机器人大讲堂获悉,10月11日,枢途科技正式对外披露已完成数千万元天使轮融资,本轮由东方富海及兼固资本联合领投,值得一提的是,2024年枢途科技就拿到过数百万融资,投资方为奇绩创坛。
众所周知,数据是解决具身智能落地的最后一公里,而具身智能数据却存在采集成本高、规模化数量少、场景多样性稀缺等问题。目前行业内主流的解决方案是采用人工数据采集方式获取高质量训练数据,仅2025上半年,上海、北京及合肥等地就已构建起多个大型数采中心。

其中上海张江机器人谷,是全球唯二、全国唯一的规模化机器人数采中心,累计投放近百台数采机器人;北京石景山首钢园人形机器人数据训练中心,累计部署超过 108 台机器人;而正在构建的合肥市具身智能机器人数据采集预训练场预计年底将实现超 100 台机器人同时在30个以上细分场景开展数据采集和协同作业。
目前单台数采设备从几万到十几万不等,虽然行业内有部分研究机构推出低成本硬件数据采集方案,实现对人类动作的 1:1复刻,但在通用性与数据采集效率上,依然无法满足现有的行业发展需要。
因此谁能解决“低成本、高通用、多模态”具身智能数据问题,谁便拿到具身智能赛道的话语权,率先成为产业领跑者。
▍特斯拉Optimus放弃动捕与遥操作 深挖互联网视频数据
今年5月,特斯拉工程主管Milan Kovac通过X平台宣布,Optimus将正式告别传统的动作捕捉和远程操控训练方式,全面转向基于视频数据的“纯视觉”AI训练模式。
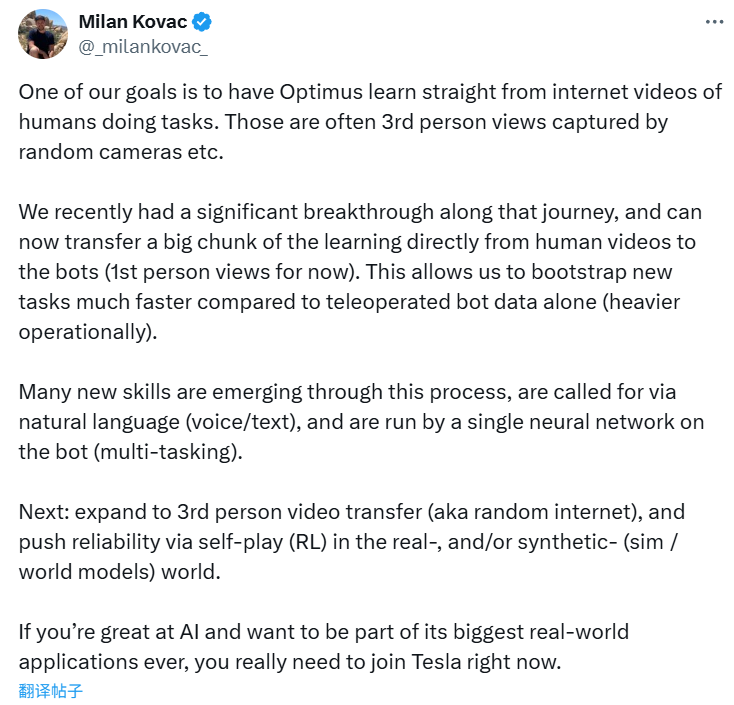
Milan Kovac强调:“我们的目标之一是让Optimus直接从人类执行任务的互联网视频中学习。这些视频通常是随机摄像头捕捉到的第三人称视角。”

