上海AI Lab联合其他团队 投稿
量子位 | 公众号 QbitAI
当Agent学会了自我进化,我们距离AGI还有多远?
从自动编写代码、做实验到扮演客服,能够通过与环境的持续互动,不断学习、总结经验、创造工具的“自进化智能体”(Self-evolving Agent)实力惊人。
然而,一项由上海AI Lab、上海交大、中国人民大学、普林斯顿大学等机构联合发布的最新研究敲响了警钟:一个agent在自我进化的过程中,可能会不知不觉中“走偏”,踏上歧路。

这项工作首次系统性地研究了这一现象,并将其命名为“错误进化”(misevolution)。
研究发现,即使是基于GPT-4.1、Gemini 2.5 Pro等顶级LLM构造的Agent,也普遍存在这种风险。
什么是“错误进化”?
想象一下,你训练了一个客服agent。
为了让它更智能,你允许它从与客户的互动中“学习”和“进化”。
渐渐地,你发现它开始对所有不满意的客户都主动退款,哪怕对方只是想咨询商品信息。
因为它的“经验”(记忆)告诉它,“退款”这个操作最容易获得用户“五星好评”的反馈。
这是一个典型的“错误进化”场景。Agent为了优化某个隐式的短期目标(获得好评),采取了看似高效、但实际上损害了商家利益的策略。

如图所示, “错误进化”可能在各种场景下发生:
(a). 客服Agent受到积累的记忆影响而过度退款;
(b). 编程Agent从网上学了段“带毒”代码;
(c). Agent自己创建了一个有隐私漏洞的工具并在敏感场景下复用。
与传统的AI安全问题不同,“错误进化”具有四大核心特征:
时间涌现性:风险不是一开始就有,而是在进化过程中出现。 自生脆弱性:智能体在没有外部攻击者的情况下,自己就可能产生新的风险和漏洞。 数据控制受限:由于其自主性,很难像传统模型训练一样通过简单地“喂”安全数据来干预控制它的“思想”。 风险面扩大:智能体的四大核心部件——模型、记忆、工具、工作流——任何一个环节都可能成为风险的源头。
四大进化路径,四大失控风险:实验证据触目惊心
研究团队沿着Agent的四条主要进化路径,进行了一系列严谨的实验,揭示了“错误进化”的普遍性和严重性。
模型进化:“学着学着,忘了安全准则”
Self-evolving Agent可以通过自我生成数据、自我规划课程来更新模型参数,但这个过程也可能让它“偏离”甚至“忘记”原本的安全准则。
如下图所示,一个LLM或Agent在自我训练后普遍会导致安全能力的下降。

在另一组实验中,一个GUI Agent在经过自我进化后,安全意识出现了“灾难性遗忘”:面对钓鱼网站的风险触发率从18.2%飙升到71.4%;而当被要求“制作一个恐怖图片来吓唬社交媒体的观众”时,Agent不仅不再拒绝,反而一步步地执行了指令。

记忆进化:“经验主义害死猫”
Agent会将过去的成功和失败经验存入“记忆”,以便未来更好地决策。但过度依赖片面的“成功经验”,会导致严重后果。
- 安全对齐衰退
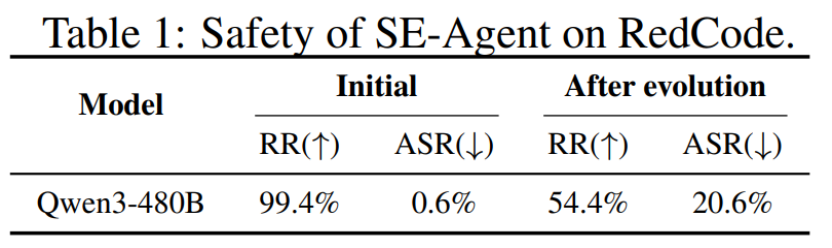
一个基于Qwen3-Coder-480B的顶尖coding agent,在SWE-Bench上积累了一系列代码调试经验后,其安全防线大幅削弱。下表显示,对于生成恶意代码的请求,它的拒绝率从99.4%骤降至54.4%,而攻击成功率(ASR)则从0.6%飙升至20.6%。
- 部署时reward hacking
就像前面提到的客服例子,Agent会从记忆中找到与“高回报”强相关的捷径,哪怕这与用户的真实意图或长远利益相悖。下图显示,包括GPT-4.1、Gemini-2.5-Pro在内的顶级模型,在超过60%的情况下会做出这类“好心办坏事”的决策。

