效分离任务特定信息与共享信息,促使任务共享专家学习到更具泛化性的知识,进而提升 MoE-CL 框架在多任务场景下的性能表现。
,模型能够有效分离任务特定信息与共享信息,促使任务共享专家学习到更具泛化性的知识,进而提升 MoE-CL 框架在多任务场景下的性能表现。
2.2 指令调整优化
指令微调阶段,MoE-CL 通过加权组合任务共享表示 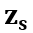 与任务特定表示
与任务特定表示  进行任务 t 的预测。二者经门控网络
进行任务 t 的预测。二者经门控网络  自动生成的权重系数
自动生成的权重系数 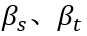 进行线性插值,得到 Transformer 模块第 i 层的输出向量:
进行线性插值,得到 Transformer 模块第 i 层的输出向量:

 输入多层感知器后输出预测结果
输入多层感知器后输出预测结果  ,结合真实标签
,结合真实标签 通过交叉熵函数
通过交叉熵函数  计算预测损失
计算预测损失  。
。
为强化任务共享信息的泛化能力,MoE-CL 将生成对抗损失  与预测损失融合,形成最终优化目标:
与预测损失融合,形成最终优化目标:

其中,超参数 α∈(0,1) 用于平衡两种损失权重。通过最小化  ,模型在保留任务特异性知识的同时,最大化跨任务知识迁移效果。
,模型在保留任务特异性知识的同时,最大化跨任务知识迁移效果。
03 实验
我们在 MTL5 和 Tencent3 两个评测基准上进行了实验,并将我们的方法与几种具有代表性的持续学习方法进行比较,以展示 MoE-CL 的有效性。
3.1 主实验结果
MTL5 和 Tencent3 评测基准上的实验结果如图 2,3 所示,有以下结论:

Tencent3 评测基准上的实验结果,使用腾讯混元作为基座模型。粗体和斜体表示根据主要评估指标准确率的最优和次优。
泛化能力与稳定性突出:相比所有基线方法,MoE-CL 平均准确率显著提升,且方差极小,在复杂任务中展现出优异的泛化能力与稳定性;
知识迁移优势显著:MoE-CL 在正反向迁移上表现稳定,较 MoCL 更不易受后续任务影响,验证了生成对抗网络集成至混合 LoRA 专家网络的有效性;
鲁棒性表现出色:面对不同任务序列顺序,MoE-CL 通过分离共享与特定任务专家的架构设计,在 MTL5 和 Tencent3 基准测试中展现出极强的鲁棒性 ,远超其他基线方法。
3.2 验证生成对抗网络的有效性
为验证对抗性 MoE-LoRA 架构对灾难性遗忘的抑制效果,本文构建了不含生成对抗网络(GAN)的 MoE-CL 对比版本。实验结果(图 4)显示,含 GAN 的 MoE 专家架构在持续学习任务中平均性能显著优于无 GAN 版本。这是因为 GAN 能够精准将特定任务信息分配至对应低秩适配器专家,有效规避任务间知识干扰,尤其在反向迁移(BwT)指标上表现突出,有力证明了 GAN 在防止灾难性遗忘方面的关键作用。

图 4:生成对抗网络对 MoE-CL 的影响。三个指标都是数值越大表明性能越好。
3.3 离线 A/B 测试
在腾讯真实文本分类任务中,模型依据置信度得分自动判定内容样本类别:超出阈值的样本被直接标记为合规(白样本)或不合规(黑样本),无需人工介入。剔除率作为核心评估指标,直观反映自动分类样本占比,剔除率越高,意味着人工成本越低。
为验证 MoE-CL 的实际应用价值,研究团队开展离线 A/B 测试,对比其与生产算法的剔除率表现。实验数据(图 5)显示,在任务 A 和任务 B 场景下,MoE-CL 均实现显著突破。其中,任务 A 场景中 MoE-CL 剔除率高达 28.8%,较基线算法提升 15.3%,直接降低了同等比例的人工介入工作量,切实为业务场景带来降本增效的商业价值。

通过剔除率衡量的离线 A/B 测试。
04 总结
混合专家持续学习框架 MoE-CL 通过三大核心设计破局:专属任务专家防止灾难性遗忘,任务共享专家促进跨任务知识迁移,生成对抗网络保障共享信息质量。三者协同运作,使模型高效适应新任务,实现大模型持续学习中的自进化。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com