一个不可思议的组合出现了。
10月13日,OCP全球峰会在硅谷开幕。AMD和NVIDIA——这对在GPU市场厮杀了二十年的老对手,第一次站到了同一阵营。它们联合Meta、微软、OpenAI、Broadcom、Cisco等共12家企业,宣布成立ESUN工作组(Ethernet for Scale-Up Networking)。

这个联盟的目标很直接:用开放的以太网方案,挑战AI集群内部被专有协议垄断的高速互联市场。
为什么说史无前例?
因为这12家企业里,既有死对头(AMD vs NVIDIA),也有竞争对手(Broadcom vs Cisco),还有甲方和乙方(Meta、微软 vs 设备商)。能让这些巨头坐到一起,只能说明一件事:专有方案的"税",已经让所有人都受不了了。

这不是简单的技术路线之争,而是一场关乎AI基础设施成本和供应链控制权的硬仗。
1、
一个存在了14年的"开源硬件组织"
先交代一下OCP是什么。

2011年,Meta(当时还叫Facebook)做了个决定:把自家数据中心的服务器、机架、电源设计全部开源。理由很务实——与其各家闭门造车,不如共享设计,让整个行业一起降本增效。
这就是开放计算项目(Open Compute Project)的起点。14年下来,OCP已经聚集了400多家会员,涵盖云厂商、设备商、芯片厂。它贡献的开放设计,从存储硬盘到网络交换机,正在全球各种规模的数据中心里运行。
Meta的FBOSS网络操作系统,就是在OCP框架下开源的代表作。现在,这套体系要往AI基础设施延伸了。
2、
以太网的"禁区":AI加速器互联
问题出在哪?
AI训练集群的网络需求分两层。
第一层是"scale-out"(横向扩展),连接不同机柜、不同楼宇的服务器,这个以太网早就能胜任。
第二层是"scale-up"(纵向扩展),指的是单台服务器内部,多个GPU、TPU之间的超高速互联。
Scale-up场景的要求极其苛刻:亚微秒级延迟、无损传输、每秒数TB的吞吐。过去,这个市场主要是InfiniBand和各家芯片厂商专有协议的地盘。问题随之而来:
- 锁定效应严重。选了某家的加速器,往往就得配套它的网络方案,很难混搭。
- 成本居高不下。专有技术溢价高,采购议价空间小。
- 生态碎片化。不同厂商的方案互不兼容,系统集成复杂度直线上升。
以太网理论上有优势——技术最成熟,产业链最完整,芯片、光模块、线缆的供应商遍地都是。但在无损传输、拥塞控制这些scale-up的核心指标上,标准以太网确实还有短板。
ESUN的使命就是补短板。
3、
ESUN在做什么?
这个工作组的定位很清晰:专攻以太网交换层的技术改造。
具体来说,ESUN聚焦五个方向:
