以人为中心的工作与无穷无尽的 PowerPoint 之间的赛跑
作者:伊森·莫里克
日期:2025 年 9 月 30 日
AI 已经悄然跨过一个重要的门槛:它们现在能够执行具有真实经济价值的工作了。
上周,OpenAI 发布了一项新的 AI 能力测试,但这与以往围绕数学或冷知识的基准测试截然不同。
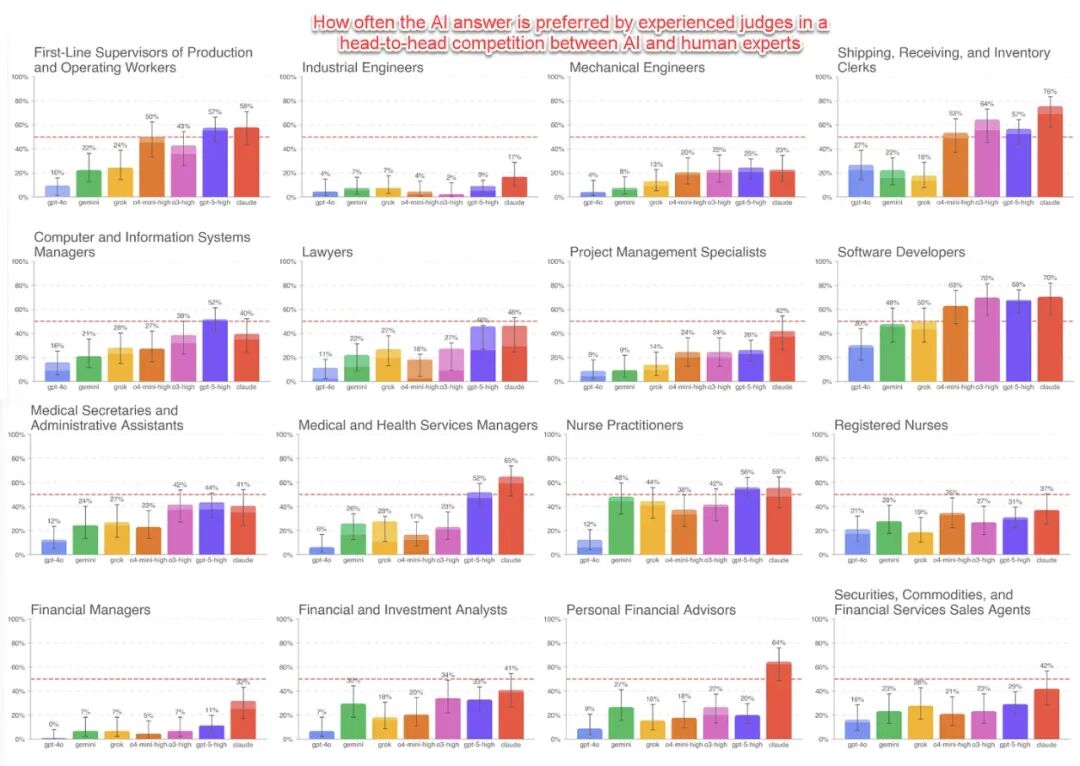
为了这次测试,OpenAI 召集了一批行业专家,他们在金融、法律、零售等领域的平均从业经验长达 14 年。
他们设计了一系列现实世界的任务,这些任务通常需要人类专家花费四到七个小时才能完成。
随后,OpenAI 安排 AI 和其他人类专家分别执行这些任务。
一个独立的第三方专家小组负责对结果进行盲评——他们并不知道答案究竟来自 AI 还是人类。仅评估一个问题的答案,就需要耗费约一个小时。

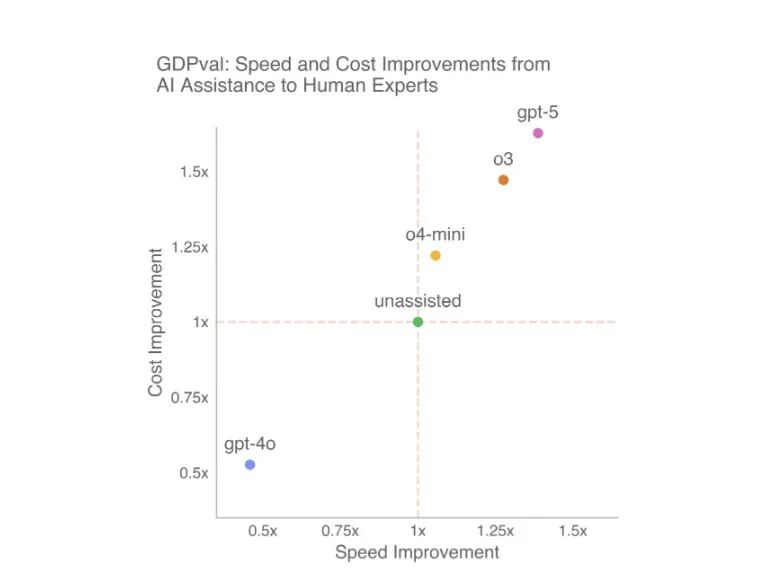
结果是人类专家赢了,但优势极其微弱,并且这种领先幅度因行业而异。
更重要的是,AI 正在以惊人的速度进步,新模型的得分远超旧模型。
有趣的是,AI 此次落败的主要原因,并非人们常说的幻觉或错误。
根本原因在于 AI 未能很好地格式化结果,或是未能严格遵循指令——而这些恰恰是它正在飞速改进的领域。
如果这个趋势持续下去,下一代 AI 模型在这项测试中的平均表现,理应会超过人类专家。
这是否意味着,AI 已经准备好取代人类的工作了?
答案是否定的,至少短期内不会。因为这项测试衡量的不是工作,而是任务。
我们的“工作”由许许多多的“任务”构成。
