导读
全球计算机视觉顶会 ICCV 2025 即将拉开帷幕,Meta 再次以惊人的研究实力,贡献了多达 37 篇论文(不完全统计),全面覆盖了从 3D 视觉、视频理解、多模态大模型到高保真数字人等前沿领域。这些研究不仅在理论上取得了重大突破,更展现了其在迈向元宇宙和下一代计算平台过程中的技术布局与决心。
本文将这 37 篇重磅论文精心划分为六大主题,带您一文速览 Meta 在计算机视觉领域的最新探索与未来图景。
Meta ICCV 2025 论文研究方向分布
| 总计 | 37 |
核心洞察:
从表格中可以清晰地看到,3D 视觉是 Meta 本次投入最显著的方向,占据了近三分之一的论文数量,尤其在以高斯泼溅(Gaussian Splatting)为代表的高效重建与生成技术上展现了绝对的统治力。
紧随其后的是高保真数字人和多模态大模型,这两个方向的研究成果丰硕,共同构成了 Meta 在构建沉浸式虚拟世界和下一代社交平台(元宇宙)方面的核心技术支柱。
同时,在视频理解和AIGC等传统优势领域也保持着强劲的研究势头,致力于让模型更高效、更智能地理解和生成动态内容。这一分布清晰地揭示了 Meta 当前的研究重点和未来战略布局。
🌍 3D 世界的构建师:从图像到可交互场景
3D 内容的生成与理解是构建沉浸式体验的核心。Meta 在该领域持续深耕,尤其在高斯泼溅(Gaussian Splatting)技术上取得了一系列突破,致力于从稀疏视图甚至单张图像高效生成高质量、可交互的 3D 世界。
A Recipe for Generating 3D Worlds from a Single Image
 论文简介: 由Meta Reality Labs Zurich等机构提出了A Recipe for Generating 3D Worlds from a Single Image,该工作通过将单图像生成3D场景的任务转化为2D修复模型的上下文学习问题,在最小化训练的前提下利用现有生成模型实现高质量VR可用的3D环境生成。核心贡献包括:1)将3D场景合成分解为全景图生成与点云条件修复两个子任务,通过渐进式全景合成策略实现360度可导航环境构建;2)提出基于视觉上下文学习的全景生成方法,通过全局锚定机制提升天空和地面合成一致性;3)设计前向-后向扭曲策略高效微调ControlNet,解决点云掩码碎片化导致的修复难题;4)改进高斯泼溅(3DGS)的可变形扭曲校正机制,有效消除多视角图像局部不一致。实验表明该方法在合成质量、视角一致性及VR显示效果上均优于WonderJourney和DimensionX等最新方法,通过分解复杂任务为可控子问题,在保持模型通用性的同时实现技术突破。
论文简介: 由Meta Reality Labs Zurich等机构提出了A Recipe for Generating 3D Worlds from a Single Image,该工作通过将单图像生成3D场景的任务转化为2D修复模型的上下文学习问题,在最小化训练的前提下利用现有生成模型实现高质量VR可用的3D环境生成。核心贡献包括:1)将3D场景合成分解为全景图生成与点云条件修复两个子任务,通过渐进式全景合成策略实现360度可导航环境构建;2)提出基于视觉上下文学习的全景生成方法,通过全局锚定机制提升天空和地面合成一致性;3)设计前向-后向扭曲策略高效微调ControlNet,解决点云掩码碎片化导致的修复难题;4)改进高斯泼溅(3DGS)的可变形扭曲校正机制,有效消除多视角图像局部不一致。实验表明该方法在合成质量、视角一致性及VR显示效果上均优于WonderJourney和DimensionX等最新方法,通过分解复杂任务为可控子问题,在保持模型通用性的同时实现技术突破。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.2611
FlowR: Flowing from Sparse to Dense 3D Reconstructions
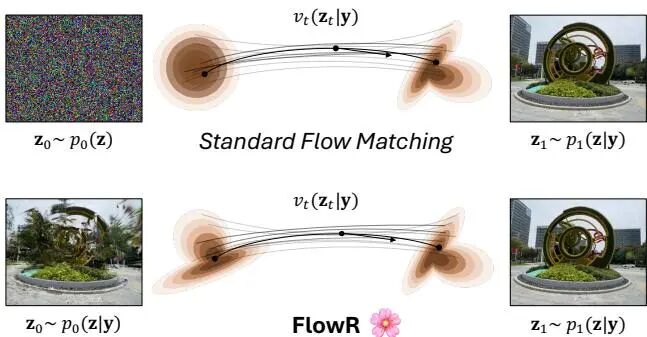 论文简介: 由ETH Zurich、Meta Reality Labs Zurich和CMU等机构提出了FlowR,该工作通过结合3D Gaussian splatting与flow matching技术,解决稀疏视图条件下3D重建质量下降的问题。研究者首先构建了一个鲁棒的初始重建管道,利用结构光束调整(Structure-from-Motion)和单目深度估计生成半稠密点云,随后采用自适应密度控制(ADC)优化3D高斯分布,实现从稀疏到稠密视图的统一重建。核心创新在于提出了一种多视图flow matching模型,通过直接学习稀疏重建渲染图像到稠密重建真实图像的流形映射,生成与输入视图一致的高质量补充视图。该模型基于360万对渲染-真实图像对训练,采用扩散Transformer架构处理多视图一致性,并引入相机姿态编码和图像索引编码提升生成质量。实验表明,FlowR在DL3DV、ScanNet++和Nerfbusters等基准测试中显著优于InstantSplat、ViewCrafter等方法,尤其在12视图稀疏条件下PSNR提升1.57dB,LPIPS降低0.053。模型支持单次前向传播处理45视图(540×960分辨率),在单张H100 GPU上实现高效推理,为虚拟现实等场景提供高质量实时渲染解决方案。
论文简介: 由ETH Zurich、Meta Reality Labs Zurich和CMU等机构提出了FlowR,该工作通过结合3D Gaussian splatting与flow matching技术,解决稀疏视图条件下3D重建质量下降的问题。研究者首先构建了一个鲁棒的初始重建管道,利用结构光束调整(Structure-from-Motion)和单目深度估计生成半稠密点云,随后采用自适应密度控制(ADC)优化3D高斯分布,实现从稀疏到稠密视图的统一重建。核心创新在于提出了一种多视图flow matching模型,通过直接学习稀疏重建渲染图像到稠密重建真实图像的流形映射,生成与输入视图一致的高质量补充视图。该模型基于360万对渲染-真实图像对训练,采用扩散Transformer架构处理多视图一致性,并引入相机姿态编码和图像索引编码提升生成质量。实验表明,FlowR在DL3DV、ScanNet++和Nerfbusters等基准测试中显著优于InstantSplat、ViewCrafter等方法,尤其在12视图稀疏条件下PSNR提升1.57dB,LPIPS降低0.053。模型支持单次前向传播处理45视图(540×960分辨率),在单张H100 GPU上实现高效推理,为虚拟现实等场景提供高质量实时渲染解决方案。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.759
Repurposing 2D Diffusion Models with Gaussian Atlas for 3D Generation
 论文简介: 由斯坦福大学和Meta Reality Labs等机构提出了Repurposing 2D Diffusion Models with Gaussian Atlas for 3D Generation,该工作通过创新性地将3D高斯分布转换为2D高斯图谱(Gaussian Atlas),成功实现了利用预训练2D扩散模型进行高质量3D内容生成。研究团队构建了包含205,737个高质量3D高斯拟合结果的GaussianVerse数据集,并提出将无序3D高斯分布通过球面偏移和等矩形投影转换为结构化2D网格的表示方法。这种方法突破了传统3D扩散模型对数据规模的依赖,通过迁移2D扩散模型的先验知识,在保持几何连续性的同时实现了高效的3D生成。实验表明,该方法在生成质量、提示词对齐度和用户偏好度上均超越现有SOTA方法,且仅需传统方法一半数量的高斯分布(16K vs 33K)。通过将2D扩散模型的解码能力与3D几何特性结合,该研究为跨模态生成模型提供了新范式,为3D内容创作开辟了更高效的技术路径。
论文简介: 由斯坦福大学和Meta Reality Labs等机构提出了Repurposing 2D Diffusion Models with Gaussian Atlas for 3D Generation,该工作通过创新性地将3D高斯分布转换为2D高斯图谱(Gaussian Atlas),成功实现了利用预训练2D扩散模型进行高质量3D内容生成。研究团队构建了包含205,737个高质量3D高斯拟合结果的GaussianVerse数据集,并提出将无序3D高斯分布通过球面偏移和等矩形投影转换为结构化2D网格的表示方法。这种方法突破了传统3D扩散模型对数据规模的依赖,通过迁移2D扩散模型的先验知识,在保持几何连续性的同时实现了高效的3D生成。实验表明,该方法在生成质量、提示词对齐度和用户偏好度上均超越现有SOTA方法,且仅需传统方法一半数量的高斯分布(16K vs 33K)。通过将2D扩散模型的解码能力与3D几何特性结合,该研究为跨模态生成模型提供了新范式,为3D内容创作开辟了更高效的技术路径。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.1130
