大模型开源生态有了新变化。
作者丨齐铖湧
编辑丨陈彩娴

刚刚过去的国庆,各行各业进入放假模式,但大模型行业却一刻也没闲着。
过去的半个月,国内外大模型的头部团队有十余款重磅产品发布,但每个团队的产品侧重不同。
其中,九月下旬,阿里发布以 Qwen3-Max 为代表的全家桶产品,大秀了一把肌肉;九月末,DeepSeek 和 Anthropic 瞄准真实编程场景,先后发布了 DeepSeek V3.2-Exp 和 Claude Sonnet 4.5,此外,智谱也拿出 GLM-4.6,目标冲击国内最强代码模型。
有人全盘布局,也有人专攻精尖,在大模型领域竞争驶向深水区后,各个公司战略路线出现了分野。
10 月 9 日凌晨,蚂蚁百灵大模型团队奇袭般官宣了一款自家最新语言大模型 Ling-1T,参数量达到 1000B(即 1万亿参数)。然而,就在十天前,百灵团队才将自研 Ring-1T-preview 大模型开源。
短短十天内,发布并开源两款万亿参数模型,如此密集的产品发布让蚂蚁百灵大模型成为了行业热议对象。
与此同时,这样毫无保留的开源动作,也让业界猜测:蚂蚁到底意图何在?

01
据了解,蚂蚁集团研发的基础大模型取名“百灵”,寓意“百试百灵”,也蕴含科技普惠之意,和阿里一样,蚂蚁也是独立团队独立研发,Ling-1T 和 Ring-1T-preview 分别是蚂蚁百灵团队研发的非思考模型和思考模型。
过去半年时间里,蚂蚁一直在对百灵大模型进行迭代优化,并且自上而下形成了三条技术探索路线:
一条是以 MoE 架构为基础的非思考模型 Ling-Series,另一条是思考模型 Ring-Series,第三条是原生全模态大模型 Ming-Series 。
如今,蚂蚁百灵团队在 Ling 和 Ring 两款模型路线上都已经将参数量扩大到万亿参数。
万亿参数,几乎等同于人类大脑神经元数量,相当于让 AI 拥有等同于人脑的处理能力,但万亿参数非常难训。目前,国内能达到万亿参数规模的大模型也是凤毛麟角。
除了刚才提到的百灵大模型 Ling-1T 和 Ring-1T-preview ,目前国内公开资料可查的万亿参数大模型只有 Kimi K2、阿里 Qwen3-Max 和腾讯混元大模型等少数几个模型,可见大模型领域“万亿俱乐部”的门槛之高。
虽然今年以来盛行“数据撞墙论”和“预训练终结”的观点,但越来越多科学家也形成了一个新的共识:更大的参数,更多的数据,仍然能带来持续的性能提升。
阿里的算法负责人林俊旸公开表态:Scaling Law 仍然没见顶,训练数据的增加,参数规模的扩大,都还能看到模型性能的提升。
杨植麟的Kimi 团队更是克服万难闷头苦干,终于在两个月前,拿出了万亿参数的旗舰模型K2。通义千问团队直接提出了“大就是好”的暴论,并且让 Qwen3 坚定不移地沿着“Just Scale it”的扩展路径前进。
由此可见,大家都还在朝着“探索智能上限”出发。

02
据了解,过去一年里,平均7天就有一款高性能大模型诞生。可以说,国内不缺大模型。
但在参数和效率之间,能做到完美平衡的大模型却不多。
就拿万亿参数模型来说,模型变大了,往往会牺牲推理速度,推理速度上去了,准确率又很难达到。业界知名的旗舰款大参数模型,都能在推理能力和思考效率上做到很不错的平衡。
这个平衡点,被称之为帕累托最优,我们经常用多维基准测试的分数来量化对比。这次蚂蚁发布的 Ling-1T 在公开的对比榜单中,表现让人非常意外。
下图是 Ling-1T 在部分权威基准评测的表现,红色加粗代表 Ling-1T 的得分获得 Top1,黑色加粗下划线表示 Top2:

