点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!
大家好,我们是来自北京交通大学、南洋理工大学、香港科技大学和重庆邮电大学的研究者。今天想和大家分享我们最新的工作 Jasmine,这是第一个成功将Stable Diffusion(SD)引入自监督单目深度估计(SSMDE)的框架。
项目主页 (Project Page): https://wangjiyuan9.github.io/Jasmine/ 论文 (Paper): https://arxiv.org/abs/2503.15905v2 视频 (B站): https://www.bilibili.com/video/BV1x8xszFEos 代码: https://github.com/wangjiyuan9/Jasmine

无需任何高精度深度监督,Jasmine 凭借其零样本泛化能力,即可在各种复杂场景中取得惊人般精细、准确的深度估计结果。
TL;DR
我们提出 Jasmine,首个把 Stable Diffusion(SD)视觉先验“无GT深度监督”地接入自监督单目深度估计(SSMDE)的框架。核心是两个简单但有效的组件:Mix-batch Image Reconstruction(MIR)与 Scale-Shift GRU(SSG)。 传统自监督容易被重投影伪影“带偏”,预测发糊、细节丢失;而SD先验如果被噪声梯度污染,又会在早期训练就“碎”。Jasmine在不引入高精深度标注的前提下,既守住SD的细节先验,又保证自监督几何一致性。
一、引子:自监督遇到的“老大难”
单目深度估计是计算机视觉的基石。相比于需要昂贵LiDAR标注的监督方法,自监督方法(SSMDE)仅从视频序列中学习,潜力无限。但它有个致命弱点:依赖的重投影损失(Reprojection Loss)在处理遮挡、弱纹理、光照变化时会产生错误的监督信号,导致预测结果模糊、细节丢失、边缘退化。

近年来,Stable Diffusion 等扩散大模型展示了惊人的视觉先验能力,能够生成无比清晰、细节丰富的图像。Marigold、Lotus等工作已经证明,通过有监督微调,SD能大幅提升深度估计的细节和泛化性。
那么,一个自然而然的问题来了:我们能否将SD的强大先愈能力,注入到无需标注的自监督框架中,来解决SSMDE的顽疾?
答案是:极具挑战性!
直接用自监督的“脏”监督信号(充满噪声和伪影的重投影损失)去微调SD,只会迅速污染和破坏SD宝贵的预训练先验,导致模型在训练早期就崩溃。
二、破局:Jasmine如何“驯服”扩散模型?
为了解决这个核心矛盾,我们提出了Jasmine框架,包含两大创新:
1. 任务代理:混合批次图像重建 (Mix-batch Image Reconstruction, MIR)
既然重投影损失会“污染”SD,那我们就把“图像自身”当作“无噪声的高精监督替身”!
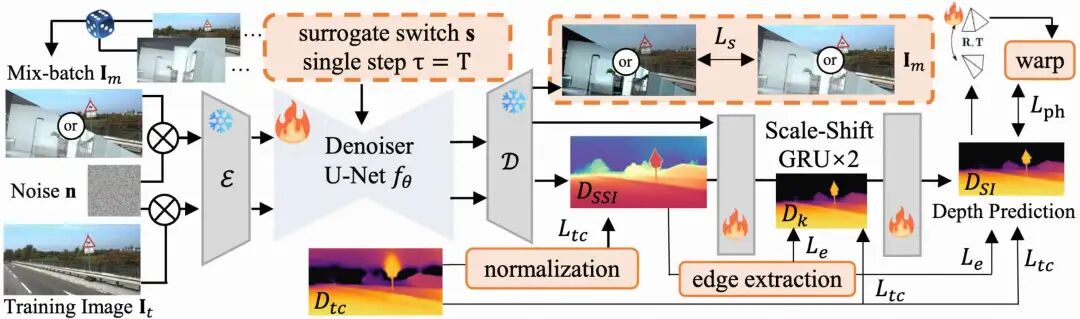
我们的核心思想是:让SD模型在每个训练批次中“一心二用”。它不仅要预测深度图,还要交替地去重建输入图像。
预测深度时:使用自监督的重投影损失,学习几何结构。 重建图像时:我们用图像本身作为“完美”的监督信号。这就像一个锚点,牢牢锁住SD的视觉先验,防止它被重投影损失的噪声带偏。
具体来说,我们在每个batch里混合真实KITTI帧与高质量图像,让SD在“重建图像”的旁路任务上守住自身先验的清晰纹理;与此同时,主任务仍用自监督重投影优化几何一致性。通过这种方式,我们巧妙地将结构学习和细节保持解耦,成功在自监督框架下保住了SD的“金身不坏”!
MIR的拓展性
本文验证了MIR不需要深度或语义标注,数据规模也不苛刻(<1k也有效),
MIR 是一种非常有前景的训练范式,它对任何密集预测任务均没有固有限制(赶快来尝试语义分割,法线、光流估计等缺少高质量标注的任务吧),只需要拿高质量图像来作锚点即可!