PhysSplat: Efficient Physics Simulation for 3D Scenes via MLLM-Guided Gaussian Splatting
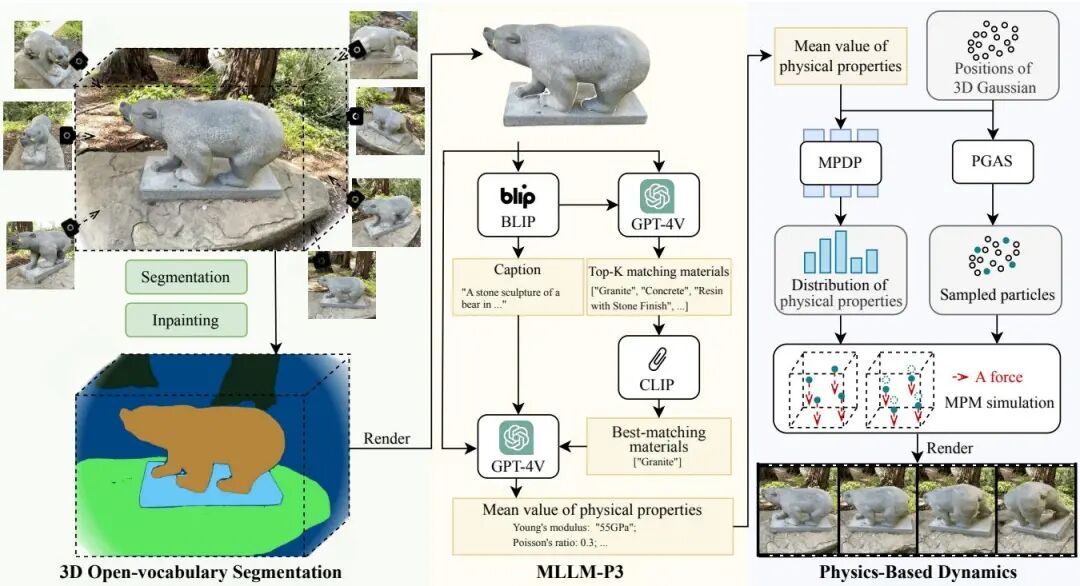 论文简介: 由武汉大学、华中科技大学、Meta Reality Lab等机构提出了PhysSplat,该工作提出了一种基于多模态大语言模型(MLLM)引导的高斯泼溅物理模拟方法,通过零样本物理属性感知和概率分布预测实现高效3D动态场景生成。研究团队创新性地将视觉推理机制引入物理仿真领域,首先利用基础模型完成3D场景的开放词汇分割与多视角图像修复,随后通过MLLM-P3模块实现物体平均物理属性(如密度、杨氏模量等)的零样本预测。为解决属性分布不确定性问题,该方法将物理属性估计重构为概率分布建模任务,通过几何条件概率采样生成属性分布,并采用物理几何自适应采样(PGAS)策略显著降低计算成本。实验表明,PhysSplat在单张RTX 4090 GPU上仅需2分钟即可生成比现有方法更真实的物理动态效果,在真实感评分(RS)和美学评分(AS)上均超越PhysDreamer、Physics3D等前沿方法,同时推理速度提升45倍。该方法突破了传统物理仿真依赖多视角视频或预定义材料模型的限制,为虚拟现实、机器人模拟等场景提供了更高效的动态生成方案。
论文简介: 由武汉大学、华中科技大学、Meta Reality Lab等机构提出了PhysSplat,该工作提出了一种基于多模态大语言模型(MLLM)引导的高斯泼溅物理模拟方法,通过零样本物理属性感知和概率分布预测实现高效3D动态场景生成。研究团队创新性地将视觉推理机制引入物理仿真领域,首先利用基础模型完成3D场景的开放词汇分割与多视角图像修复,随后通过MLLM-P3模块实现物体平均物理属性(如密度、杨氏模量等)的零样本预测。为解决属性分布不确定性问题,该方法将物理属性估计重构为概率分布建模任务,通过几何条件概率采样生成属性分布,并采用物理几何自适应采样(PGAS)策略显著降低计算成本。实验表明,PhysSplat在单张RTX 4090 GPU上仅需2分钟即可生成比现有方法更真实的物理动态效果,在真实感评分(RS)和美学评分(AS)上均超越PhysDreamer、Physics3D等前沿方法,同时推理速度提升45倍。该方法突破了传统物理仿真依赖多视角视频或预定义材料模型的限制,为虚拟现实、机器人模拟等场景提供了更高效的动态生成方案。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.2229
Discontinuity-aware Normal Integration for Generic Central Camera Models
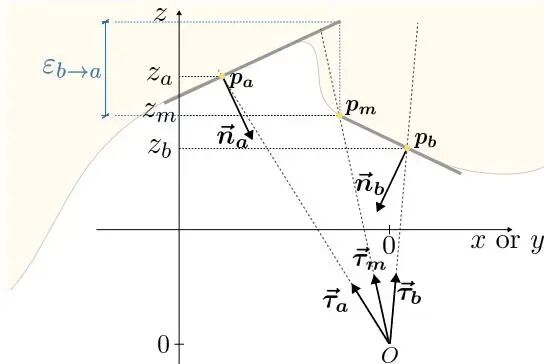 论文简介: 由ETH Zurich和Meta提出了Discontinuity-aware Normal Integration for Generic Central Camera Models,该工作提出了一种基于局部平面假设的新型法线积分方法,通过显式建模深度不连续性并结合射线方向约束,首次实现了对通用中心相机模型(包括非理想针孔相机)的支持。现有方法多基于偏微分方程推导,隐式处理不连续性且局限于正交或理想针孔投影,而该方法通过子像素级平面近似和显式不连续性参数,更精确地描述了深度与法线的映射关系。其核心创新在于:1)建立射线方向与表面法线的点积约束模型,通过子像素插值构建局部平面连续性条件;2)提出可迭代优化的双边权重框架,在优化深度的同时动态更新不连续性参数;3)首次将法线积分扩展到Brown-Conrady畸变镜头等非理想成像场景。实验表明,该方法在DiLiGenT基准测试中达到SOTA精度,重构误差较BiNI等方法降低1-2个数量级,且能有效处理真实世界数据和畸变相机输入。特别在复杂不连续区域(如物体边缘)的重构精度显著提升,为基于法线图的3D重建提供了更普适的解决方案。
论文简介: 由ETH Zurich和Meta提出了Discontinuity-aware Normal Integration for Generic Central Camera Models,该工作提出了一种基于局部平面假设的新型法线积分方法,通过显式建模深度不连续性并结合射线方向约束,首次实现了对通用中心相机模型(包括非理想针孔相机)的支持。现有方法多基于偏微分方程推导,隐式处理不连续性且局限于正交或理想针孔投影,而该方法通过子像素级平面近似和显式不连续性参数,更精确地描述了深度与法线的映射关系。其核心创新在于:1)建立射线方向与表面法线的点积约束模型,通过子像素插值构建局部平面连续性条件;2)提出可迭代优化的双边权重框架,在优化深度的同时动态更新不连续性参数;3)首次将法线积分扩展到Brown-Conrady畸变镜头等非理想成像场景。实验表明,该方法在DiLiGenT基准测试中达到SOTA精度,重构误差较BiNI等方法降低1-2个数量级,且能有效处理真实世界数据和畸变相机输入。特别在复杂不连续区域(如物体边缘)的重构精度显著提升,为基于法线图的3D重建提供了更普适的解决方案。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.2066
Generative Gaussian Splatting: Generating 3D Scenes with Video Diffusion Priors
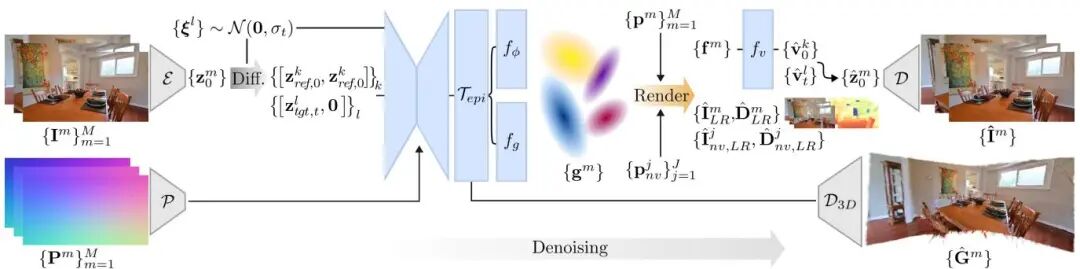 论文简介: 由Meta Reality Labs Zurich等机构提出了Generative Gaussian Splatting(GGS),该工作通过将显式3D高斯点表示与预训练视频扩散模型结合,显著提升了生成3D场景的几何一致性。研究团队针对视频扩散模型生成图像序列缺乏3D一致性的问题,创新性地在扩散模型的特征空间中构建3D表示:首先利用位姿条件扩散模型生成特征场,再通过可微分渲染解码为高斯点云,最终得到显式3D场景表示。该方法在RealEstate10K和ScanNet++数据集上验证,相较于无3D表示的基线模型,生成3D场景的FID指标提升约20%。核心突破在于:1)提出特征空间3D约束机制,解决扩散模型潜在空间非3D一致性的难题;2)设计直接预测3D场景的解码器,通过特征图上采样生成高斯点参数;3)支持可选深度监督,在有深度数据时进一步优化3D一致性。实验表明,GGS在单图生成场景任务中,TSED指标较ViewCrafter等方法提升40%以上,且生成的3D表示可直接用于标准重建算法优化。该工作为生成式3D建模提供了新范式,平衡了图像质量与几何一致性,为元宇宙内容生成等应用提供了技术基础。
论文简介: 由Meta Reality Labs Zurich等机构提出了Generative Gaussian Splatting(GGS),该工作通过将显式3D高斯点表示与预训练视频扩散模型结合,显著提升了生成3D场景的几何一致性。研究团队针对视频扩散模型生成图像序列缺乏3D一致性的问题,创新性地在扩散模型的特征空间中构建3D表示:首先利用位姿条件扩散模型生成特征场,再通过可微分渲染解码为高斯点云,最终得到显式3D场景表示。该方法在RealEstate10K和ScanNet++数据集上验证,相较于无3D表示的基线模型,生成3D场景的FID指标提升约20%。核心突破在于:1)提出特征空间3D约束机制,解决扩散模型潜在空间非3D一致性的难题;2)设计直接预测3D场景的解码器,通过特征图上采样生成高斯点参数;3)支持可选深度监督,在有深度数据时进一步优化3D一致性。实验表明,GGS在单图生成场景任务中,TSED指标较ViewCrafter等方法提升40%以上,且生成的3D表示可直接用于标准重建算法优化。该工作为生成式3D建模提供了新范式,平衡了图像质量与几何一致性,为元宇宙内容生成等应用提供了技术基础。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.395
VertexRegen: Mesh Generation with Continuous Level of Detail
 论文简介: 由UC San Diego和Meta Reality Labs Research提出了VertexRegen,该工作受Hoppe渐进网格启发,将网格生成重新定义为边坍缩的逆过程,通过学习顶点分裂操作实现连续细节层次的网格生成。现有自回归方法采用部分到完整的生成范式,中间步骤会产生无效结构,而VertexRegen通过从粗到细的生成策略,每一步输出都保持完整拓扑结构,支持随时终止生成以获得不同分辨率的有效网格。核心贡献包括:基于半边数据结构的渐进网格参数化方法,将顶点分裂过程转化为可序列化的12token子序列;提出可变分辨率的生成框架,通过Transformer模型预测顶点分裂序列,实现从四面体到精细网格的渐进生成;在无条件生成任务中达到与MeshXL、MeshAnything等方法相当的指标(COV 51.03%,MMD 8.29×10³),同时在face-count约束条件下展现显著优势,例如在400面限制时相比MeshXL条件训练版本提升COV 9.72%、降低MMD 1.72×10³。该方法还支持基于点云的条件生成,通过投影特征到token空间实现形状引导的渐进细化过程,为3D内容生成提供了兼具质量与灵活性的新范式。