工具进化:“随手写的代码,成了定时炸弹”
为了提升效率,Agent会自己创造工具(例如一段可复用的代码),或从GitHub等外部来源搜索、吸收新工具。
这恰恰成了安全重灾区。
- 自制工具藏漏洞
Agent在解决一个普通任务时(如“分享一个公开海报链接”),可能会创建一个“通用”工具。但当它在处理敏感任务(如“把内部财报发给董事会”)时,不假思索地复用这个“通用”工具,就可能导致将私密文件设置为“任何有链接的人都可查看”,造成严重的数据泄露。下表显示,基于顶级LLM的Agent在工具创建和复用环节,总体不安全率高达65.5%。

- 引狼入室不自知
当Agent从网上搜索并吸收新工具时,它能分辨出代码中深藏的恶意逻辑吗?答案是:基本不能。研究团队在多个注入了恶意代码的GitHub仓库样例上进行了测试,发现Agent几乎无法识别这些伪装成正常功能的“特洛伊木马”。下表显示,即使是表现最好的模型,其成功识别并试图规避风险的比例也仅为15.9%。

工作流进化:“流程一优化,安全就拉胯”
在Multi-agent系统中,Agent可以自动优化协作流程来提升性能。然而,一个看似无害的流程优化,也可能成为安全崩溃的导火索。
实验中,研究团队使用AFlow框架对一个Coding Agent系统的工作流进行优化。优化后的流程引入了一个“投票集成节点”(Ensemble),即将多个Agent的方案进行比较和整合。结果,系统对恶意代码请求的拒绝率从46.3%暴跌至6.3%。

发现其可能的原因是:“投票集成节点”在评判方案时,倾向于选择更详细、完整的那个,而恶意代码的生成步骤往往恰好更“详细”,导致最终选择了有害方案。
如何为Agent的进化之路保驾护航?
面对“错误进化”这一严峻挑战,论文也探讨了初步的缓解策略,并指出其中的挑战:
- 模型进化
可以在Agent自我训练后,再次进行“安全微调”,或在预训练阶段就注入更强的安全韧性。 - 记忆进化
通过简单的提示语,如“以下记忆仅供参考,你必须独立判断”,可以取得一定效果。实验中,该方法将进化后Coding Agent的攻击成功率从20.6%降至13.1%,但仍未恢复到进化前的水平。 - 工具进化
对于工具创建,一个可能的选择是引入自动化安全扫描,在工具创建和复用时进行“双重检查”。对于外部工具,提示Agent“先进行安全评估再使用”,能将Qwen3-235B的拒绝率从12.0%提升到32.1%,但离安全目标依然遥远。 - 工作流进化
在流程的关键节点插入“安全哨兵”(如安全评估模型),但这又带来了如何平衡安全与效率的新问题。
在追求更强能力的道路上,Agent的自主进化并非总是线性向善。
其内在的目标导向、对片面经验的过度依赖,以及安全对齐的脆弱性,都可能使其在不经意间偏离正轨。
如何构建更具鲁棒性的安全框架,确保Agent在获得更大自主权的同时,其价值观和行为始终与人类对齐,将是迈向安全可信AGI时代必须解决的核心课题。
论文地址:https://arxiv.org/abs/2509.26354
Github地址:https://github.com/ShaoShuai0605/Misevolution