我们重点关注的编程与数学推理( Coding & Math )两个维度上,Ling-1T 表现非常亮眼,甚至多个得分超过 DeepSeek。在知识理解方面,Ling-1T 也比Kimi、GPT-5 主干模型等的得分,高出几分。
这意味着,Ling-1T 的深度思考能力和泛化能力,以及逻辑推理能力,都非常全面。因此,Ling-1T 会非常擅长从事代码生成、软件开发、竞赛数学、专业数学、逻辑推理等场景。
但对于万亿参数模型来说,除了综合性能,还需要考虑一个问题:推理正确率。这就需要引入竞赛数学榜单 AIME 25 竞赛数学榜单 AIME 25 的挑战,Ling-1T 的成绩如下:

Ling-1T 在 AIME 25 测试中,与 DeepSeek-V3.1-Terminus、Kimi-K2-Instruct-0905 (开源)以及 GPT-5-main、Gemini-2.5-Pro (闭源)这些旗舰模型对比,展示出更短的思考路径和更高的推理准确率,能做到支持 128K 长文本窗口处理能力,每个 token 做到约 50B 参数的激活量。
这样的成绩,源自蚂蚁百灵团队长时间的积累与创新。
依托于团队储备的二十万亿 Token 高质量文本语料训练,Ling-1T 吃进了大量优质知识。在预训练阶段, Ling-1T 的训练团队让由 Ling Scaling Laws 自我设置关键超参,简单地说,就是让大模型自我优化。
同时在强化训练阶段,加入了百灵团队原创的 LPO 策略优化算法,让模型回答得更对。
此外,团队还额外提出了“语法-功能-美学”的混合奖励机制,提高模型审美。下面这张是 Ling-1T 工程师绘制的模型架构图:

不止是刚发布的 Ling-1T 和9月30日发布的 Ring-1T-preview ,蚂蚁实际上已经形成了完整的百灵大模型家族。
从尺寸上,包含从160亿总参数到1万亿总参数的大语言模型产品矩阵;从模态上,包含了能看能听能说能画的,从理解到生成能统一的大模型;
从场景上,也形成了包括手机上可以运行的 Ling-mini,还有能在中小企业服务器上部署的 Ling-flash,以及云端可调用的 Ling-1T。

这些模型,在过去一段时间,无论是社区榜单还是实际使用上,都得到了很多有效回应。
蚂蚁百灵团队开发的全模态模型 Ming-lite-omni v1.5 甚至在 Hugging Face 模型趋势榜(any to any)排到过第一的位置。
Ring-1T-preview 发布完的第二天,就冲上了 Hugging Face 模型榜 Text Generation 总榜排名第三,排名第四的也是9月 Ling 团队发布的混合架构思考模型 Ring-flash-linear-2.0 。

图灵奖得主 Yann LeCun(杨立昆)甚至点赞并评论“Impressive”(了不起),了解这位特立独行大佬的网友表示:“ LeCun 愿意给 LLM(大模型)说句好话不容易”。
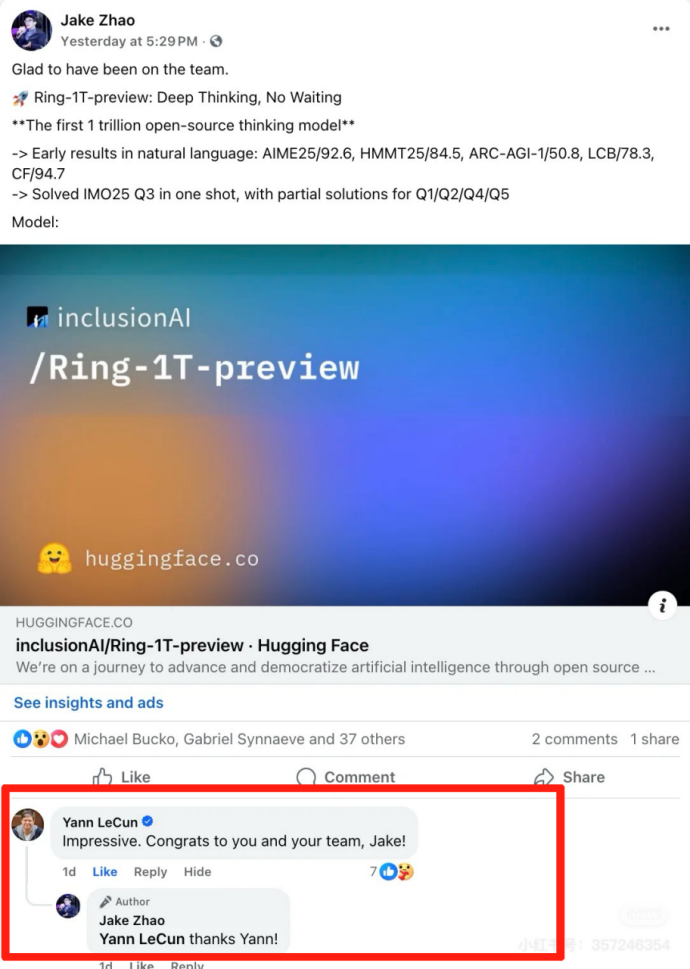
一位苹果工程师量化完跑起来模型,评价蚂蚁百灵模型的性能“Getting closer to GPT-5 at home”(在本地部署上的性能接近 GPT-5)。