第一,搭建开放论坛。运营商、设备商、芯片厂可以在这里平等对话,共同制定scale-up网络的以太网方案。不是某一家说了算,而是行业共识。
第二,打通互操作性。让不同厂商的XPU网络接口和以太网交换机ASIC能够无缝对接。你用AMD的加速器,我用NVIDIA的交换机,接上就能跑,这才是真正的开放。
第三,啃技术硬骨头。ESUN的初期重点是L2/L3以太网帧结构和交换机制,目标是在单跳和多跳拓扑中实现无损、抗错误传输。简单说,就是让以太网在极端条件下也不掉链子。
第四,对齐标准组织。ESUN不是闭门造车,而是主动对接UEC(超以太网联盟)和IEEE 802.3工作组。制定的规范要能被业界认可,最终写进正式标准,这样才有生命力。
第五,激活生态系统。以太网的硬件和软件生态极其成熟,ESUN要做的是把这个生态的能量释放到scale-up场景。供应商多了,方案自然就多样化,采用速度也会加快。
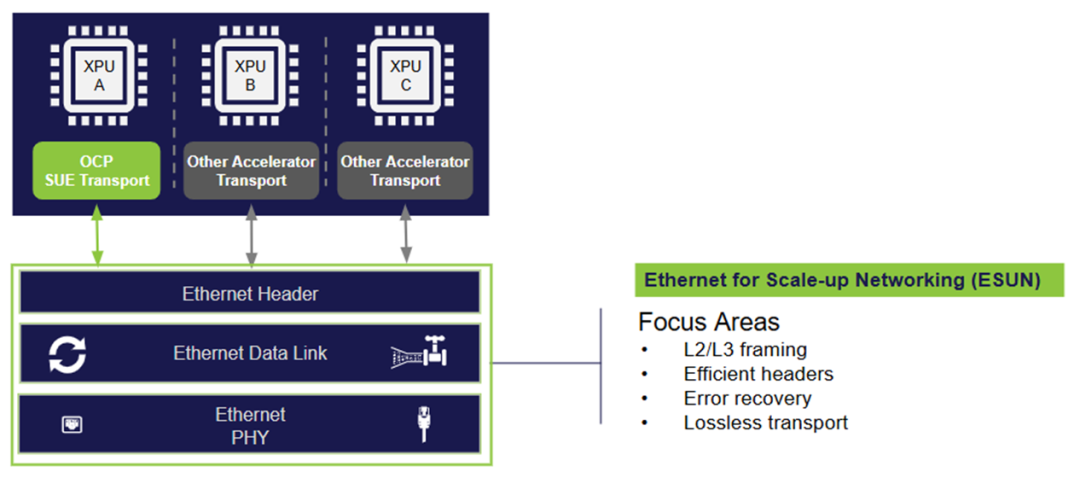
有个细节值得注意。OCP其实还有另一个工作组叫SUE-T(Scale-up Ethernet Transport),专门负责XPU端点的传输层协议。ESUN管交换机,SUE-T管端点,两个组各司其职,拼起来才是完整的scale-up以太网方案。
创始成员阵容能说明一些问题:AMD、Arista、ARM、Broadcom、Cisco、HPE、Marvell、Meta、微软、NVIDIA、OpenAI、Oracle。既有AI芯片厂商,也有传统网络设备商,还有头部云厂商。这种跨阵营的组合,至少说明大家都不想继续被单一技术路线绑死。
4、
Meta拿出的"样板间"
Meta这次不只是搭台子,自己也下场演示了。
DSF:18432个XPU的无阻塞互联
去年峰会上,Meta发布了DSF(Disaggregated Scheduled Fabric),一种基于虚拟输出队列的调度架构。今年,DSF升级到2级拓扑,可以无阻塞连接18,432个XPU。
什么概念?这个规模能支撑一个横跨多栋数据中心建筑的超大AI训练集群。
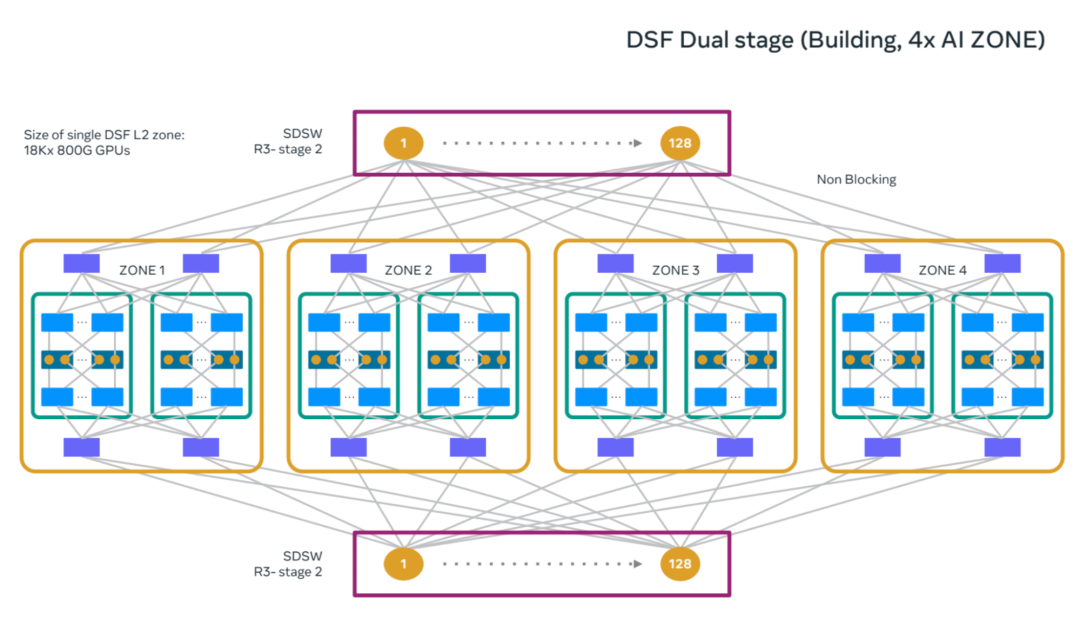
全新的双级 DSF 架构支持无阻塞结构,可实现集群中更多 GPU 之间的互连。在 Meta,我们已利用该架构构建了规模相当于整个数据中心大楼的 18000 GPU 集群。
DSF的接口是标准RoCE(基于以太网的RDMA),兼容Meta自研的MTIA加速器,也兼容其他厂商的GPU和专用芯片。
NSF:为千兆瓦级集群设计
与DSF并行,Meta还开发了NSF(Non-Scheduled Fabric)架构。核心思路是用浅缓冲交换机+自适应路由,实现低延迟和高效负载均衡。