值得一提的是,特斯拉并不是唯一看到视频数据潜力的公司,国外的Skild AI提出了利用视频数据解决数据瓶颈的方法;国内的逐际动力、千寻智能、BeingBeyond都提出采用视频数据来提升机器人的智能水平,具身智能产业正在迅速达成一个共识,即传统依赖遥操作和动捕技术的数据采集路径,因其高成本和难以规模化的特性,已成为制约具身智能发展的关键瓶颈。在此背景下,利用成本近乎为零、规模海量的互联网视频资源,被视为突破数据困境的理想选择。
▍2D视频的数据价值正在被重新定义
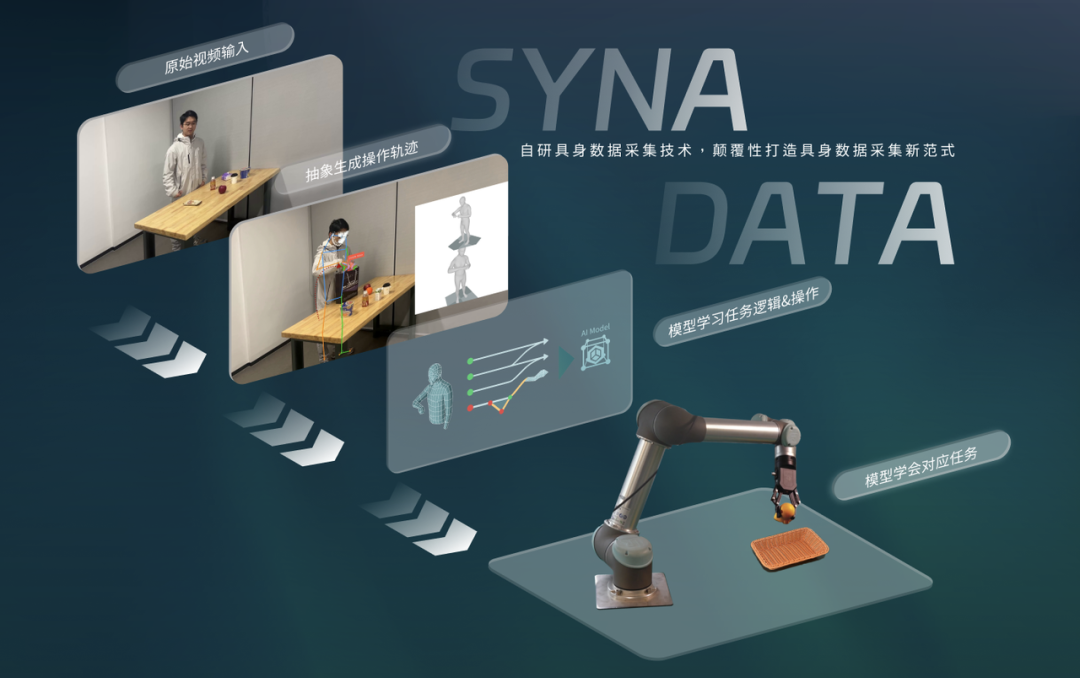
然而,从“看到潜力”到“实现应用”之间存在巨大的技术鸿沟。如何将非结构化的2D视频,精准转化为机器人模型可理解、可执行的多模态具身训练数据,是横亘在前的核心挑战。为了系统性地解决这一“数据转化”难题,枢途科技于今年7月正式发布了全球首个从互联网RGB视频提取具身训练数据的全链路解决方案——SynaData系统。
SynaData数据管线重磅发布:颠覆行业具身数据采集方式
该系统实现了视频数据升维、跨域retargeting等技术突破,批量化从视频中提取多模态具身通用训练数据,将具身数据的综合采集成本降为行业平均水平的千分之五。
互联网数据并非仅提供内容承载,人类观看视频时能感知深度与物体交互关系,而这些高维信息本就内嵌于视频中,只是此前未被有效提取。SynaData系统的核心突破就在于将蕴藏空间、物理交互信息的“数据金矿”挖掘出来,重新定义2D视频的数据价值。
从技术实现来看,SynaData 系统的视频升维逻辑可分为三个关键环节。

团队首先利用高精度三维重建技术,将2D视频转化为带深度信息的 3D 内容,例如人手运动轨迹以及物体接触点,重建平均精度达到5毫米以下,值得一提的是这个过程不仅能够还原可见画面,还能测算被遮挡部分,确保符合物理规律。

其次SynaData系统会进行关键模态提取,区别于行业内多数聚焦 “内容重建” 的技术,SynaData系统会从升维后的视频数据中,精准筛选并提取出具身模型真正需要的核心信息,如毫米级的手-物交互轨迹、物体网格模型以及动力学参数。

目前枢途SynaData系统通过视频采集到的多模态具身数据已实现第三方具身模型的验证,完成跨本体的任务实测,在清华RDT、PI π0等开源具身模型上验证了SynaData视频具身数据的杰出训练效果。

▍SynaData系统将有望打通全球最大规模具身智能数据集方案
传统遥操作模式需搭建专用工厂,不仅前期投入大,也使得单条数据的采集成本居高不下,而SynaData系统,只需输入目标视频,一周内即可生成批量具身数据,且全程无需承担仿真环境搭建、物理参数测算等额外开销。SynaData系统的愿景是能够让具身智能数据最终走向 “低成本、高通用、多模态”方向,并通过开源数据集,提供给第三方机构,而这也正是具身智能行业所稀缺的关键环节。