论文简介: 由UC San Diego和Meta Reality Labs Research提出了VertexRegen,该工作受Hoppe渐进网格启发,将网格生成重新定义为边坍缩的逆过程,通过学习顶点分裂操作实现连续细节层次的网格生成。现有自回归方法采用部分到完整的生成范式,中间步骤会产生无效结构,而VertexRegen通过从粗到细的生成策略,每一步输出都保持完整拓扑结构,支持随时终止生成以获得不同分辨率的有效网格。核心贡献包括:基于半边数据结构的渐进网格参数化方法,将顶点分裂过程转化为可序列化的12token子序列;提出可变分辨率的生成框架,通过Transformer模型预测顶点分裂序列,实现从四面体到精细网格的渐进生成;在无条件生成任务中达到与MeshXL、MeshAnything等方法相当的指标(COV 51.03%,MMD 8.29×10³),同时在face-count约束条件下展现显著优势,例如在400面限制时相比MeshXL条件训练版本提升COV 9.72%、降低MMD 1.72×10³。该方法还支持基于点云的条件生成,通过投影特征到token空间实现形状引导的渐进细化过程,为3D内容生成提供了兼具质量与灵活性的新范式。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.1182
RI3D: Few-Shot Gaussian Splatting With Repair and Inpainting Diffusion Priors
 论文简介: 由Texas A&M University、Meta Reality Labs和Max Planck Institute for Informatics等机构提出了RI3D,该工作提出了一种基于3D高斯溅射(3DGS)的稀疏视图合成新方法,通过引入两个定制化扩散模型(修复模型和补全模型)分别处理可见区域重建与缺失区域生成,并设计两阶段优化策略实现高质量视图合成。核心创新在于:1)将视图合成任务拆分为可见区域增强与缺失区域补全,通过修复模型生成伪真值图像约束优化过程,补全模型专注生成未观测区域细节;2)提出融合多视角立体深度与单目深度的高斯初始化方法,利用泊松融合结合两者优势获得稠密几何一致的深度图;3)两阶段优化中先用修复模型重建可见区域,再通过迭代补全与优化逐步填充缺失区域。实验表明该方法在极端稀疏输入(如3张图像)下,相比现有NeRF和3DGS方法在LPIPS指标上提升显著,尤其在缺失区域生成更丰富的纹理细节,同时通过高斯溅射实现快速渲染。该方法为稀疏视图重建提供了扩散先验与几何表示结合的新范式。
论文简介: 由Texas A&M University、Meta Reality Labs和Max Planck Institute for Informatics等机构提出了RI3D,该工作提出了一种基于3D高斯溅射(3DGS)的稀疏视图合成新方法,通过引入两个定制化扩散模型(修复模型和补全模型)分别处理可见区域重建与缺失区域生成,并设计两阶段优化策略实现高质量视图合成。核心创新在于:1)将视图合成任务拆分为可见区域增强与缺失区域补全,通过修复模型生成伪真值图像约束优化过程,补全模型专注生成未观测区域细节;2)提出融合多视角立体深度与单目深度的高斯初始化方法,利用泊松融合结合两者优势获得稠密几何一致的深度图;3)两阶段优化中先用修复模型重建可见区域,再通过迭代补全与优化逐步填充缺失区域。实验表明该方法在极端稀疏输入(如3张图像)下,相比现有NeRF和3DGS方法在LPIPS指标上提升显著,尤其在缺失区域生成更丰富的纹理细节,同时通过高斯溅射实现快速渲染。该方法为稀疏视图重建提供了扩散先验与几何表示结合的新范式。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.2702
Easy3D: A Simple Yet Effective Method for 3D Interactive Segmentation
 论文简介: 由Meta Reality Labs的研究团队提出了Easy3D,该工作提出了一种基于体素编码器和轻量级Transformer解码器的3D交互式实例分割方法,通过隐式点击融合策略实现高效精准的3D场景交互分割。该方法采用体素化稀疏编码器提取场景特征,并设计双向Transformer解码器实现点击特征与场景特征的注意力交互,最终通过隐式点击融合预测实例掩码。研究首次将负样本嵌入机制引入隐式融合框架,显著提升了模型对背景区域的判别能力。实验表明,Easy3D在ScanNet、S3DIS、KITTI-360等标准数据集上均超越现有方法,尤其在跨域泛化任务中表现突出——在未见过的高斯溅射重建场景(GS-ScanNet40)上,相比AGILE3D的37.0 IoU@1提升至44.9。其核心优势在于体素表示带来的计算效率提升(参数量仅为Point-SAM的1/10)与隐式融合策略的强泛化能力,在仅3次点击交互下即可达到77.3% IoU。该方法为VR/AR场景中的实时3D交互提供了新范式,实验证明其可无缝集成至高斯溅射渲染管线,在消费级设备上实现物体选择、移动和动态效果操作。
论文简介: 由Meta Reality Labs的研究团队提出了Easy3D,该工作提出了一种基于体素编码器和轻量级Transformer解码器的3D交互式实例分割方法,通过隐式点击融合策略实现高效精准的3D场景交互分割。该方法采用体素化稀疏编码器提取场景特征,并设计双向Transformer解码器实现点击特征与场景特征的注意力交互,最终通过隐式点击融合预测实例掩码。研究首次将负样本嵌入机制引入隐式融合框架,显著提升了模型对背景区域的判别能力。实验表明,Easy3D在ScanNet、S3DIS、KITTI-360等标准数据集上均超越现有方法,尤其在跨域泛化任务中表现突出——在未见过的高斯溅射重建场景(GS-ScanNet40)上,相比AGILE3D的37.0 IoU@1提升至44.9。其核心优势在于体素表示带来的计算效率提升(参数量仅为Point-SAM的1/10)与隐式融合策略的强泛化能力,在仅3次点击交互下即可达到77.3% IoU。该方法为VR/AR场景中的实时3D交互提供了新范式,实验证明其可无缝集成至高斯溅射渲染管线,在消费级设备上实现物体选择、移动和动态效果操作。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.2598
3DGS-LM: Faster Gaussian-Splatting Optimization with Levenberg-Marquardt
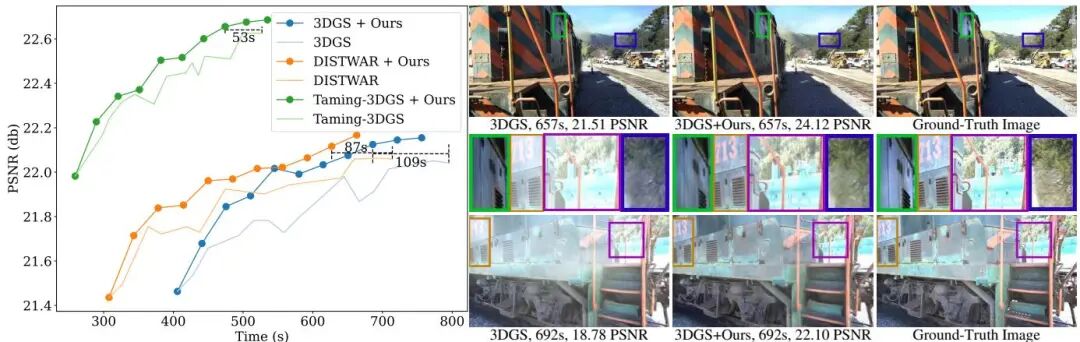 论文简介: 由慕尼黑工业大学、Meta等机构提出了3DGS-LM,该工作通过将3D Gaussian Splatting(3DGS)的优化器从ADAM替换为定制的Levenberg-Marquardt(LM)算法,实现了更快的重建速度。现有方法通过减少高斯数量或改进可微分光栅化器来加速优化,但仍依赖ADAM进行数千次迭代优化,耗时长达一小时。该研究提出使用LM优化器,结合GPU并行化方案和缓存中间梯度的CUDA内核,通过两阶段优化策略(先用ADAM初始化后切换LM)提升效率。核心创新包括:1)针对3DGS的LM优化框架,通过求解法方程近似二阶更新;2)基于缓存结构的高效Jacobian向量积计算,实现每像素-每高斯并行化;3)多图像子集加权均值更新策略,平衡显存与速度。实验表明,该方法在保持相同渲染质量的前提下,相比原始3DGS平均加速20%,且可与其他加速方法(如DistWAR、gsplat)叠加使用。在Tanks&Temples等数据集上,LM优化器在相同时间内生成更高质量渲染结果,但需额外显存缓存梯度(约53GB)。该方法为3DGS优化提供了正交改进方向,为实时应用和后续研究奠定基础。
论文简介: 由慕尼黑工业大学、Meta等机构提出了3DGS-LM,该工作通过将3D Gaussian Splatting(3DGS)的优化器从ADAM替换为定制的Levenberg-Marquardt(LM)算法,实现了更快的重建速度。现有方法通过减少高斯数量或改进可微分光栅化器来加速优化,但仍依赖ADAM进行数千次迭代优化,耗时长达一小时。该研究提出使用LM优化器,结合GPU并行化方案和缓存中间梯度的CUDA内核,通过两阶段优化策略(先用ADAM初始化后切换LM)提升效率。核心创新包括:1)针对3DGS的LM优化框架,通过求解法方程近似二阶更新;2)基于缓存结构的高效Jacobian向量积计算,实现每像素-每高斯并行化;3)多图像子集加权均值更新策略,平衡显存与速度。实验表明,该方法在保持相同渲染质量的前提下,相比原始3DGS平均加速20%,且可与其他加速方法(如DistWAR、gsplat)叠加使用。在Tanks&Temples等数据集上,LM优化器在相同时间内生成更高质量渲染结果,但需额外显存缓存梯度(约53GB)。该方法为3DGS优化提供了正交改进方向,为实时应用和后续研究奠定基础。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.1910