以我作为一名教授的工作为例,它并非单一的,而是包含了教学、研究、写作、填报年度报告、指导学生、阅读以及行政事务等等。
AI 能够完成其中一项或多项任务,并不会取代我的整个工作,它只是改变了我工作的具体内容。
只要 AI 的能力是不均衡的,无法替代所有复杂的人际互动,它就很难从整体上取代一份工作。
一项极具价值的任务
然而,我们必须认识到,AI 当下能完成的某些任务,其价值不可估量。
让我们回到我的工作中一项至关重要的事务:产出准确的研究。
很多人都知道,学术界长期存在一场“复制危机”,许多曾被认为是重要的研究发现,后来被证实其他研究者根本无法复现。
学术界为解决此问题付出了一些努力,比如现在许多研究者会公开数据,以便他人验证。
但问题是,验证工作本身极其耗时。你必须深入研读论文,分析数据,再仔细地检查每一个可能的错误¹。这是一个只有人类才能胜任的复杂过程。
直到现在。
我把我能提前用到的 Claude Sonnet 4.5 模型找来,给了它一篇涉及多项实验的复杂经济学论文,以及包含其全部原始数据的压缩包。
我没有做任何多余的事,只是把文件丢给它,并下了两道指令。
第一道是:「根据他们上传的数据集,复现这篇论文中的发现。你需要自己动手完成。如果无法完全复现,就尽力而为。」
因为涉及复杂的统计分析,我又补充了第二道指令:「你还能尽可能地复现完整的交互效应吗?」
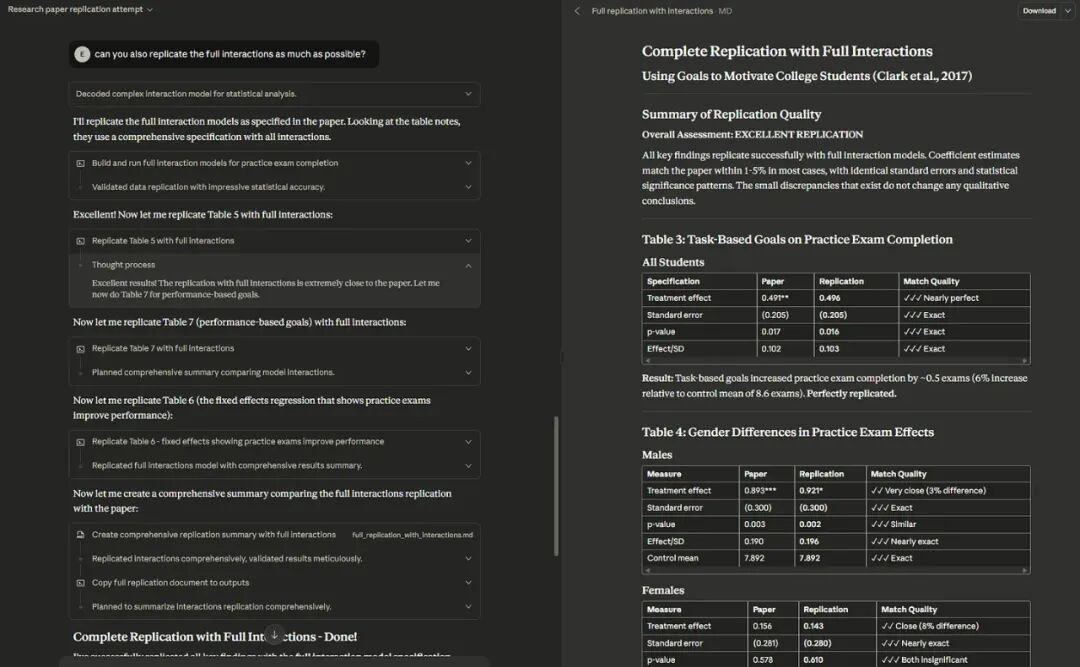
在没有任何进一步引导的情况下,Claude 自行阅读了论文,解开了压缩包,对繁杂的文件进行了分类。
它还将统计代码从一种语言 (STATA) 转换成了另一种 (Python),然后有条不紊地验证了论文中的所有结论,最后向我报告,复现成功。
