
题目:Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory
论文地址:https://arxiv.org/pdf/2508.09736
主页:https://m3-agent.github.io

创新点
与传统智能体不同,M3-Agent 能够实时处理视觉和听觉输入,构建和更新其长期记忆。这种长期记忆不仅包括事件记忆(episodic memory),还发展出语义记忆(semantic memory),使其能够随着时间积累世界知识。
现有的长视频问答基准主要关注视觉理解,而 M3-Bench 弥补了这一空白,设计了能够评估更高层次认知能力的问题,这些能力对于现实世界中的智能体至关重要,例如理解人类、提取一般知识以及进行跨模态推理等。
方法
本文提出了一种具备长期记忆的多模态智能体框架 M3-Agent。该框架通过持续处理实时的视觉和听觉输入来构建和更新长期记忆,记忆分为事件记忆和语义记忆,并以实体为中心的多模态图结构进行组织,以支持更深入和一致的环境理解。同时,M3-Agent 在接收指令后,能够通过迭代推理和检索长期记忆中的相关信息来执行任务,其控制流程利用强化学习进行优化。此外,为了评估 M3-Agent 的长期记忆和推理能力,本文还开发了 M3-Bench 基准测试,包含从机器人视角和网络来源的长视频及相应的问题答案对,用于测试智能体在人类理解、知识提取和跨模态推理等方面的能力。
M3-Agent 架构图

本图清晰地展示了 M3-Agent 如何通过记忆和控制两个过程协同工作,实现对复杂多模态环境的感知、理解和推理。记忆过程为智能体提供了丰富的背景知识和经验,而控制过程则利用这些知识来完成具体的任务指令,两者相辅相成,共同推动了多模态智能体的发展。
M3-Bench 示例

本图通过具体的示例展示了 M3-Bench 数据集中的视频内容以及相应的问题和答案。这些示例对于理解 M3-Bench 如何评估多模态智能体的长期记忆和推理能力至关重要。M3-Bench-robot 示例。这部分展示了从机器人视角拍摄的真实世界视频。这些视频模拟了机器人在实际环境中可能接收到的感知输入,例如在家庭、办公室或健身房等场景中的交互。示例中的问题和答案设计得非常巧妙,旨在测试智能体对人类行为、偏好以及环境变化的理解能力。M3-Bench-web 示例。与 M3-Bench-robot 不同,这部分的视频是从网络上收集的,涵盖了更广泛的内容和场景。这些视频可能包括各种类型的节目,如纪录片、访谈、日常生活记录等。相应的问题也更加多样化,不仅涉及人类理解,还包括一般知识提取和跨模态推理等方面。
M3-Bench 统计概览
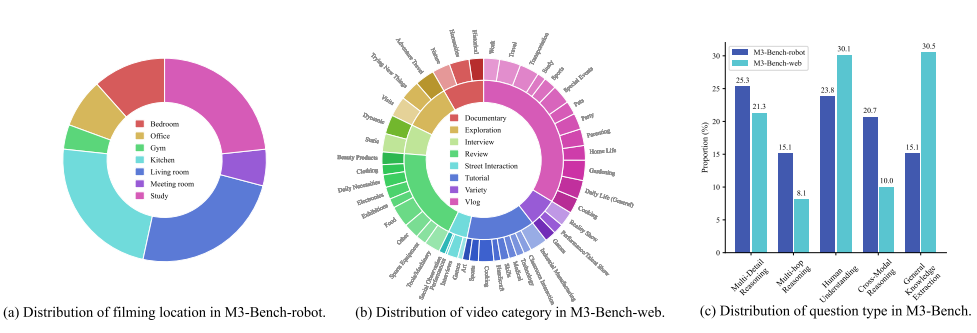
本图提供了 M3-Bench 数据集的详细统计信息,这些信息对于了解数据集的构成和特点非常关键。M3-Bench-robot 拍摄地点分布。这部分展示了 M3-Bench-robot 中视频的拍摄地点分布情况。从图中可以看出,视频主要来自家庭、办公室、健身房等实际场景。这种分布反映了机器人在现实世界中可能遇到的典型环境,使得 M3-Bench-robot 能够有效地评估智能体在这些实际场景中的性能。M3-Bench-web 视频类别分布。图中还展示了 M3-Bench-web 中视频的类别分布。这些类别涵盖了日常生活、教育、娱乐、新闻等多个方面。这种广泛的类别分布意味着 M3-Bench-web 能够测试智能体在处理不同类型内容时的能力。通过详细的统计信息展示了 M3-Bench 数据集的构成和特点。这些信息不仅有助于我们了解数据集的多样性和丰富性,还为研究者提供了一个全面评估多模态智能体性能的基准。
实验

本表展示了 M3-Agent 与多种基线方法在 M3-Bench-robot、M3-Bench-web 和 VideoMME-long 三个基准测试上的性能对比。在 M3-Bench-robot 上,M3-Agent 的准确率为 30.7%,比最强基线 MA-LMM(25.6%)高出 5.1 个百分点;在 M3-Bench-web 上,M3-Agent 的准确率为 48.9%,比最强基线 Gemini-GPT4o-Hybrid(35.9%)高出 13.0 个百分点;在 VideoMME-long 上,M3-Agent 的准确率为 61.8%,比 Gemini-GPT4o-Hybrid(37.6%)高出 24.2 个百分点。这表明 M3-Agent 在长期记忆构建和推理方面优于其他方法。在不同问题类型中,M3-Agent 在人类理解和跨模态推理等关键能力上表现突出。例如,在 M3-Bench-robot 的人类理解问题上,M3-Agent 比 MA-LMM 高出 4.2 个百分点;在 M3-Bench-web 的跨模态推理问题上,比 Gemini-GPT4o-Hybrid 高出 6.7 个百分点。这些结果证明了 M3-Agent 在处理复杂多模态任务时的优越性。
-- END --

关注“学姐带你玩AI”公众号,回复“agent25”
领取117篇agent论文代码合集+321个实战项目