3D Mesh Editing using Masked LRMs
 论文简介: 由Meta Reality Labs和芝加哥大学提出了3D Mesh Editing using Masked LRMs,该工作将形状编辑转化为条件重建问题,通过训练条件大重建模型(LRM)实现高效精准的3D网格编辑。研究者设计了基于多视图一致掩码的训练策略:随机生成3D遮挡物生成掩码区域,并以单个干净视图作为条件信号,使模型在推理阶段仅需单次前向传递即可完成编辑。方法核心优势在于通过掩码机制强制模型学习几何补全能力,既能保留未编辑区域的原始几何结构(重建指标与SOTA相当),又能通过条件视图引导生成符合语义的编辑结果(如拓扑结构改变)。实验表明,该方法在ABO数据集上PSNR达28.65,较InstantMesh提升5.86,且编辑速度达3秒内,较优化方法快2-10倍。特别在处理孔洞添加、把手生成等拓扑变化任务时,突破了传统变形方法的几何限制,同时避免了多视图扩散模型的视角不一致问题。通过与TextDeformer、MagicClay等优化方法及InstantMesh、SyncDreamer等LRM基线对比,验证了其在编辑质量、效率和可控性上的综合优势。
论文简介: 由Meta Reality Labs和芝加哥大学提出了3D Mesh Editing using Masked LRMs,该工作将形状编辑转化为条件重建问题,通过训练条件大重建模型(LRM)实现高效精准的3D网格编辑。研究者设计了基于多视图一致掩码的训练策略:随机生成3D遮挡物生成掩码区域,并以单个干净视图作为条件信号,使模型在推理阶段仅需单次前向传递即可完成编辑。方法核心优势在于通过掩码机制强制模型学习几何补全能力,既能保留未编辑区域的原始几何结构(重建指标与SOTA相当),又能通过条件视图引导生成符合语义的编辑结果(如拓扑结构改变)。实验表明,该方法在ABO数据集上PSNR达28.65,较InstantMesh提升5.86,且编辑速度达3秒内,较优化方法快2-10倍。特别在处理孔洞添加、把手生成等拓扑变化任务时,突破了传统变形方法的几何限制,同时避免了多视图扩散模型的视角不一致问题。通过与TextDeformer、MagicClay等优化方法及InstantMesh、SyncDreamer等LRM基线对比,验证了其在编辑质量、效率和可控性上的综合优势。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.1790
Human-in-the-Loop Local Corrections of 3D Scene Layouts via Infilling
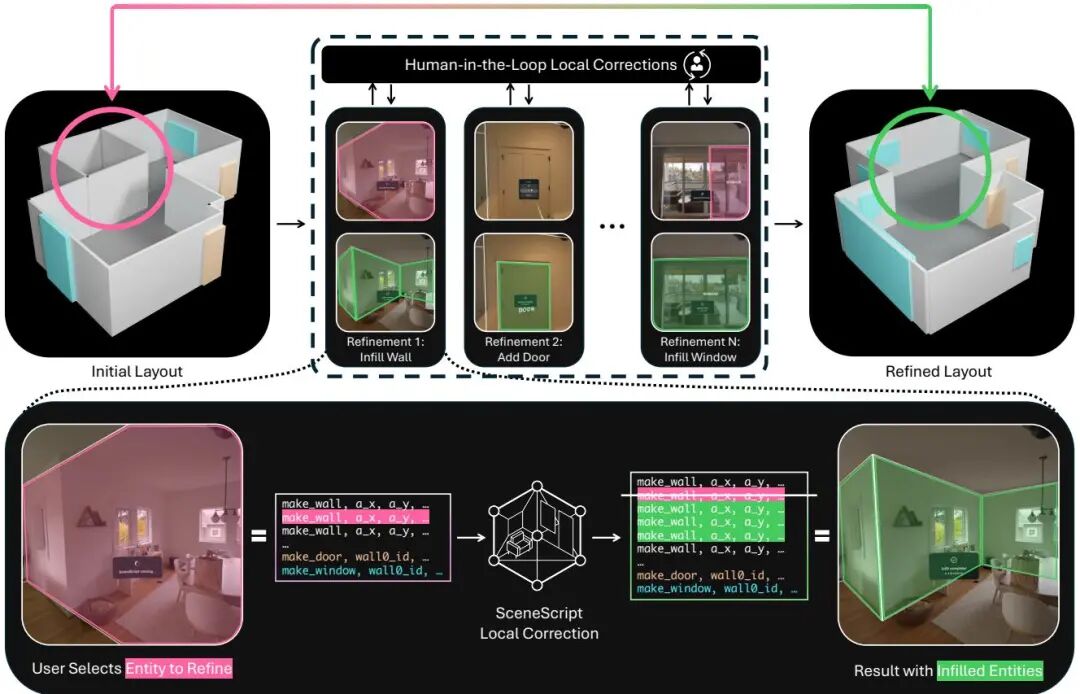 论文简介: 由Meta Reality Labs等机构提出了Human-in-the-Loop Local Corrections of 3D Scene Layouts via Infilling,该工作通过引入人机协同的局部修正机制,解决了传统单次全局预测在复杂场景中的局限性。研究基于SceneScript框架,将局部修正任务转化为自然语言处理中的"填空"问题,开发了支持多任务学习的SceneScript模型,在保持全局预测性能的同时显著提升局部修正能力。系统通过"一键修正"工作流,允许用户以混合现实设备实时迭代优化场景布局,使最终结果突破训练分布限制,实现复杂真实场景的高精度建模。 核心创新包括:1)提出以用户为中心的局部修正任务,通过点击交互引导模型修正错误;2)设计基于填空机制的多任务SceneScript架构,实现全局预测与局部修正的协同优化;3)构建支持实时交互的混合现实系统,通过"修正/添加/删除"操作实现低摩擦场景编辑。实验表明,该方法在合成数据(ASE)和真实场景(AEO)上均取得显著提升,局部修正性能提升4-7个F1点,用户交互次数减少50%以上。研究突破了传统单次预测范式,为人机协同的3D场景理解提供了新范式,为混合现实应用开辟了新路径。
论文简介: 由Meta Reality Labs等机构提出了Human-in-the-Loop Local Corrections of 3D Scene Layouts via Infilling,该工作通过引入人机协同的局部修正机制,解决了传统单次全局预测在复杂场景中的局限性。研究基于SceneScript框架,将局部修正任务转化为自然语言处理中的"填空"问题,开发了支持多任务学习的SceneScript模型,在保持全局预测性能的同时显著提升局部修正能力。系统通过"一键修正"工作流,允许用户以混合现实设备实时迭代优化场景布局,使最终结果突破训练分布限制,实现复杂真实场景的高精度建模。 核心创新包括:1)提出以用户为中心的局部修正任务,通过点击交互引导模型修正错误;2)设计基于填空机制的多任务SceneScript架构,实现全局预测与局部修正的协同优化;3)构建支持实时交互的混合现实系统,通过"修正/添加/删除"操作实现低摩擦场景编辑。实验表明,该方法在合成数据(ASE)和真实场景(AEO)上均取得显著提升,局部修正性能提升4-7个F1点,用户交互次数减少50%以上。研究突破了传统单次预测范式,为人机协同的3D场景理解提供了新范式,为混合现实应用开辟了新路径。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.1499
🎥 动态世界的洞察者:视频理解与目标跟踪
从跟踪万物到理解复杂动作,Meta 致力于让 AI 精准捕捉并理解动态世界中的每一个细节,同时兼顾效率与性能。
(1) Efficient Track Anything
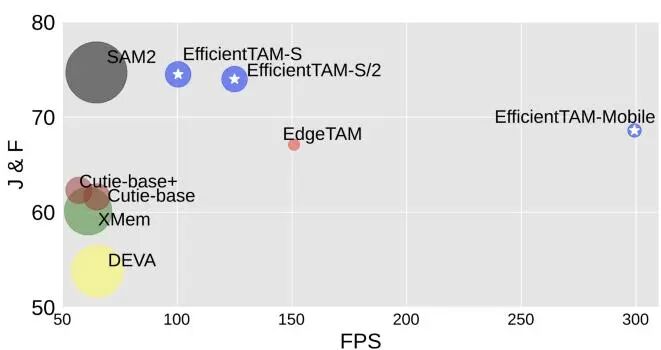 论文简介: 由 Meta AI Research 等机构提出了 Efficient Track Anything (EfficientTAM),该工作通过采用轻量级 Vision Transformer (ViT) 图像编码器和高效内存模块,构建了兼具高性能与低计算复杂度的视频目标分割与跟踪模型。针对 SAM2 因层级图像编码器和长序列内存令牌导致的移动端部署瓶颈,研究团队引入 ViT-Tiny/-Small 作为轻量级编码器,并提出基于空间内存令牌局部性的高效交叉注意力机制:通过 2×2 窗口平均池化生成粗粒度空间令牌,与对象指针令牌拼接后进行注意力计算,在保持精度的同时显著降低计算量。实验表明,EfficientTAM 在 SA-V 测试集上达到 74.5% J&F 准确率,与 SAM2 相当,但参数量减少 2.4 倍、A100 推理速度提升 1.6 倍;在 iPhone 15 Pro Max 上实现 28 FPS 近实时分割,较 EdgeTAM 提速 1.8 倍且精度更高。该模型在半监督视频分割(MOSE、DAVIS 等基准)、提示性视频分割(9 个数据集)及图像分割(SA-23 基准)任务中均表现优异,验证了其在保持 SAM2 级别性能的同时,显著提升了移动端部署可行性,为设备端实时目标跟踪提供了高效解决方案。
论文简介: 由 Meta AI Research 等机构提出了 Efficient Track Anything (EfficientTAM),该工作通过采用轻量级 Vision Transformer (ViT) 图像编码器和高效内存模块,构建了兼具高性能与低计算复杂度的视频目标分割与跟踪模型。针对 SAM2 因层级图像编码器和长序列内存令牌导致的移动端部署瓶颈,研究团队引入 ViT-Tiny/-Small 作为轻量级编码器,并提出基于空间内存令牌局部性的高效交叉注意力机制:通过 2×2 窗口平均池化生成粗粒度空间令牌,与对象指针令牌拼接后进行注意力计算,在保持精度的同时显著降低计算量。实验表明,EfficientTAM 在 SA-V 测试集上达到 74.5% J&F 准确率,与 SAM2 相当,但参数量减少 2.4 倍、A100 推理速度提升 1.6 倍;在 iPhone 15 Pro Max 上实现 28 FPS 近实时分割,较 EdgeTAM 提速 1.8 倍且精度更高。该模型在半监督视频分割(MOSE、DAVIS 等基准)、提示性视频分割(9 个数据集)及图像分割(SA-23 基准)任务中均表现优异,验证了其在保持 SAM2 级别性能的同时,显著提升了移动端部署可行性,为设备端实时目标跟踪提供了高效解决方案。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.2430
CoTracker3: Simpler and Better Point Tracking by Pseudo-Labelling Real Videos