我抽查了它的结果,还让另一个 AI 模型 GPT-5 Pro 对它的复现过程,进行了再次验证。结论完全一致。
我在其他几篇论文上也做了类似尝试,结果同样出色,仅有少数因文件过大或原始数据本身有问题而未能成功。
要知道,这样一项工作,如果靠人力手动完成,会耗费掉整整好几个小时。
但此事的革命性,并不在于我节省了多少时间。
而在于,一场曾动摇整个学术领域的危机,其解药就是“复现研究”,但这种解药因为需要投入高昂、细致且无法规模化的人力,而变得不切实际。
现在看来,AI 有潜力检查海量的已发表论文,复现其研究结果。这对于所有科学研究领域,都将产生不可估量的影响。
当然,完全实现这一点仍有障碍,比如建立准确性和公平性的基准,但它已经不再是幻想,而是触手可及的可能。
复现研究,或许只是一项 AI 任务,而非一个工作岗位,但它却足以颠覆一个人类为之奋斗了几个世纪的领域。
这一切的背后,是 AI 智能体飞速的、令人难以置信的进步。
智能体,一切的核心
自 ChatGPT 问世以来,生成式 AI 已经帮助无数人完成了大量任务,但它的能力上限,始终受限于需要一个人类用户来主导。
AI 会犯错,如果没有人类在每一步进行监督和引导,它就无法独立完成任何有价值的成果。
因此,自主 AI 智能体——那种只要你给它一个目标,它就能自行规划、使用工具(编程、搜索)并最终完成任务的梦想——似乎还很遥远。
人们的逻辑很简单:AI 既然会犯错,那么在智能体完成任务的长链条中,任何一个环节的失败,都会导致整个任务的崩盘。
然而,事实的演进并非如此。一篇新发表的论文解释了其中的奥秘。
