近年来,足式机器人在移动方面均取得了进展,足式机器人能够灵活地穿梭在复杂地形,如楼梯,草地等。而让带有机械臂的足式机器人(移动操作平台)在日常环境中完成复杂任务,是机器人领域的一大挑战。
因为足式机器人的移动操作常涉及与环境的密集接触交互。例如擦黑板时,手臂必须既贴合表面又保持适当的压力;开关柜门时,机器人需要准确感知只有3毫米的推拉式弹簧机构;拉抽屉时, 如果有遮挡,仅凭视觉几乎不可能完成任务;甚至削一根黄瓜,力过小则划不动,力过大则会切断或损坏。这些任务都指向一个事实:仅靠位置控制是远远不够的,需要对接触力和机器人位姿进行联合建模。
为此,北京通用人工智能研究院联合BIGAI&宇树联合实验室、北京邮电大学提出首个统一的力位混合控制策略UniFP,能够让足式机器人在单一框架下统一处理力与位置。该策略把机器人末端执行器与环境之间的交互视作一个弹簧–阻尼–质量系统,通过控制偏差来同时调节位置与力。与UniFP相关的论文成果荣获CoRL 2025最佳论文奖。
在仿真环境Isaac Gym中,通过强化学习进行训练。训练过程中,通过不断施加随机外力、随机命令,让算法学会在各种组合情况下的应有表现,并通过tracking reward function进行优化。并加入了各种域随机化操作,能够很好的实现在真实机器人上的迁移。
在四项挑战性的密集接触操作任务中,相比纯位置控制方法,UniFP成功率高出了近40%。UniFP成功部署在了Unitree B2-Z1四足机器人上和Unitree G1人形机器人上,并进行了7项实验,证明了该算法在不同形态机器人平台上的泛化能力。

论文标题:《UniFP:Learning a Unified Policy for Position and Force Control in Legged Loco-Manipulation》
论文链接:https://arxiv.org/pdf/2505.20829
项目主页:https://unified-force.github.io/
收录情况:CoRL 2025最佳论文奖
1
方法
1.1 力位混合控制统一框架
UniFP核心问题框架如图2(c)上部所示,给定相对于机器人本体坐标系的位置指令和力指令,目标是学习一个强化学习策略,确保机器人在净力F的作用下,能够遵循这些指令。为实现此目标,采用阻抗控制的框架为:
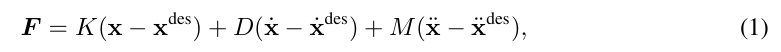

末端执行器建模:由于末端执行器在操作任务中通常移动缓慢,可以对公式(1)进行如下简化:F = K(x - xdes)。净力 F 主要由三部分组成:主动施加的力、因向环境施加而产生的被动反作用力,以及额外的外部扰动力。因此,末端执行器的期望目标位置由下式给出:

多接触点建模:对于末端执行器之外的机器人其他部分,公式(2)可以相应扩展。可以通过假设机器人通过机身速度指令来控制来简化公式(2),从公式(1)推导出:

1.2 学习统一的力-位控制策略
研究人员通过首先定义观察空间、指令空间和动作空间来详细说明所提出的统一力-位置控制策略的学习。具体地,定义机器人的观察,包括机器人的机身朝向、角速度、关节位置、关节速度 、上一时刻的动作、指令以及feet clock timings:

