▲KAT-Dev-72B-Exp开源项目
Hugging Face项目地址:
https://huggingface.co/Kwaipilot/KAT-Dev-72B-Exp
KAT-Coder免费体验链接:
在传统的大模型Agent训练中,由于模型在执行任务时会产生包含分支与回溯的树状token轨迹,业界普遍采用拆分为多条线性序列的简化训练方案。然而,这种方法忽略了轨迹之间的共享结构,容易造成计算冗余。
Kwaipilot的工程团队重新设计了训练引擎与注意力内核(attention kernel),并通过树形梯度修复权重机制,将共享前缀的正反向计算合并,实现了在树形轨迹上的高效训练。
实测数据显示,这一技术方案令整体训练速度平均提升至原来的2.5倍,大幅提高了强化学习训练阶段的吞吐效率。
强化学习的优化核心在于策略梯度,而优势函数(Advantage Function)直接决定了每个样本在参数更新中的影响力。传统的GRPO算法仅基于组内收益计算优势值,忽视了策略的探索性,容易使模型过早收敛到局部最优。
针对这一问题,Kwaipilot团队提出了基于熵的优势缩放方法。该方法在每个rollout样本中引入策略熵(Policy Entropy)作为权重调节因子,对高熵样本(探索性强)放大优势,对低熵样本(确定性强)适度抑制。
通过这一机制,模型在保持收敛效率的同时,显著增强了探索能力,实现了更优的探索—利用平衡。

▲数据平面的序列图(图源:Kwaipilot)
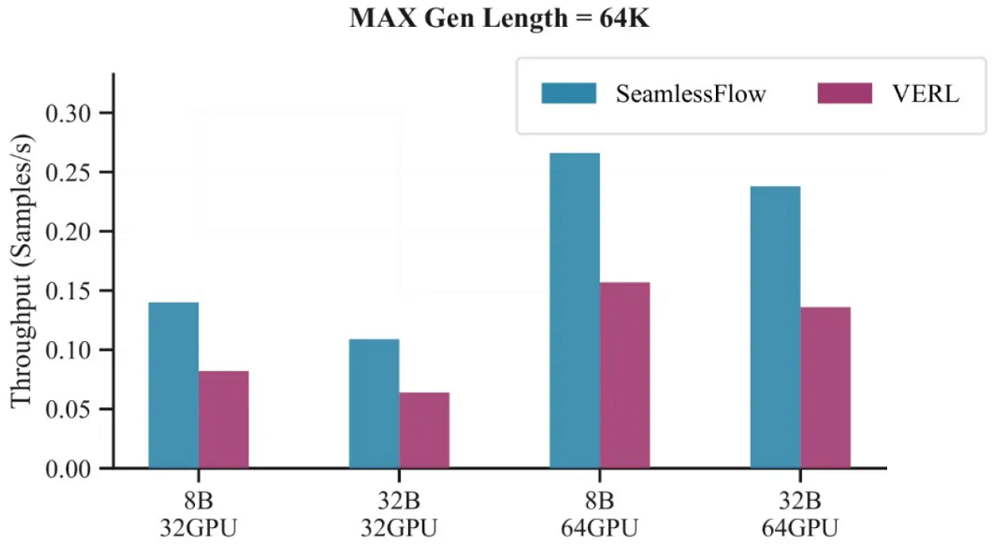
SeamlessFlow的另一关键创新是标签驱动的资源调度范式,通过为计算资源赋予如“训练”或“推理”等能力标签,统一了集中式(Colocated)与分布式架构(Disaggregated)的资源管理模式。
该系统支持时空复用机制,使得具备多标签的机器可根据任务需求动态切换角色,从而将GPU闲置率降至5%以下,彻底缓解了传统架构中的流水线空闲问题。
在实际工业场景的验证中,SeamlessFlow在多项任务中实现了显著的吞吐量提升与扩展性优势。