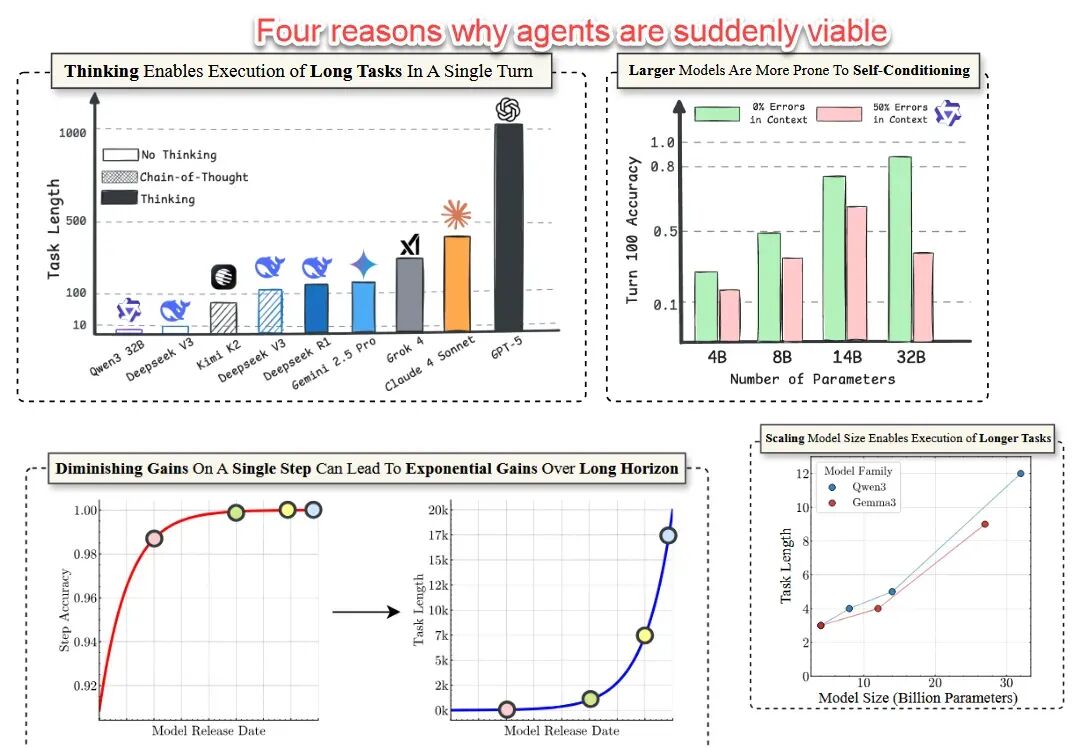
事实证明,我们过去对 AI 智能体的大部分假设都是错的。
模型的准确率哪怕只有微小的提升(而新模型的错误率已大幅降低),其能够完成的任务数量就会实现巨大的增长。
更关键的是,那些最先进的“思考”型大模型,实际上具备自我纠正的能力,它们不会轻易被一两个错误卡住。
这意味着,AI 智能体现在可以独立完成的步骤,比我们想象的要多得多,并且可以在极少人工干预的情况下,熟练运用各种工具(基本上就是你电脑能做的一切)。
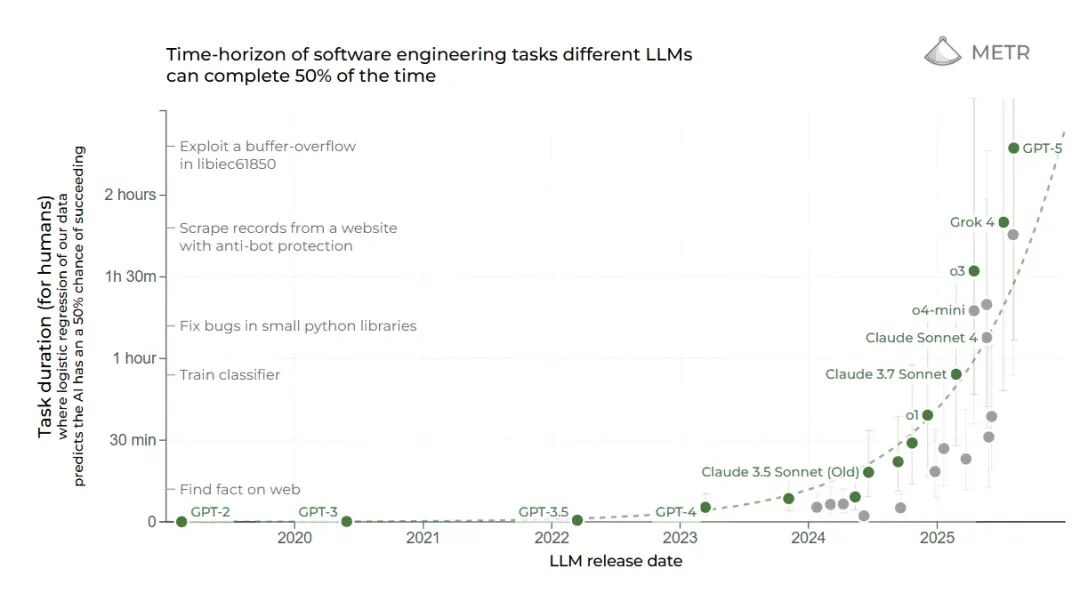
因此,METR 的一项测试就显得格外有说服力。在过去几年里,它是为数不多能够持续追踪从 GPT-3 到 GPT-5 全系列模型能力演进的指标之一。
这项测试衡量的,正是 AI 在保持至少 50% 准确率的前提下,能够独立完成的任务链的长度。
如下图所示,从 GPT-3 到 GPT-5,其能力在五年间呈现出稳定而陡峭的指数级增长,清晰地揭示了智能体工作的能力正在持续进化。
如何驾驭 AI 从事有价值的工作
然而,我们必须明确,智能体并不具备人类意义上真正的自主性。
当下,我们必须决定如何使用它们,而这个决定,将深刻地影响工作的未来。
一个显而易见的风险,是利用 AI 全面取代人类劳动力。不难预见,这在未来几年会成为一个巨大的社会议题,尤其对于那些缺乏想象力、只知削减成本的组织而言。
但还存在第二个同样巨大、也极易发生的风险:我们不假思索地,用智能体去做更多我们现在就在做的、可能本就毫无意义的工作。
为了让大家预演这场潜在的噩梦,我给 Claude 一份公司备忘录,让它做成一个 PowerPoint。