这些技术从业者和开发者们的真实声音,给予了百灵模型非常正向的反馈。

03
百灵团队,如此快速地跻身“万亿参数俱乐部”,背后跟蚂蚁的战略动作分不开。作为一家成立了20年的互联网公司”,蚂蚁在 AI 领域的投入一直是非常巨大的。
去年蚂蚁20周年时候,蚂蚁集团董事长井贤栋宣布:未来20年,蚂蚁要做一家科技驱动、创新驱动的公司。蚂蚁集团还提出了 AI First 战略,并将其与“支付宝双飞轮”和“加速全球化”一齐,并称为蚂蚁集团的三大战略。
而 Ling-1T 和 Ring-1T-preview 的出现,则是蚂蚁 AI First 战略持续加速的表现。
不选择闭源道路,而是选择了开源,足以证明,蚂蚁想干一件更长远的事:
通过技术开放的方式,不断迭代技术,构建一个真正开放的 AGI 生态。
根据 AI 科技评论了解,目前“万亿参数俱乐部”里能做到完全开源的,只有蚂蚁百灵的 Ling-1T 和 Ring-1T-preview ,以及 Kimi 的 K2。
在大模型参数军备竞赛愈演愈烈的 2025 年,投入如此巨大之后,蚂蚁选择直接开源,看似让人费解。
但如果了解大模型开源背后的意图,就会明白,当 Ling-1T 和 Ring-1T-preview 这样万亿参数模型,公布了背后的训练数据、算法、模型,开发者可以直接利用这些“庞然大物”作为起点,快速构建复杂的应用程序,无需关心底层模型的训练。一个“使用-反馈-迭代”的正向循环,将极大推动技术共建,加快智能涌现。
这条"技术平权化"的道路,我们并不陌生。今年年初,DeepSeek 的横空出世,已经为众多中国大模型头部玩家们指明了道路。
今年接任蚂蚁集团 CEO 的韩歆毅,曾在内部技术日上表达了蚂蚁 AI 的主张:
“大家说(蚂蚁)聚焦 AI 应用,还要不要做基础大模型,年初讨论的时候我们答案非常坚决,一定要,因为如果基于 AI 做服务和应用,就像训练一个人去做所有的事,追求智能上限,会让这个人更加聪明,能够做更多、更好的服务。我们很坚定去探索 AGI 、探索智能上限。”
蚂蚁还专门成立了 InclusionAI 开源组织,建设了大模型全栈技术,包含强化学习推理框架 AReaL、多智能体框架 AWorld 等,这些技术也已经通过开源、开放合作的形式与行业共享共建,让创作者可以交流共创。
能看得出来,相比于登台唱戏,蚂蚁更加愿意把戏台搭好,AI 的基础设施铺设好,才能吸引更多的人来共建,真正迈向 AGI 。



未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。
未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。