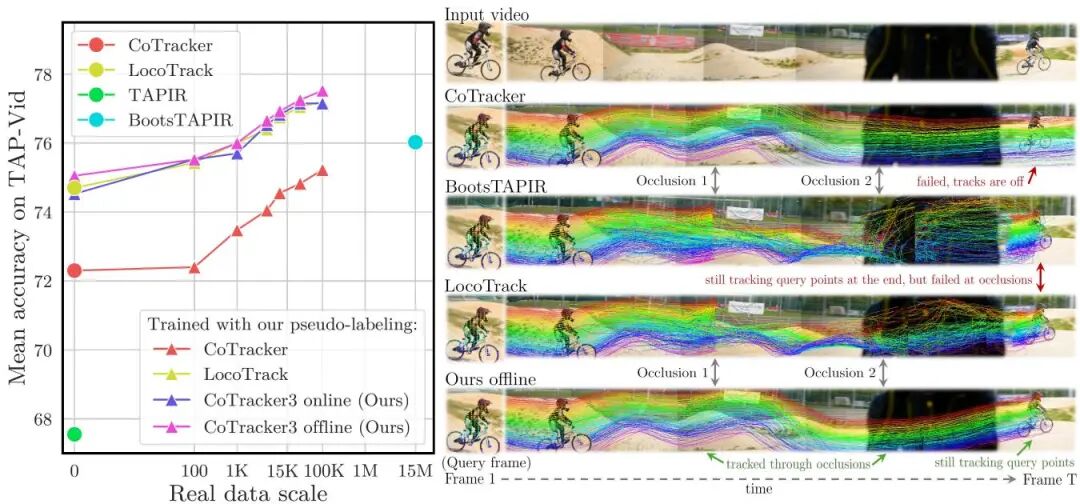 论文简介: 由Meta AI和牛津大学等机构提出了CoTracker3,该工作通过伪标签真实视频数据实现更简单高效的点跟踪。CoTracker3在架构上精简了现有跟踪器的复杂组件(如全局匹配模块),采用4D相关特征和跨轨迹注意力机制,在参数量减少50%的情况下实现27%的速度提升。其核心创新在于提出了一种高效的半监督训练策略:利用多个预训练跟踪器(CoTracker、TAPIR等)为真实视频生成伪标签,仅需1.5万段真实视频(仅为BootsTAPIR的0.1%)即可超越其性能。实验表明,CoTracker3在TAP-Vid和Dynamic Replica等基准测试中均达到SOTA,尤其在遮挡场景下表现突出——离线版本通过全局帧处理能力,将遮挡点跟踪精度提升5.1%。论文还系统验证了不同训练规模的影响,发现仅0.1%的真实数据即可显著提升性能,且自训练策略能进一步缩小合成数据与真实场景的域差距。该方法为视频分析、3D重建等任务提供了更高效的运动估计基础,其轻量化设计更适配实时交互场景。
论文简介: 由Meta AI和牛津大学等机构提出了CoTracker3,该工作通过伪标签真实视频数据实现更简单高效的点跟踪。CoTracker3在架构上精简了现有跟踪器的复杂组件(如全局匹配模块),采用4D相关特征和跨轨迹注意力机制,在参数量减少50%的情况下实现27%的速度提升。其核心创新在于提出了一种高效的半监督训练策略:利用多个预训练跟踪器(CoTracker、TAPIR等)为真实视频生成伪标签,仅需1.5万段真实视频(仅为BootsTAPIR的0.1%)即可超越其性能。实验表明,CoTracker3在TAP-Vid和Dynamic Replica等基准测试中均达到SOTA,尤其在遮挡场景下表现突出——离线版本通过全局帧处理能力,将遮挡点跟踪精度提升5.1%。论文还系统验证了不同训练规模的影响,发现仅0.1%的真实数据即可显著提升性能,且自训练策略能进一步缩小合成数据与真实场景的域差距。该方法为视频分析、3D重建等任务提供了更高效的运动估计基础,其轻量化设计更适配实时交互场景。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.1748
Trokens: Semantic-Aware Relational Trajectory Tokens for Few-Shot Action Recognition
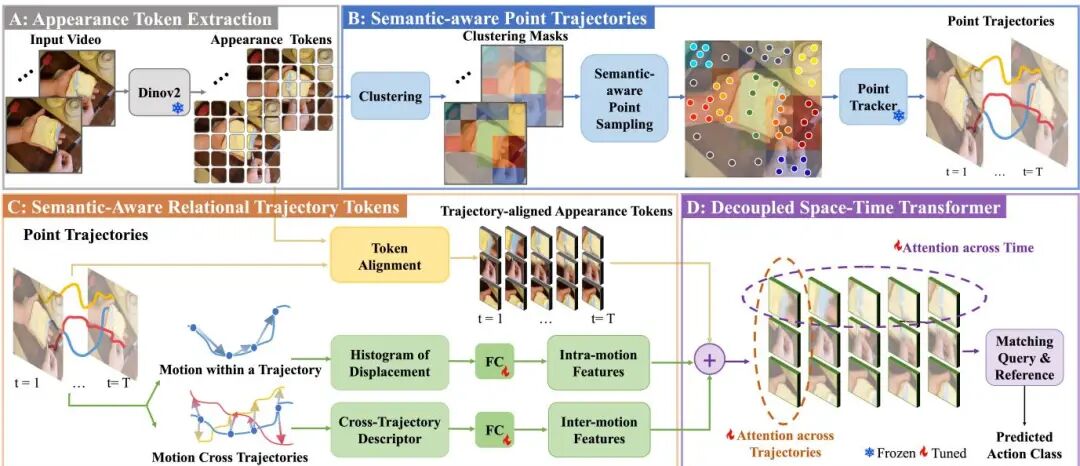 论文简介: 由马里兰大学和Meta等机构提出的Trokens,通过语义感知的轨迹令牌方法革新了少样本动作识别领域。该工作针对点跟踪技术在动作识别中的两大核心挑战——关键点选择与运动模式建模,创新性地引入了语义引导的采样策略和关系运动建模框架。研究团队首先利用DINO模型的语义特征进行聚类,自适应地在小尺度关键物体(如刀具)上密集采样、在大尺度背景区域稀疏采样,解决了传统均匀采样易遗漏重要运动信息的问题。在此基础上,通过Histogrm of Oriented Displacements(HoD)捕捉单个轨迹的运动方向变化,并构建轨迹间相对位置关系矩阵,实现了对复杂动作模式的精细刻画。实验部分在Something-Something、Kinetics等六大基准数据集上全面验证,以5-way 1-shot为例,在SSV2 Full数据集上达到61.5%的准确率,相较前作TATs提升3.8%,在HMDB51数据集上更是取得9.8%的显著提升。消融实验证明语义采样和运动建模模块分别贡献了约2%和3%的性能增益,且32点采样策略在降低82%计算量的同时超越了TATs的256点表现。该方法通过语义引导与运动显式建模的协同创新,为少样本场景下的视频理解提供了新的技术范式。
论文简介: 由马里兰大学和Meta等机构提出的Trokens,通过语义感知的轨迹令牌方法革新了少样本动作识别领域。该工作针对点跟踪技术在动作识别中的两大核心挑战——关键点选择与运动模式建模,创新性地引入了语义引导的采样策略和关系运动建模框架。研究团队首先利用DINO模型的语义特征进行聚类,自适应地在小尺度关键物体(如刀具)上密集采样、在大尺度背景区域稀疏采样,解决了传统均匀采样易遗漏重要运动信息的问题。在此基础上,通过Histogrm of Oriented Displacements(HoD)捕捉单个轨迹的运动方向变化,并构建轨迹间相对位置关系矩阵,实现了对复杂动作模式的精细刻画。实验部分在Something-Something、Kinetics等六大基准数据集上全面验证,以5-way 1-shot为例,在SSV2 Full数据集上达到61.5%的准确率,相较前作TATs提升3.8%,在HMDB51数据集上更是取得9.8%的显著提升。消融实验证明语义采样和运动建模模块分别贡献了约2%和3%的性能增益,且32点采样策略在降低82%计算量的同时超越了TATs的256点表现。该方法通过语义引导与运动显式建模的协同创新,为少样本场景下的视频理解提供了新的技术范式。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.1836
Enrich and Detect: Video Temporal Grounding with Multimodal LLMs
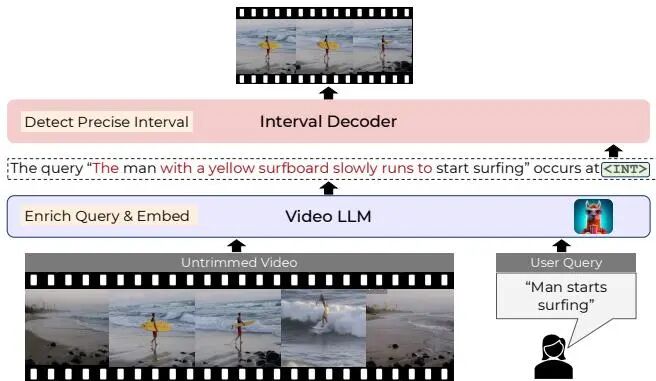 论文简介: 由Shraman Pramanick等来自Meta、约翰霍普金斯大学和东北大学的研究者提出了Enrich and Detect (ED-VTG)方法,该工作通过多模态大语言模型实现细粒度视频时间接地。核心贡献包括:1) 提出两阶段级联框架,先利用LLM对输入查询进行细节增强,再通过轻量级解码器预测时间边界;2) 引入上下文感知的区间表示,使LLM能够聚焦语言生成而解码器专注时序定位;3) 采用多实例学习框架动态选择最优查询版本,有效缓解伪标签噪声问题;4) 在单查询时间接地、段落接地等任务上取得SOTA结果,首次实现LLM模型超越或媲美专用模型,且在零样本场景下优势显著。该方法通过查询增强弥补自然语言描述的不完整性,结合检测损失优化,显著提升了视频-文本对齐精度。
论文简介: 由Shraman Pramanick等来自Meta、约翰霍普金斯大学和东北大学的研究者提出了Enrich and Detect (ED-VTG)方法,该工作通过多模态大语言模型实现细粒度视频时间接地。核心贡献包括:1) 提出两阶段级联框架,先利用LLM对输入查询进行细节增强,再通过轻量级解码器预测时间边界;2) 引入上下文感知的区间表示,使LLM能够聚焦语言生成而解码器专注时序定位;3) 采用多实例学习框架动态选择最优查询版本,有效缓解伪标签噪声问题;4) 在单查询时间接地、段落接地等任务上取得SOTA结果,首次实现LLM模型超越或媲美专用模型,且在零样本场景下优势显著。该方法通过查询增强弥补自然语言描述的不完整性,结合检测损失优化,显著提升了视频-文本对齐精度。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.1418
Streaming VideoLLMs for Real-Time Procedural Video Understanding
论文简介: 由Meta、FAIR和新加坡国立大学等机构提出的ProVideLLM,通过创新的流媒体多模态缓存机制,实现了实时程序化视频理解。该框架将长期观察压缩为文本token,短期观察保留为视觉token,并在统一缓存中交错存储,使一小时视频的token数量减少22倍。核心创新包括:1)基于DETR-QFormer的视觉编码器,通过手部-物体交互建模提升细粒度动作识别;2)在线文本化长期步骤序列,将语义相似的视觉token转化为语言描述;3)多模态交错缓存架构,使计算复杂度随视频长度亚线性增长。实验表明,ProVideLLM在Ego4D等四个数据集的六项任务中刷新SOTA,其中在线步骤检测mAP提升4.1%,动作预期Top-5准确率提升1.8%。该模型在单卡A6000上实现10FPS实时推理,内存占用仅2GB,同时支持25FPS的流式对话交互。这种突破性设计首次将识别、预测和规划统一于单个实时框架,为AR辅助等应用场景提供了高效解决方案。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.1791
🗣️ 多模态的融合大师:驾驭视觉与语言
打通视觉与语言的壁垒是通往通用人工智能的关键一步。Meta 在多模态大语言模型(MLLM)的控制、评估、训练和应用上进行了深入探索。
Controlling Multimodal LLMs via Reward-guided Decoding
