当机器人能像人类一样理解自然语言指令,还能预判环境变化、自主规避物理风险时,通用人工智能的落地似乎不再遥远。近日,清华大学计算机科学与技术系,北京信息科学与技术国家研究中心,复旦大学可信具身智能研究所联合发布《Embodied AI: From LLMs to World Models》。系统性梳理了具身智能的技术脉络,尤其聚焦大语言模型与世界模型的协同。
▍先搞懂什么是具身智能?它和普通AI 有啥不一样?
提起AI,很多人会想到只在数字世界对话的系统,或是图像识别这类被动处理数据的工具,这些都属于离身智能,它们不直接和物理世界互动。

而具身智能的核心是活在物理世界里:它需要像人一样,通过传感器主动感知环境,用认知系统处理经验,再用执行器做出动作,形成感知- 认知 - 互动的闭环。就像家里的扫地机器人能避开桌椅、规划清扫路径、调整刷子转速,就是一种简单的具身智能;更复杂的像救灾无人机自主避开障碍物、工业机械臂灵活抓取不同零件,都属于这一范畴。
该研究团队强调,具身智能的终极目标是接近人类级别的通用智能,它不是只解决单一任务,而是能在动态、不确定的物理世界里自主适应。举个例子,一个具身智能机器人,既该听懂把客厅的杯子放到厨房,又该知道杯子是易碎品,还能避开路上的宠物。
▍从单感官到多感官,具身智能如何突破局限?
早期的具身智能更像偏科生,有的只靠视觉导航,有的只靠语言做任务规划,这种单模态模式有明显短板。

单模态与多模态具身智能
纯视觉的机器人,在昏暗环境或动态场景里很容易迷路;纯语言控制的机器人,可能会因为没考虑物理规律提出离谱指令。

后来技术转向多模态融合:把视觉、语言、触觉、听觉等信息整合起来。就像现在的服务机器人,既能通过摄像头看到物体位置,又能通过语言理解用户需求,还能通过触觉感知物体重量,这种多模态能力让它能更灵活地处理复杂任务,能够轻轻拿起装满水的玻璃杯。
研究团队用一张图形象对比两者:单模态是感知、认知、互动各管一摊,多模态则是三者互相配合、信息互通。而推动这一转变的关键,正是大语言模型和世界模型的突破。
▍两大核心技术:大语言模型负责懂,世界模型负责做
具身智能要在物理世界生存,需要解决两个核心问题:理解任务和符合物理规律。而大语言模型和世界模型,恰好分别补上这两个短板。
1. 大语言模型:让机器人能听懂、会规划
大语言模型的核心作用是赋予语义智能,它让机器人从只能执行固定指令,升级为能理解模糊、复杂的人类语言,并拆解任务。
举个例子,你跟机器人说准备下午茶,大语言模型会先做语义推理,理解下午茶通常包括泡茶、拿点心、摆盘子;再做任务分解,把大目标拆成去厨房拿茶壶、接水、加热、去冰箱拿蛋糕、放到茶几等具体步骤。
该研究团队提到Google 的 SayCan 案例:它给大语言模型搭配真实世界动作库,避免大语言模型提出不切实际的动作,同时用价值函数验证每个动作的可行性。不过早期大语言模型的局限也很明显,它依赖固定的动作库,换个新机器人或新环境,就可能水土不服。

多模态大语言模型
后来出现的多模态大语言模型进一步突破这个问题。就像PaLM-E、RT-2 这些模型,能直接处理图像、语言、触觉等多模态信息,看到杯子、听到拿杯子、感知杯子重量,直接输出控制机械臂的动作序列,不用再依赖固定动作库。
2. 世界模型:让机器人懂物理、能预判
如果说大语言模型负责想明白要做什么,世界模型就负责想明白这么做会有什么后果,它相当于给机器人建立大脑里的物理世界模拟器。

具身世界模型发展路线
世界模型主要做两件事:
构建内部表征:把传感器收集的复杂信息压缩成结构化的内部地图,包含物体位置、物理属性、空间关系。这样机器人不用每次都重新观察世界,就能快速调用关键信息。
预测未来变化:根据物理规律预判动作的后果。比如机器人想推桌子,世界模型会先模拟推桌子时会不会把上面的杯子碰倒;救灾无人机想穿过峡谷,世界模型会预判气流会不会让机身不稳。这种预判能力,能帮机器人避开风险、提高效率。