策略设计:在图2(a)中展示了策略模型。策略模型包含三个模块:观察编码器、状态估计器和动作执行器。编码器处理观察历史并输出一个潜在特征,该特征随后被发送到状态估计器和执行器。状态估计器随后预测机器人的状态,包括外力、末端执行器位置和机身速度。这个估计的力随后可以在某些期望的控制行为中被转换为指令信号。
力模拟:为了模拟多样化的场景以学习统一的力-位置策略,按照公式(2)和(4)的要求,随机采样位置、速度和力指令,以及外部净力。
如图2(d)所示,在训练过程中采样的力会线性增加到目标值,保持恒定一段时间,然后根据预定义的时间表降回零。在短暂的零力周期后,新的力会被采样,循环重复。这种采样策略能够满足不同期望控制行为,并使单个策略能够适应变化的控制任务需求。
策略学习:采用两阶段训练流程:首先专注于全身到达和移动,然后引入随机力指令和外部扰动。策略学习通过奖励在不同输入和扰动组合下准确跟踪目标末端执行器位置和机身速度来进行监督。此外,使用MSE损失来提高状态估计器对于机器人状态和外力估计的准确性。
力感知模仿学习
认识到力感知在真实世界操作任务中的重要性及其在大多数现有数据集中的缺失,研究人员利用学习到的力-位混合控制策略来收集用于模仿学习的力感知数据。具体来说,通过遥操作机器人来记录关节状态、机身状态、控制指令、估计的末端执行器接触力,以及安装在末端执行器和机器人机身上的相机拍摄的RGB图像。
这些数据用于训练一个基于扩散模型的力感知模仿学习策略,该策略以机器人状态、估计的力和图像观察作为输入,并预测力和末端执行器位置指令作为底层力-位控制策略的输入。与先前仅依赖视觉输入的工作不同,本论文提出的力估计器为策略提供了接触信息,能够实现更精确的物体交互和力施加。
2
实验
2.1 力与位置指令跟踪
位置跟踪:为了评估在仿真中的性能,进行了6000步的测试,使用仅包含位置指令的随机生成的末端执行器轨迹,覆盖整个训练工作空间。如图3(b)所示,报告了这些试验的平均位置跟踪误差和估计误差。在无外力和力指令的情况下,末端执行器的跟踪误差大多保持在0.1米以内。沿Y轴观察到稍高的误差,这可能是由于该方向可用的自由度较少,限制了精度。还通过比较估计的末端执行器位置与仿真真实值,评估了状态估计器的准确性。如图3(a)所示,在所有轴上,估计误差均保持在0.05米以内。
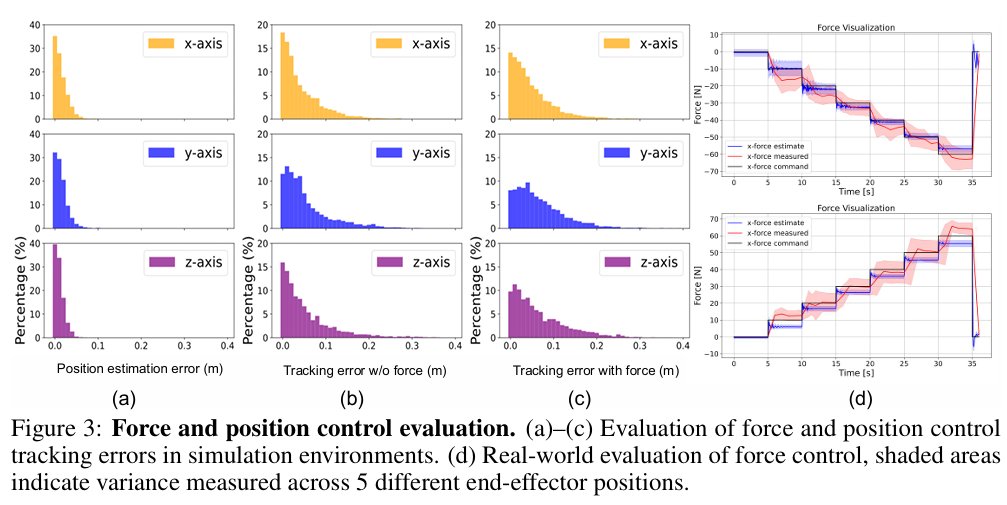
力控制:在两种设置下评估所提出策略估计和响应力的能力。首先,评估当策略接收到与所施加外力相匹配的力指令时的位置跟踪性能,这作为评估统一力-位置控制的一种间接方式。如图3(c)所示,与无外力实验相比,跟踪误差相较于无外力设置略有增加,但大多仍保持在0.1米以内,展示了有效的力感知行为。
其次,在真实机器人上进行了直接的力控制评估,施加0N到60N范围的力指令,并使用测力计测量末端执行器施加的力。在五个不同末端执行器位置进行的测量显示,平均误差在10N以内,如图3(d)所示。在六个离散力水平上的力估计误差在5-10N之间。由于硬件限制,沿Y轴和Z轴的评估上限为40N。
2.2 力感知模仿学习
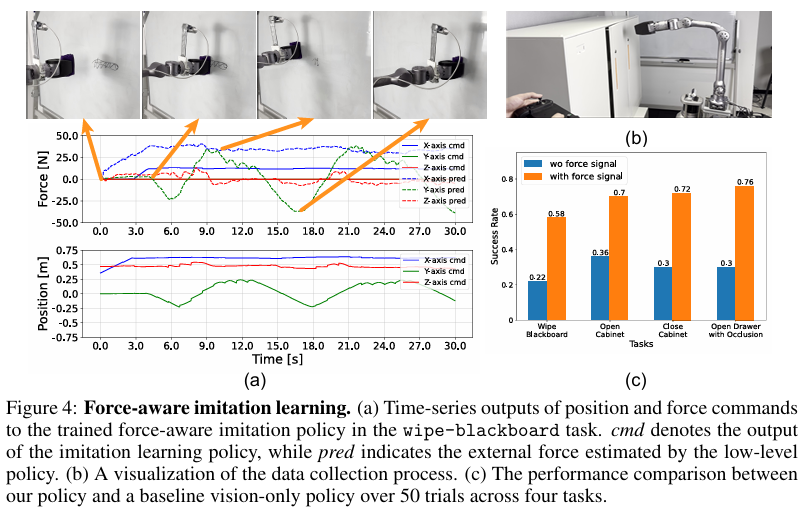
任务设置:研究人员在四个需要力位混合控制和力感知的真实世界任务上评估UniFP,任务包括擦黑板、打开柜门、关闭柜门和打开存在遮挡的抽屉。
结果与分析:实验结果如图4所示,比较了UniFP与基线。UniFP比基线高约40%的成功率。在擦黑板任务中,纯位置策略无法保持稳定的接触,导致擦不干净或用力过猛而导致的表面损坏。相比之下,UniFP的力感知策略确保持续的接触压力,同时底层策略提高了柔性并减少了机械应力。
2.3 从四足到人形机器人的跨平台性能
为验证UniFP的跨机器人平台能力,在Unitree G1人形机器人和Unitree B2-Z1四足移动操作平台上进行了测试。对于移动任务,与操作任务不同,根据公式(4)调整机器人机身速度以补偿外力。如下视频所示,当补偿后的速度与速度指令大小相等方向相反时,人形机器人会停止并倾斜身体以保持平衡。
类似地,如下视频所示,即使在力和速度指令均为零的情况下,四足机器人在被踢时也会开始向前行走。
3
总结
本论文提出一种用于足式机器人的统一力-位混合控制策略UniFP。该策略无需显式力传感器即可让足式机器人完成接触密集的移动操作任务。
UniFP利用强化学习从历史状态估计外力,并通过位置和速度调整对其进行补偿。支持多种行为,如位置跟踪、施力和柔顺控制。此外,该策略将力估计整合到模仿学习中,提高了在接触密集环境中的任务成功率。将UniFP部署在真实的四足和人形机器人上进行了实验,证明了该策略在真实场景中的适应性和鲁棒性。
END
大会预告

智猩猩矩阵号各专所长,点击名片关注