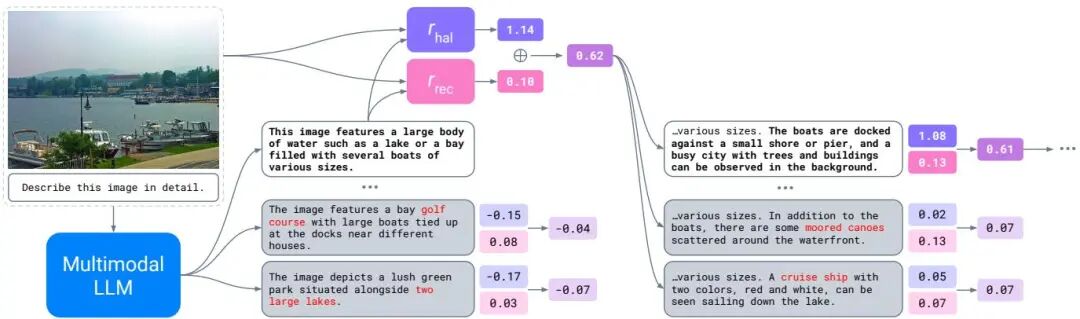 论文简介: 由 Mila、蒙特利尔大学、Meta FAIR 等机构提出了 Controlling Multimodal LLMs via Reward-guided Decoding,该工作提出了一种基于奖励引导的解码方法(MRGD),通过构建多模态奖励模型实现对多模态大语言模型(MLLMs)的推理控制。该方法针对视觉定位任务中的目标精度与召回率平衡问题,设计了两个独立的奖励模型:基于偏好数据训练的物体幻觉奖励模型 和基于预训练模块组合的目标召回奖励模型 。通过线性加权组合这两个奖励函数,用户可在推理阶段动态调节权重 ,实现目标精度()与召回率()的平滑切换。实验表明,该方法在COCO和AMBER基准测试中将实例级幻觉率(CHAIR)分别降低70%和60%,同时保持目标召回率仅下降6.5%。通过调整搜索宽度 和评估周期 ,该方法还能在计算资源与视觉定位质量之间实现灵活权衡,相比传统拒绝采样方法提升6倍样本效率。研究还揭示了MLLMs中固有的精度-召回率权衡特性,并证明该方法可适配LLaVA-1.5、Llama-3.2-Vision等不同架构模型,在不进行参数微调的情况下持续优于现有幻觉抑制技术。
论文简介: 由 Mila、蒙特利尔大学、Meta FAIR 等机构提出了 Controlling Multimodal LLMs via Reward-guided Decoding,该工作提出了一种基于奖励引导的解码方法(MRGD),通过构建多模态奖励模型实现对多模态大语言模型(MLLMs)的推理控制。该方法针对视觉定位任务中的目标精度与召回率平衡问题,设计了两个独立的奖励模型:基于偏好数据训练的物体幻觉奖励模型 和基于预训练模块组合的目标召回奖励模型 。通过线性加权组合这两个奖励函数,用户可在推理阶段动态调节权重 ,实现目标精度()与召回率()的平滑切换。实验表明,该方法在COCO和AMBER基准测试中将实例级幻觉率(CHAIR)分别降低70%和60%,同时保持目标召回率仅下降6.5%。通过调整搜索宽度 和评估周期 ,该方法还能在计算资源与视觉定位质量之间实现灵活权衡,相比传统拒绝采样方法提升6倍样本效率。研究还揭示了MLLMs中固有的精度-召回率权衡特性,并证明该方法可适配LLaVA-1.5、Llama-3.2-Vision等不同架构模型,在不进行参数微调的情况下持续优于现有幻觉抑制技术。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.2612
Bidirectional Likelihood Estimation with Multi-Modal Large Language Models for Text-Video Retrieval
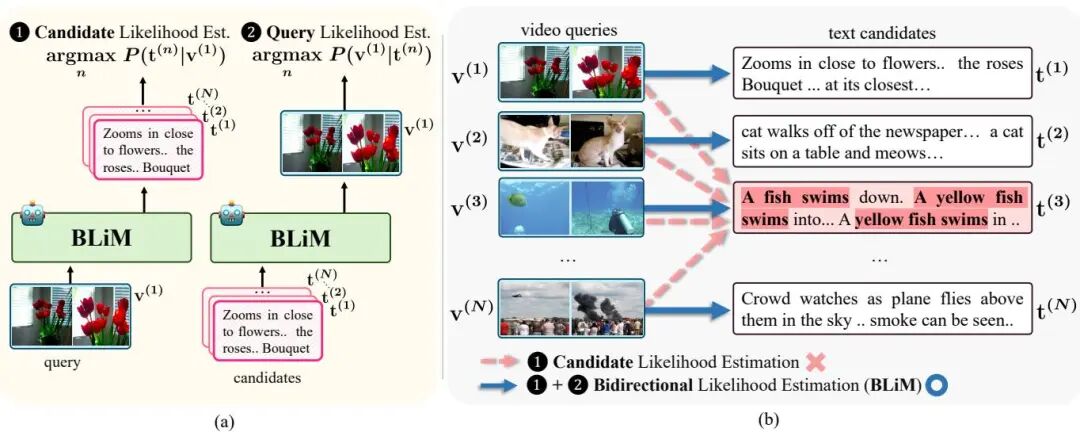 论文简介: 由韩国高丽大学、Meta GenAI和KAIST等机构提出的BLiM框架,针对多模态大语言模型(MLLM)在文本-视频检索中存在候选先验偏差的问题,通过双向似然估计和候选先验归一化(CPN)技术显著提升了检索准确性。该工作发现传统MLLM检索方法过度依赖候选文本或视频的固有概率分布,导致检索结果偏离实际语义相关性。例如在视频到文本检索中,模型可能优先选择包含高频词汇的文本,而非与视频内容匹配的描述。为此,BLiM框架创新性地引入双向似然估计机制,同时训练模型实现"文本生成视频特征"和"视频生成文本"的双向预测能力。通过联合优化P(t|v)和P(v|t)两个目标函数,模型在推理阶段能够同时评估查询似然和候选似然,有效平衡语义相关性与候选先验。此外,CPN模块通过归一化候选先验概率P(t)的α次幂,在不增加训练成本的情况下显著降低先验偏差影响。实验表明,BLiM在DiDeMo、ActivityNet等四个基准数据集上平均提升6.4 R@1指标,其中在DiDeMo数据集的文本到视频检索任务中超越现有最优方法12.2 R@1。值得注意的是,CPN技术在视觉问答、视频理解等7个多模态任务中展现出普适性,通过调整解码策略使LLaVA-OneVision等模型平均提升4.4-11.8分。该研究不仅解决了MLLM检索的核心偏差问题,其提出的双向建模范式和归一化技术为多模态大模型的优化提供了新思路。
论文简介: 由韩国高丽大学、Meta GenAI和KAIST等机构提出的BLiM框架,针对多模态大语言模型(MLLM)在文本-视频检索中存在候选先验偏差的问题,通过双向似然估计和候选先验归一化(CPN)技术显著提升了检索准确性。该工作发现传统MLLM检索方法过度依赖候选文本或视频的固有概率分布,导致检索结果偏离实际语义相关性。例如在视频到文本检索中,模型可能优先选择包含高频词汇的文本,而非与视频内容匹配的描述。为此,BLiM框架创新性地引入双向似然估计机制,同时训练模型实现"文本生成视频特征"和"视频生成文本"的双向预测能力。通过联合优化P(t|v)和P(v|t)两个目标函数,模型在推理阶段能够同时评估查询似然和候选似然,有效平衡语义相关性与候选先验。此外,CPN模块通过归一化候选先验概率P(t)的α次幂,在不增加训练成本的情况下显著降低先验偏差影响。实验表明,BLiM在DiDeMo、ActivityNet等四个基准数据集上平均提升6.4 R@1指标,其中在DiDeMo数据集的文本到视频检索任务中超越现有最优方法12.2 R@1。值得注意的是,CPN技术在视觉问答、视频理解等7个多模态任务中展现出普适性,通过调整解码策略使LLaVA-OneVision等模型平均提升4.4-11.8分。该研究不仅解决了MLLM检索的核心偏差问题,其提出的双向建模范式和归一化技术为多模态大模型的优化提供了新思路。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.1800
CompCap: Improving Multimodal Large Language Models with Composite Captions
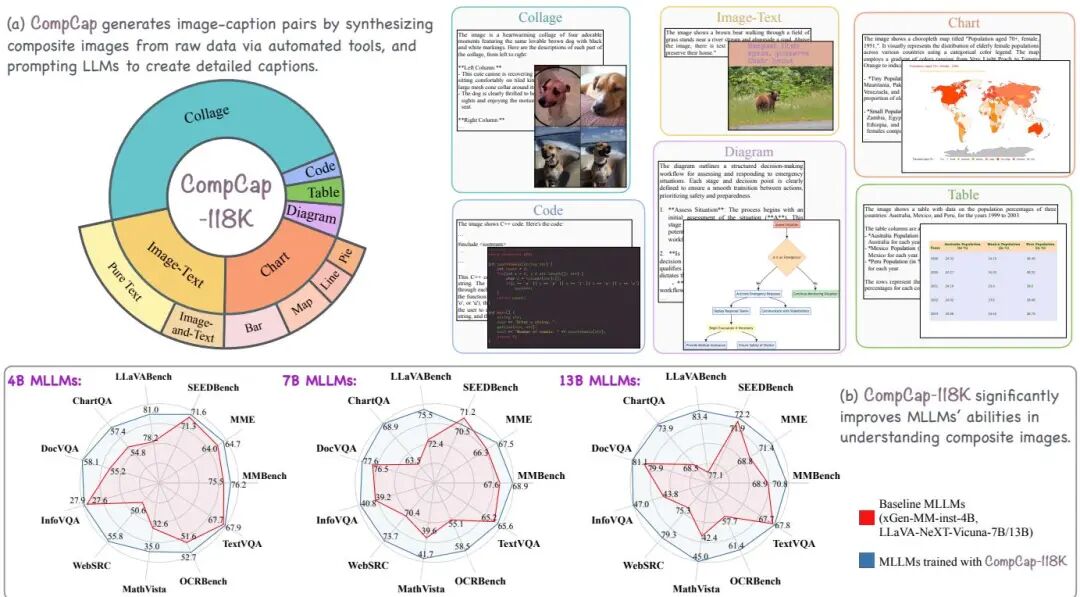 论文简介: 由Meta、Tufts University和Georgia Tech等机构提出了CompCap框架,该工作通过生成高质量复合图像字幕数据显著提升多模态大语言模型(MLLMs)对复合图像的理解能力。研究发现当前MLLMs在理解由图表、海报、截图等合成的复合图像时存在信息提取不准确、推理能力弱等问题,主要原因是训练数据中缺乏高质量的复合图像-字幕对。为此,研究团队开发了可扩展的CompCap框架,利用LLM和自动化工具构建了包含11.8万对图像-字幕的CompCap-118K数据集,覆盖拼贴画、图文混合、图表、图表代码、表格等6类复合图像。该框架通过元数据(如图像-caption对、布局信息、代码等)生成合成图像,并设计特定提示词引导LLM生成准确详细的字幕。实验表明,将CompCap数据集加入xGen-MM和LLaVA-NeXT模型训练后,在11个基准测试中分别取得1.7%、2.0%和2.9%的平均性能提升,尤其在图表问答(ChartQA)等复合图像任务中表现突出。研究还通过消融实验证明了不同复合图像类型数据的贡献,并揭示了字幕数据相比指令数据在提升视觉-语言对齐能力上的优势。该成果为解决多模态模型在专业领域图像理解的瓶颈提供了新思路。
论文简介: 由Meta、Tufts University和Georgia Tech等机构提出了CompCap框架,该工作通过生成高质量复合图像字幕数据显著提升多模态大语言模型(MLLMs)对复合图像的理解能力。研究发现当前MLLMs在理解由图表、海报、截图等合成的复合图像时存在信息提取不准确、推理能力弱等问题,主要原因是训练数据中缺乏高质量的复合图像-字幕对。为此,研究团队开发了可扩展的CompCap框架,利用LLM和自动化工具构建了包含11.8万对图像-字幕的CompCap-118K数据集,覆盖拼贴画、图文混合、图表、图表代码、表格等6类复合图像。该框架通过元数据(如图像-caption对、布局信息、代码等)生成合成图像,并设计特定提示词引导LLM生成准确详细的字幕。实验表明,将CompCap数据集加入xGen-MM和LLaVA-NeXT模型训练后,在11个基准测试中分别取得1.7%、2.0%和2.9%的平均性能提升,尤其在图表问答(ChartQA)等复合图像任务中表现突出。研究还通过消融实验证明了不同复合图像类型数据的贡献,并揭示了字幕数据相比指令数据在提升视觉-语言对齐能力上的优势。该成果为解决多模态模型在专业领域图像理解的瓶颈提供了新思路。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.428
Scaling Language-Free Visual Representation Learning
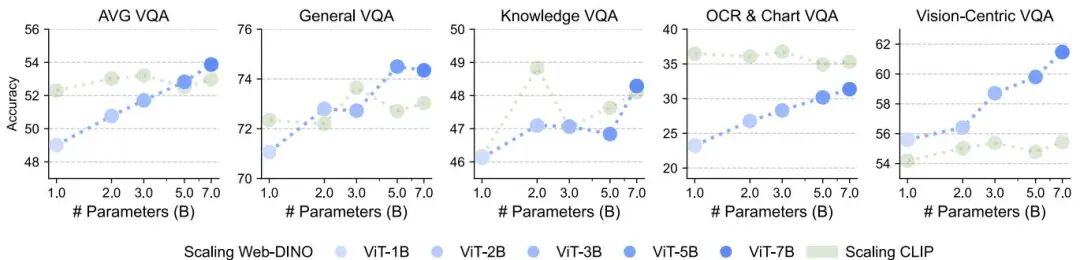 论文简介: 由Meta、纽约大学和普林斯顿大学等机构提出了Scaling Language-Free Visual Representation Learning,该工作通过在相同数据集(MetaCLIP)上训练视觉自监督学习(SSL)和CLIP模型,并使用视觉问答(VQA)作为评估基准,发现纯视觉SSL在扩展模型和数据规模后可达到甚至超越语言监督的CLIP模型性能。研究发现,当SSL模型扩展到70亿参数并在20亿张图像上训练时,其在VQA任务上的表现(包括OCR和图表理解)可与CLIP持平甚至超越,且性能随模型和数据规模持续提升,未出现饱和现象。实验表明,通过增加含文本图像的训练比例,SSL模型在OCR&Chart任务上表现显著提升,且SSL模型的视觉特征与语言模型的对齐程度随规模扩大而增强。该工作证明了纯视觉自监督学习在大规模数据和模型下的潜力,为视觉主导的多模态表示学习提供了新方向。