具身智能关键技术模型
研究团队提到几种主流的世界模型架构:RSSM 擅长处理时序信息,适合做短期动作预测;JEPA 擅长提取语义特征,适合理解物体属性;Transformer-based 模型则擅长处理长序列信息,适合复杂环境的长期规划。
不过世界模型也有短板,它擅长模拟物理,但不擅长理解抽象语义。它能预判推杯子会让杯子移动,但可能听不懂把杯子送给妈妈里的妈妈是什么意思,这就需要和大语言模型配合。
▍大语言模型+ 世界模型,1+1>2 的协同架构
该研究团队的核心观点之一是,单独用大语言模型或世界模型,都无法实现高级具身智能;只有让两者结合,才能打通语义理解和物理执行的鸿沟。
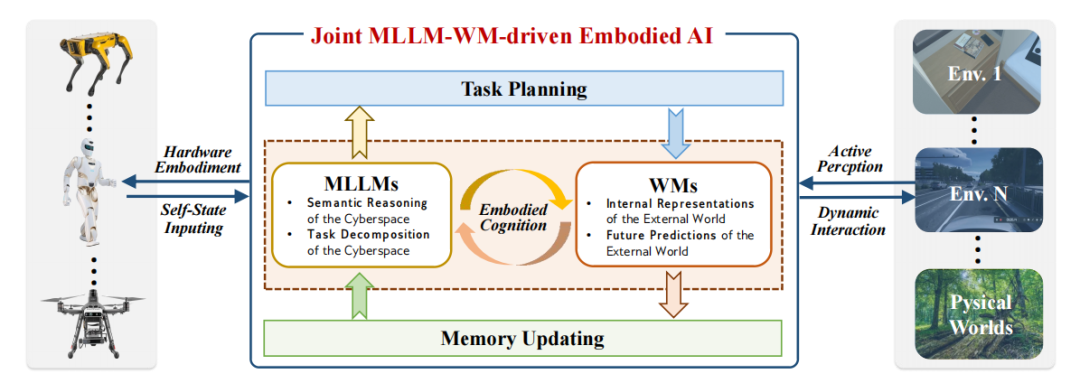
搭载多模态大语言模型与世界模型的具身智能
为什么这么说?看两者的互补性就知道,大语言模型懂语义,但不懂物理。它可能规划出让机械臂穿过桌子拿东西的步骤,却不知道这违反物理规律。世界模型的问题懂物理,但不懂语义。它能预判推桌子会碰倒杯子,却不知道为什么要推桌子。
而两者结合后,就能形成语义指导物理,物理约束语义的闭环,大语言模型先根据用户需求拆解任务,生成初步动作计划。世界模型验证这个计划是否符合物理规律,并预测每个动作的后果。如果计划有问题,世界模型反馈给大语言模型,大语言模型再调整计划。最终生成既符合用户需求、又符合物理规律的动作序列,让执行器落地。
该研究团队举了EvoAgent 的例子:这个具身智能体用大语言模型做任务规划和自我反思,用世界模型做环境建模和动作预测,结果能在不同环境里自主完成长期任务,全程不用人类干预。
简单说,大语言模型让机器人不糊涂,世界模型让机器人不莽撞,两者结合,才是具身智能走向实用的关键。
▍从家庭到工业,具身智能已经在改变什么?
以前的服务机器人,比如酒店送物机器人,只能走预设路线,遇到客人挡住就会卡壳;现在结合大语言模型和世界模型的服务机器人,能听懂把水送到302 房间,顺便问客人需不需要续杯,还能实时调整路线避开行人,甚至能根据客人的语气判断是否需要多送一瓶水。
研究团队提到的RT-2 机器人,能根据视觉信息自主识别杯子、桌子,再结合语言指令规划动作,哪怕杯子的位置和之前训练时不一样,也能灵活应对。
传统救灾无人机需要人类远程操控,在复杂环境里很容易失联,而具身智能无人机,能通过世界模型模拟环境风险,通过大语言模型理解救援指令,自主规划安全路径并传回受灾情况。
在工业领域,以前的机械臂,大多是专机专岗,换个生产线就不能用了,现在结合大语言模型和世界模型的机械臂,能通过大语言模型理解生产指令,通过世界模型预判抓取力度,不用重新编程就能切换任务。
▍具身智能还需要突破哪些难关?
现在的具身智能,还需要大量人类标注的数据或预训练,未来要实现自主进化,机器人能在新环境里自主探索,从失败中学习,甚至不用人类干预就能完成长期任务。
具身智能对硬件要求很高,机器人要实时处理多模态数据,还要快速做出反应,这需要更高效的芯片、更低延迟的传感器。未来的硬件优化,会更注重算法-硬件协同,针对大语言模型和世界模型的计算特点,设计专用加速器;或者通过模型压缩,让复杂的具身智能算法能在边缘设备上运行。
此外,单一机器人的能力有限,未来更需要群体具身智能,可以预见的是,未来场景下会出现多个救灾无人机协同搜索,多个工业机械臂配合组装,甚至机器人和人类协同完成任务。这需要解决群体认知问题,让机器人知道如何共享环境信息,如何分配任务,如何应对个别机器人故障。
具身智能机器人会直接和人类互动,安全性和可解释性至关重要。未来需要让机器人的动作可追溯,它为什么要这么做,万一出错了如何快速调整,还要确保它符合人类伦理,比如遇到危险时优先保护人类,而不是完成任务。
未来,当机器人能更自主、更安全、更灵活地在物理世界生存时,通用人工智能的梦想,或许就不再遥远。而大语言模型和世界模型的结合,正是这条路上最关键的一步。
论文地址:https://arxiv.org/pdf/2509.20021v1







![[读书分享]四足机器人常用步态概述](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-10-06/68e29641268ea.jpeg)