2. 分布对齐:尺度-位移门控循环单元 (Scale-Shift GRU, SSG)
SD系方法和自监督几何优化的分布天然错位:
SD-based方法天然预测的是尺度-位移不变(SSI)的深度,可以理解为 y = a*x + b。自监督方法由于几何约束,只能预测尺度不变(SI)的深度,即 y = a*x。
这个分布上的鸿沟(多了一个shift b)使得两者无法直接融合。为此,我们设计了 SSG 模块。
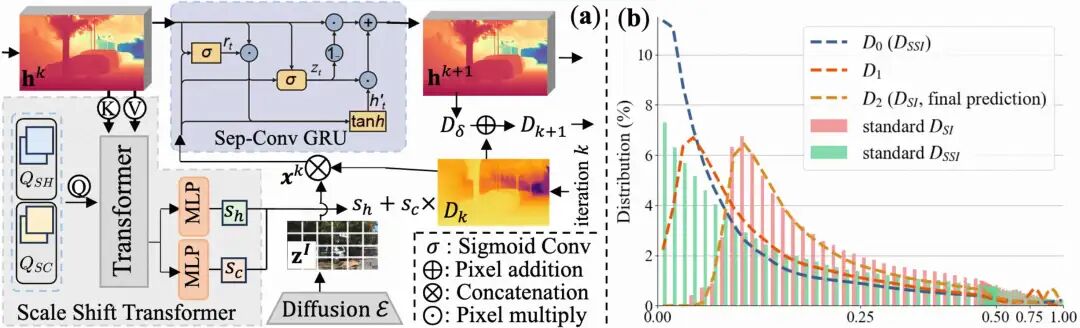
具体来说,我们在GRU里放入一个Scale-Shift Transformer(SST),显式迭代估计scale/shift,使SSI→SI对齐;同时,GRU的reset gate在反向传播时相当于“梯度滤波器”,其内部的门控机制能有效阻挡重投影损失中的异常梯度,保护了从SD输出的精细纹理细节,最终让我们的结果在符合几何约束的同时,保留了惊人的细节。上图的(b)展示了两次GRU迭代是的确完成了两分布的迁移。
三、效果展示:SOTA + 超强泛化 + 惊人细节
Talk is cheap, show me the results.
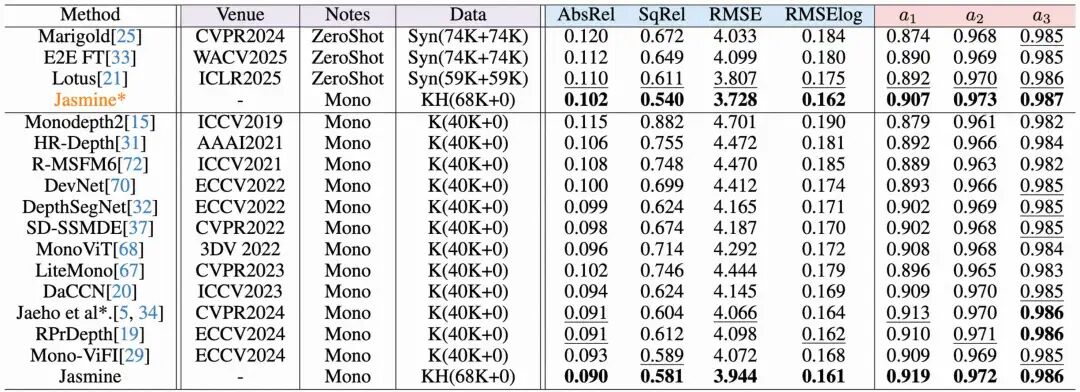
1. KITTI霸榜,刷新SOTA!
在竞争激烈的KITTI benchmark上,Jasmine在所有指标上均超越了现有的自监督方法,取得了新的SoTA!
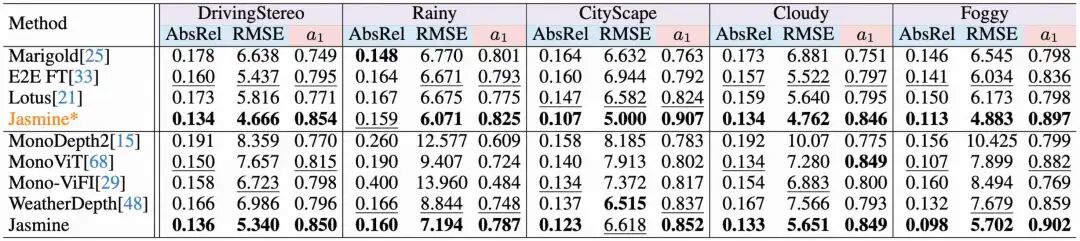
2. 恐怖的零样本泛化能力
我们只在KITTI上训练,然后直接拿到CityScape、DrivingStereo等各种新场景下测试,结果令人惊艳。Jasmine不仅远超其他自监督方法,甚至在多个场景下超越了过往微调Stable Diffusion的监督模型!
3.无与伦比的细节表现
得益于SD的先验和我们的精心设计,Jasmine能够捕捉到前所未有的细节,比如水面倒影、纤细的栏杆、人物轮廓等。这些在以往的自监督方法中是完全无法想象的:
4.给社区一个公平
我们还专门分析了“对齐策略对评测的影响”(LSQ vs Median)。In-domain更适合Median(避免少数离群点拖累),Out-of-domain更适合LSQ(更能适应分布偏移)。这解释了相同模型在两类评估下的指标差异,也给社区一个更公平的横向比较方法论。
四、展望:我们打开了什么新大门?(欢迎大家来卷!)
Jasmine作为第一个成功的自监督SD微调框架,仅仅是一个开始。我们认为这为社区开辟了一个激动人心的新范式:
我们提出的MIR无监督微调范式是通用的!它不仅限于深度估计。任何需要从缺少高质量标签且需要学习的图像预测的任务,比如语义分割,法线估计,光流估计,图像去噪 ,图像超分,图像着色,图像修复,风格迁移,材料属性估计等,都可以尝试用这种方式来引入大模型的先验,提升细节和鲁棒性。
这个坑我们已经挖好了,并且证明了它的价值。我们非常期待看到社区的各位大佬基于Jasmine做出更多酷炫的工作!
最后,如果您觉得我们的工作有启发,欢迎引用、点赞、关注我们的项目!
3D视觉1V1论文辅导来啦!
3D视觉学习圈子
星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001