据枢途科技表示,当前SynaData系统已累计处理数千小时视频数据,这些数据当中,80%的数据能够直接转化成具身智能数据进行模型训练使用。仅有20%复杂场景需要进行人工微调,例如软质物体形变还原这类难度较高的场景,输出数据所需要的时间会相对较长,但整体效率仍然远高于行业平均水平。
具身智能数据孤岛这个问题由来已久,单一设备采集的数据智能服务于该设备,这也使得具身智能数据在模型训练到商业验证当中出现技术断层,一定程度上限制机器人规模化部署。
SynaData系统则构建了“UMI raw data”中间态,通过 retargeting(重定向)技术,可将数据映射到不同人形机器人、机械臂(包括五指灵巧手、二指夹爪),实现数据标准化与规模化复用。并且未来这套技术将支持100种以上不同形态的机器人本体,包括人形机器人、多类型灵巧手、协作机械臂,AGV、AMR等各类结构。
这一中间态更像是为模型厂商提供“通用素材库”,使得厂商能够更加专注于数据标注与模型设计,无需重复投入数据采集。
目前,针对于2D视频转化3D具身智能训练数据的研究,国际头部如特斯拉、Skild AI、Deepak Pathak、Pieter Abbeel等研究团队均在这个领域深耕。国内方面,北大卢宗青团队与智在无界联合开发HAT模型通过视觉表征对齐实现跨形态动作迁移。清华大学朱军团队与生数科技也在联合开发,基于3D Gaussian Splatting技术实现2D视频到3D具身智能数据的转换。但需要注意的是,目前国内外所有研究机构无一例外均服务于自身模型,并未对外开放数据,并且规模量级较小,难以达到通用标准。
而枢途科技SynaData系统打造的具身智能数据则面向全行业开放,目前已适配多个开源 VLA 模型,包括清华RDT、PIπ0、智元UniVLA、EquiBot等。

在清华RDT模型测试当中,通过SynaData系统,仅输入20余条人类抓握带杯子杯把的视频数据,模型即可实现一定成功率的抓握动作,在通用性与泛化性方面表现出色,也让我们看到了具身智能scaling law的突破。
▍具身数据采集未来三种技术路线并驾齐驱
SynaData虽然在前期验证过程当中取得了出色的成绩,但就整体行业来看,短期内具身智能数据领域不会形成单一路径技术垄断,遥操作数据、合成数据、SynaData的视频提取数据将各展所长,形成多元化格局。
枢途科技CTO林啸表示,SynaData 的核心定位是 “具身数据基础设施”,为基座 VLA 模型提供大规模、多模态的预训练数据,帮助模型先掌握物体识别、抓取决策等基础能力。
在具体规划上,枢途科技计划于今年第四季度发布首个基于真实场景视频的多模态具身开源数据集。林啸透露,团队初步目标为“万条级”,若进展顺利将冲击“10万条级”,而当前行业内几万条即算“大型数据集”的现状将得到彻底超越。在重建平均精度上,开源数据集将由目前5毫米以下提升至2毫米以下,远超行业误差水平。此外,该数据集将具备高通用性,支持模型厂商自由标注与映射,从而推动行业数据标准建设。
在林啸看来,枢途科技未来更加倾向“数据基础设施第三方化”,目前数据行业相对成熟的自动驾驶与文本模型领域,专业数据公司得益于规模效应与场景覆盖能力,能够更好的形成核心竞争力。并且具身模型未来将走向场景化、多样化,模型厂商无需自建数据采集能力,专注于算法创新即可。
目前,枢途科技已开始在商超场景通过布设单目摄像头的方式采集视频,避免干扰正常工作同时,能够获取多样化数据,持续完善数据飞轮。
▍结语与未来:
在具身智能产业还困在造数据比做模型还难的泥潭里时,枢途科技SynaData系统的出现,更像是给产业搭建了另一条高速公路。过去想搞具身数据,要么砸钱建专用工厂搞遥操作,要么卡在数据只能给自家设备用的死循环里,中小团队想进场连门槛都摸不到。现在凭借SynaData系统,通过分析2D视频就能获得机器人训练的多模态数据,极大降低企业获取数据的成本。
SynaData的真正价值在于将行业内并未深度挖掘的2D视频资源,变成实实在在的数据资产。通过开源数据集的方式,帮助行业内的客户从各自为战的内耗当中走出来,通过数据共用,技术共建的方式推动具身智能产业化落地。
就像枢途科技CTO林啸此前表示的一样:"数据决定上限,模型逼近上限。数据是决定具身模型能力边界的核心,SynaData让机器人得以利用海量的视频数据,通过'观看'人类视频学习技能,真正突破具身模型Scaling Law。"
只有当具身智能领域的核心数据难题,能通过低成本、批量化的方式转化为机器人可直接学习的有效数据,具身智能落地“最后一公里” 的梗阻才能被彻底打通,整个产业也才能真正迈入新一轮快速增长期,而枢途科技已然成为具身智能数据构建的领跑者。