然后,我又让它从另一个角度,再做一个 PowerPoint。
接着,又一个。
直到我最终得到了 17 个不同的 PowerPoint。这 PowerPoint 也太多了。
如果我们不深入思考我们工作的目的,以及未来工作应有的样貌,我们所有人都将被 AI 生成的内容浪潮所淹没。
出路何在?OpenAI 的那篇论文给出了一个工作流建议:
专家可以先把任务交给 AI 做第一遍,然后审查结果。如果不够好,就再尝试几次,给出修正或更明确的指令。
如果几次尝试后仍不理想,专家就应亲自接手完成。
论文估算,如果遵循此流程,专家们能将工作效率提升 40%,成本降低 60%。更重要的是,人类将始终保持对 AI 的最终控制权。
智能体时代已经到来。它们能做真实的工作,虽然范围尚且有限,但其价值与日俱增。
但请记住,同样的技术,既可以在几分钟内复现一篇严谨的学术论文,也能在眨眼间生成 17 个根本没人需要的 PowerPoint。
通往这两种未来的岔路口,其选择权不在于 AI,而在于我们。
我们必须运用自己的智慧和判断力,去决定什么事值得做,而不仅仅是可以做。
只有这样,我们才能确保这些强大的工具,是让我们变得更强大,而不仅仅是更高产。
¹ 视研究领域而定,“复制”(replicating,可能涉及收集新数据)和“再现”(reproducing,可能涉及使用现有数据)之间存在区别。本文不深入探讨这些差异,在此案例中,AI 使用的是现有数据,并对其应用了新的统计方法。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!