论文简介: 由Meta、纽约大学和普林斯顿大学等机构提出了Scaling Language-Free Visual Representation Learning,该工作通过在相同数据集(MetaCLIP)上训练视觉自监督学习(SSL)和CLIP模型,并使用视觉问答(VQA)作为评估基准,发现纯视觉SSL在扩展模型和数据规模后可达到甚至超越语言监督的CLIP模型性能。研究发现,当SSL模型扩展到70亿参数并在20亿张图像上训练时,其在VQA任务上的表现(包括OCR和图表理解)可与CLIP持平甚至超越,且性能随模型和数据规模持续提升,未出现饱和现象。实验表明,通过增加含文本图像的训练比例,SSL模型在OCR&Chart任务上表现显著提升,且SSL模型的视觉特征与语言模型的对齐程度随规模扩大而增强。该工作证明了纯视觉自监督学习在大规模数据和模型下的潜力,为视觉主导的多模态表示学习提供了新方向。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.1654
Zero-Shot Vision Encoder Grafting via LLM Surrogates
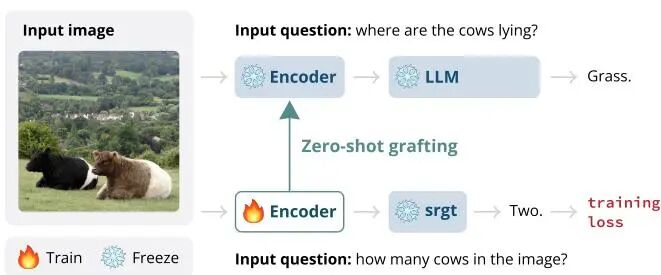 论文简介: 由马里兰大学和Meta等机构提出了Zero-Shot Vision Encoder Grafting via LLM Surrogates,该工作通过构建与大型语言模型(LLM)共享嵌入空间的小型代理模型,实现视觉编码器的高效训练与零样本迁移。研究发现LLM的预测轨迹存在早期特征提取和晚期预测收敛的两阶段特性,通过保留早期处理层并替换晚期层构建代理模型,可使训练后的视觉编码器直接适配目标LLM,减少约45%的训练成本。 核心贡献包括:1)提出基于LLM内部预测轨迹分析的代理模型构建方法,通过保留早期层参数确保与目标模型的嵌入空间一致性;2)实现视觉编码器的零样本迁移能力,代理模型训练的编码器可直接触发LLM完成复杂视觉理解任务;3)验证了代理训练对加速大模型微调的显著效果,在Llama-70B上仅用10%数据即达到基线100%数据的性能,训练成本降低45%。实验表明,该方法在MMBench、POPE等12个视觉任务上超越全参数微调效果,同时通过OCR、创意写作等任务展示了代理模型生成细粒度视觉特征的能力。该框架为大模型时代视觉-语言模型的高效训练提供了新范式。
论文简介: 由马里兰大学和Meta等机构提出了Zero-Shot Vision Encoder Grafting via LLM Surrogates,该工作通过构建与大型语言模型(LLM)共享嵌入空间的小型代理模型,实现视觉编码器的高效训练与零样本迁移。研究发现LLM的预测轨迹存在早期特征提取和晚期预测收敛的两阶段特性,通过保留早期处理层并替换晚期层构建代理模型,可使训练后的视觉编码器直接适配目标LLM,减少约45%的训练成本。 核心贡献包括:1)提出基于LLM内部预测轨迹分析的代理模型构建方法,通过保留早期层参数确保与目标模型的嵌入空间一致性;2)实现视觉编码器的零样本迁移能力,代理模型训练的编码器可直接触发LLM完成复杂视觉理解任务;3)验证了代理训练对加速大模型微调的显著效果,在Llama-70B上仅用10%数据即达到基线100%数据的性能,训练成本降低45%。实验表明,该方法在MMBench、POPE等12个视觉任务上超越全参数微调效果,同时通过OCR、创意写作等任务展示了代理模型生成细粒度视觉特征的能力。该框架为大模型时代视觉-语言模型的高效训练提供了新范式。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.1383
MetaMorph: Multimodal Understanding and Generation via Instruction Tuning
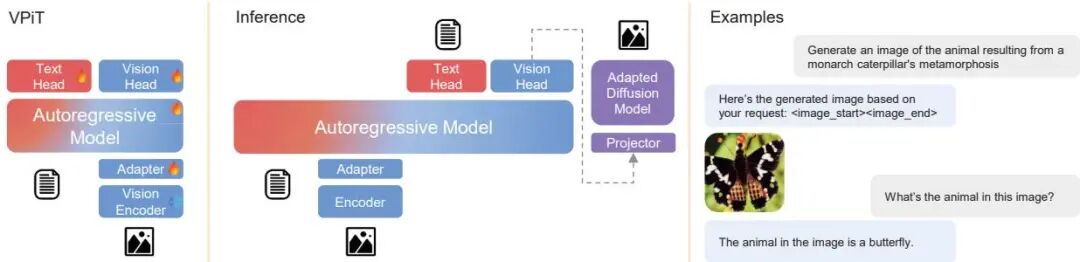 论文简介: 由 FAIR、Meta、纽约大学、Meta Reality Labs 和普林斯顿大学等机构提出了 MetaMorph,该工作通过 Visual-Predictive Instruction Tuning (VPiT) 方法,将视觉指令调整扩展为支持多模态生成任务。研究发现视觉生成能力是视觉理解提升的自然副产品,仅需少量生成数据即可解锁,且理解数据对生成能力的提升效果显著优于生成数据本身。通过系统性实验揭示了理解与生成任务的协同效应,但理解数据对整体性能的提升更具决定性作用。基于此,研究团队训练了 MetaMorph 统一模型,在保持语言模型预训练优势的同时,实现了文本与视觉标记的联合预测,在视觉问答、图像生成等多任务上达到领先水平。该模型能够有效利用大语言模型的知识储备进行跨模态推理,例如根据"君主斑蝶变态发育的结果"生成蝴蝶图像,验证了预训练语言模型潜在的"先验视觉能力"可通过指令调整高效激活。这项工作为构建兼具理解与生成能力的多模态模型提供了轻量级解决方案,证明了通过指令微调即可挖掘大语言模型的多模态潜力。
论文简介: 由 FAIR、Meta、纽约大学、Meta Reality Labs 和普林斯顿大学等机构提出了 MetaMorph,该工作通过 Visual-Predictive Instruction Tuning (VPiT) 方法,将视觉指令调整扩展为支持多模态生成任务。研究发现视觉生成能力是视觉理解提升的自然副产品,仅需少量生成数据即可解锁,且理解数据对生成能力的提升效果显著优于生成数据本身。通过系统性实验揭示了理解与生成任务的协同效应,但理解数据对整体性能的提升更具决定性作用。基于此,研究团队训练了 MetaMorph 统一模型,在保持语言模型预训练优势的同时,实现了文本与视觉标记的联合预测,在视觉问答、图像生成等多任务上达到领先水平。该模型能够有效利用大语言模型的知识储备进行跨模态推理,例如根据"君主斑蝶变态发育的结果"生成蝴蝶图像,验证了预训练语言模型潜在的"先验视觉能力"可通过指令调整高效激活。这项工作为构建兼具理解与生成能力的多模态模型提供了轻量级解决方案,证明了通过指令微调即可挖掘大语言模型的多模态潜力。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.24
✨ AIGC 新范式:更通用、更可控的生成模型
在 AIGC 领域,Meta 的研究方向聚焦于构建更通用、高效和可定制的生成模型,并探索更科学的评估方法。
Adaptive Caching for Faster Video Generation with Diffusion Transformers
 论文简介: 由Meta AI和Stony Brook University等机构提出了Adaptive Caching(AdaCache),该工作通过自适应缓存残差计算并动态调整缓存策略,根据视频内容复杂度分配计算资源,从而加速视频生成扩散变换器(DiTs)的推理过程。研究发现不同视频对计算资源的需求存在显著差异,AdaCache通过测量相邻扩散步骤间特征变化的速率,动态决定缓存时长,减少冗余计算。同时引入Motion Regularization(MoReg)模块,利用视频运动信息调整缓存强度,对高运动场景增加计算密度以保障质量。该方法无需重新训练模型,可作为插件无缝集成至Open-Sora、Latte等主流视频生成框架。实验显示,在720p-2s视频生成任务中,AdaCache实现最高4.7倍加速(从54秒降至11.5秒),同时保持甚至提升VBench质量评分(83.40% vs 基线84.16%),在多GPU环境下仍保持高效。用户研究证实其生成质量与基线难以区分的比例达41%,显著优于现有加速方案。该方法为长视频生成和商业部署提供了低延迟高保真的解决方案。
论文简介: 由Meta AI和Stony Brook University等机构提出了Adaptive Caching(AdaCache),该工作通过自适应缓存残差计算并动态调整缓存策略,根据视频内容复杂度分配计算资源,从而加速视频生成扩散变换器(DiTs)的推理过程。研究发现不同视频对计算资源的需求存在显著差异,AdaCache通过测量相邻扩散步骤间特征变化的速率,动态决定缓存时长,减少冗余计算。同时引入Motion Regularization(MoReg)模块,利用视频运动信息调整缓存强度,对高运动场景增加计算密度以保障质量。该方法无需重新训练模型,可作为插件无缝集成至Open-Sora、Latte等主流视频生成框架。实验显示,在720p-2s视频生成任务中,AdaCache实现最高4.7倍加速(从54秒降至11.5秒),同时保持甚至提升VBench质量评分(83.40% vs 基线84.16%),在多GPU环境下仍保持高效。用户研究证实其生成质量与基线难以区分的比例达41%,显著优于现有加速方案。该方法为长视频生成和商业部署提供了低延迟高保真的解决方案。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.1071