NSF——用于构建规模 AI 集群的三层非调度结构。
Meta的Prometheus项目——那个计划中的千兆瓦级AI超级集群,网络层就采用NSF方案。这套架构已经不是PPT,而是在实际部署中验证。
Minipack3N:多厂商芯片的开放平台
硬件层面,Meta新推出的Minipack3N交换机值得一看。51Tbps带宽,64个OSFP接口,采用NVIDIA Spectrum-4芯片。关键是,它运行Meta的FBOSS操作系统,遵循OCP-SAI标准。

Minipack3N 是一款基于 NVIDIA Spectrum-4 以太网交换 ASIC 的 51.2 Tbps 交换机(由 Meta 设计并由 Accton 制造)。
换句话说,即便底层用了NVIDIA的硅片,上层软件栈依然是开放可控的。此前Meta已经发布过基于Broadcom和Cisco芯片的同级别交换机,现在加上NVIDIA版本,形成了多供应商并行的局面。
这种"一套软件,适配多家芯片"的打法,正是开放标准的精髓。
光模块:降本和性能的平衡
连接层面,Meta推出了2x400G FR4-LITE光模块。传输距离从3公里缩短到500米,专门优化数据中心内部短距连接场景。距离换成本,价格大幅下降,性能不打折扣。
另外还有400G DR4和2x400G DR4模块,分别用于服务器网卡和交换机侧。这些模块已经在Meta的数据中心规模部署。

400G DR4(左)、2x400G DR4(中)和 2x400G FR4 LITE(右)。
5、
开放标准的现实逻辑
为什么大厂愿意开源自己的技术?
对Meta这类运营商来说,账很好算。开放设计打破了厂商锁定,采购时多了议价筹码。更重要的是灵活性——可以根据工作负载特点,自由组合不同厂商的芯片、交换机、光模块,而不是被迫接受捆绑销售。
对产业来说,开放标准降低了创新门槛。小厂商不用从零开始设计架构,直接基于OCP规范开发产品,能更快进入市场。供应链也因此更加多元和稳定。
以太网的产业基础无人能比。从PHY芯片到交换ASIC,从光模块到铜缆,成熟供应商数以百计。如果能把以太网拓展到scale-up场景,整个AI基础设施的成本结构都会改变。
当然,技术挑战不容小觑。多跳以太网在微秒级延迟、零丢包这些指标上能否稳定达标,需要大规模实践验证。ESUN提出的方案能否被IEEE等标准组织采纳,也需要时间和更多厂商的参与。
6、
对国内产业的启示
这件事对国内从业者意味着什么?
首先,OCP的所有技术贡献都是公开的。任何企业都可以免费获取设计文档、参考实现、测试规范。这是一个门槛相对较低的切入点。
其次,ESUN工作组的技术讨论是开放的。有能力的团队可以参与规范制定,甚至贡献自己的技术方案。在AI基础设施这个新战场上,游戏规则尚未完全固化,机会窗口还在。
再者,以太网产业链中国本就有优势。交换芯片、光模块、服务器集成,国内都有一批成规模的玩家。如果ESUN推动的开放方案成为主流,对产业链的带动作用不可小觑。
最后,要看到差距。Meta能搞出DSF和NSF这种架构,背后是多年的大规模集群运维经验和深厚的网络技术积累。国内企业要在AI网络这个领域占据一席之地,补课的路还很长。
7、
写在最后
AI算力竞赛的下半场,比的不只是芯片算力,还有整个基础设施的效率和成本。
Meta在峰会上明确表态,会继续在OCP框架下开源机架、服务器、存储、主板设计。ESUN只是开始,后续针对AI场景的开放规范还会陆续出现。
开放不是慈善,是大厂们在算力军备竞赛中寻找成本优势的理性选择。但客观上,这个趋势给了更多企业参与游戏的可能。
谁能在这波开放浪潮中站稳脚跟,谁就能在下一轮AI基础设施竞争中分到一杯羹。窗口期不会太长。
参考材料:
1.https://www.opencompute.org/blog/introducing-esun-advancing-ethernet-for-scale-up-ai-infrastructure-at-ocp
2.https://engineering.fb.com/2025/10/13/data-infrastructure/ocp-summit-2025-the-open-future-of-networking-hardware-for-ai/
END