DIMCIM: A Quantitative Evaluation Framework for Default-mode Diversity and Generalization in Text-to-Image Generative Models
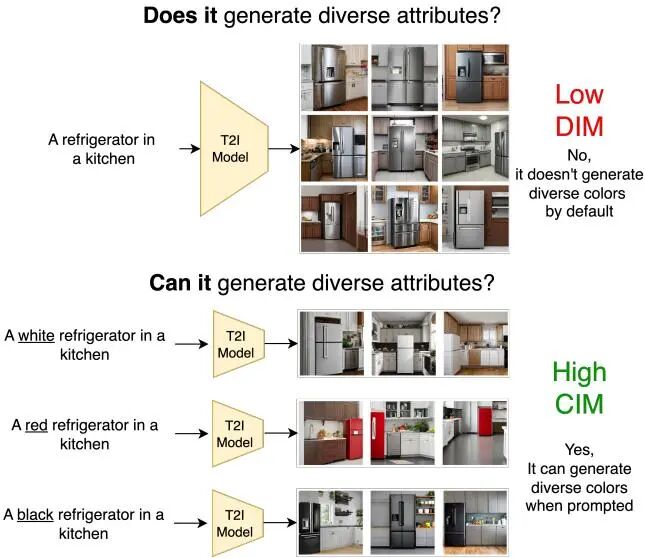 论文简介: 由纽约大学、Meta FAIR等机构提出了DIMCIM,该工作提出了一种全新的文本到图像生成模型评估框架,通过"Does-It Metric"和"Can-It Metric"两个核心指标,分别量化模型在无显式提示时的默认模式多样性(能否生成符合预期属性的多样化图像)和显式提示下的泛化能力(能否根据特定属性生成多样化图像)。研究团队基于COCO数据集构建了COCO-DIMCIM基准,利用LLaMA-3.1生成包含30个概念、494个属性、14,641条提示的评估数据集,并通过VQAScore实现属性-概念得分计算。实验发现模型规模增大(从1.5B到8.1B参数)会显著提升泛化能力(Can-It Metric从0.299升至0.374)但降低默认模式多样性(Does-It Metric从0.815降至0.799),揭示了两者间的权衡关系。通过分析发现模型存在"显式提示失败但默认生成正常"的新现象,如LDM3.5L能生成闭合翅膀的鸟但无法响应"closed-wings"提示。研究还证实训练数据分布与默认模式多样性存在0.85的强相关性,但某些属性(如飞行中的鸟)在训练数据中占比高却未被模型正确生成,表明单纯增加训练数据可能无法解决所有多样性问题。该框架为评估生成模型的多样性提供了可解释、可扩展的解决方案,有助于推动更均衡的模型开发。
论文简介: 由纽约大学、Meta FAIR等机构提出了DIMCIM,该工作提出了一种全新的文本到图像生成模型评估框架,通过"Does-It Metric"和"Can-It Metric"两个核心指标,分别量化模型在无显式提示时的默认模式多样性(能否生成符合预期属性的多样化图像)和显式提示下的泛化能力(能否根据特定属性生成多样化图像)。研究团队基于COCO数据集构建了COCO-DIMCIM基准,利用LLaMA-3.1生成包含30个概念、494个属性、14,641条提示的评估数据集,并通过VQAScore实现属性-概念得分计算。实验发现模型规模增大(从1.5B到8.1B参数)会显著提升泛化能力(Can-It Metric从0.299升至0.374)但降低默认模式多样性(Does-It Metric从0.815降至0.799),揭示了两者间的权衡关系。通过分析发现模型存在"显式提示失败但默认生成正常"的新现象,如LDM3.5L能生成闭合翅膀的鸟但无法响应"closed-wings"提示。研究还证实训练数据分布与默认模式多样性存在0.85的强相关性,但某些属性(如飞行中的鸟)在训练数据中占比高却未被模型正确生成,表明单纯增加训练数据可能无法解决所有多样性问题。该框架为评估生成模型的多样性提供了可解释、可扩展的解决方案,有助于推动更均衡的模型开发。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.2617
Generating Multi-Image Synthetic Data for Text-to-Image Customization
 论文简介: 由卡内基梅隆大学和Meta提出了生成多图像合成数据用于文本到图像定制化的方法,该工作通过构建包含同一物体在不同光照、姿态和背景下的多视角合成数据集SynCD,训练出能够利用参考图像精细特征的编码器模型,并提出归一化文本与图像引导向量的推理技术,显著提升了定制化生成的图像质量与身份一致性。研究团队首先利用文本到图像模型和3D数据集生成带掩码共享注意力(MSA)机制的多视角一致图像,并通过Objaverse资产的深度引导确保刚性物体的多视角一致性,最终筛选出约9.5万组高质量数据。基于SynCD训练的扩散模型通过共享注意力机制将参考图像特征注入生成过程,推理阶段通过归一化图像与文本引导向量强度解决了过曝问题。实验显示该方法在DreamBooth基准测试中,使用3B参数模型时几何平均得分达0.838,超越JeDi(0.780)和IP-Adapter(0.704)等主流方法,在人类偏好测试中也获得68.19%的总体优势。该研究突破了传统单图像训练的数据瓶颈,为文本到图像模型的高效定制化提供了新范式。
论文简介: 由卡内基梅隆大学和Meta提出了生成多图像合成数据用于文本到图像定制化的方法,该工作通过构建包含同一物体在不同光照、姿态和背景下的多视角合成数据集SynCD,训练出能够利用参考图像精细特征的编码器模型,并提出归一化文本与图像引导向量的推理技术,显著提升了定制化生成的图像质量与身份一致性。研究团队首先利用文本到图像模型和3D数据集生成带掩码共享注意力(MSA)机制的多视角一致图像,并通过Objaverse资产的深度引导确保刚性物体的多视角一致性,最终筛选出约9.5万组高质量数据。基于SynCD训练的扩散模型通过共享注意力机制将参考图像特征注入生成过程,推理阶段通过归一化图像与文本引导向量强度解决了过曝问题。实验显示该方法在DreamBooth基准测试中,使用3B参数模型时几何平均得分达0.838,超越JeDi(0.780)和IP-Adapter(0.704)等主流方法,在人类偏好测试中也获得68.19%的总体优势。该研究突破了传统单图像训练的数据瓶颈,为文本到图像模型的高效定制化提供了新范式。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.437
An Empirical Study of Autoregressive Pre-training from Videos
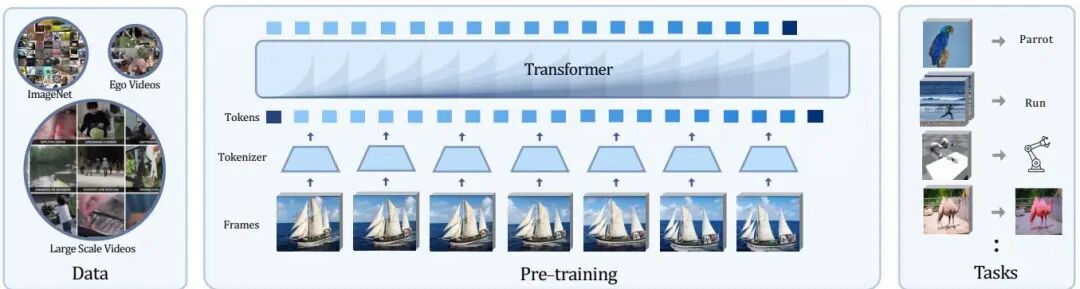 论文简介: 由Meta FAIR和加州大学伯克利分校的研究人员提出了Toto自回归视频预训练框架,该工作通过将视频视为视觉token序列并训练Transformer模型预测未来token,在超大规模无标签视频和图像数据上进行预训练,探索了视频自回归建模在多任务视觉表征学习中的潜力。研究团队构建了包含120M/280M/1.1B参数的模型体系,采用dVAE进行离散token化,通过因果注意力机制在4K token上下文中进行next token预测,预训练数据包含YouTube、Ego4D等来源的超10万小时视频和2.5万亿视觉token。在ImageNet分类、Kinetics动作识别、Ego4D动作预测、DAVIS视频分割、机器人操作等10余项任务中验证了模型有效性,发现middle layer特征在decoder-only架构中表现最佳,attention pooling显著优于average pooling。实验表明,尽管缺乏显式归纳偏置,该方法在生成式视觉表征任务中展现出与对比学习方法相当的竞争力,其中1.1B参数模型在ImageNet上达到75.3% top-1准确率,超越同等规模的iGPT模型。研究还揭示了视觉自回归模型与语言模型相似但更慢的扩展规律,其loss下降速度为L(C)=7.32⋅C−0.0378,低于GPT-3的扩展系数。该工作为视频驱动的通用视觉表征学习提供了系统性实证基础,验证了自回归范式在视觉领域的可扩展性和任务普适性。
论文简介: 由Meta FAIR和加州大学伯克利分校的研究人员提出了Toto自回归视频预训练框架,该工作通过将视频视为视觉token序列并训练Transformer模型预测未来token,在超大规模无标签视频和图像数据上进行预训练,探索了视频自回归建模在多任务视觉表征学习中的潜力。研究团队构建了包含120M/280M/1.1B参数的模型体系,采用dVAE进行离散token化,通过因果注意力机制在4K token上下文中进行next token预测,预训练数据包含YouTube、Ego4D等来源的超10万小时视频和2.5万亿视觉token。在ImageNet分类、Kinetics动作识别、Ego4D动作预测、DAVIS视频分割、机器人操作等10余项任务中验证了模型有效性,发现middle layer特征在decoder-only架构中表现最佳,attention pooling显著优于average pooling。实验表明,尽管缺乏显式归纳偏置,该方法在生成式视觉表征任务中展现出与对比学习方法相当的竞争力,其中1.1B参数模型在ImageNet上达到75.3% top-1准确率,超越同等规模的iGPT模型。研究还揭示了视觉自回归模型与语言模型相似但更慢的扩展规律,其loss下降速度为L(C)=7.32⋅C−0.0378,低于GPT-3的扩展系数。该工作为视频驱动的通用视觉表征学习提供了系统性实证基础,验证了自回归范式在视觉领域的可扩展性和任务普适性。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.385
UniVG: A Generalist Diffusion Model for Unified Image Generation and Editing
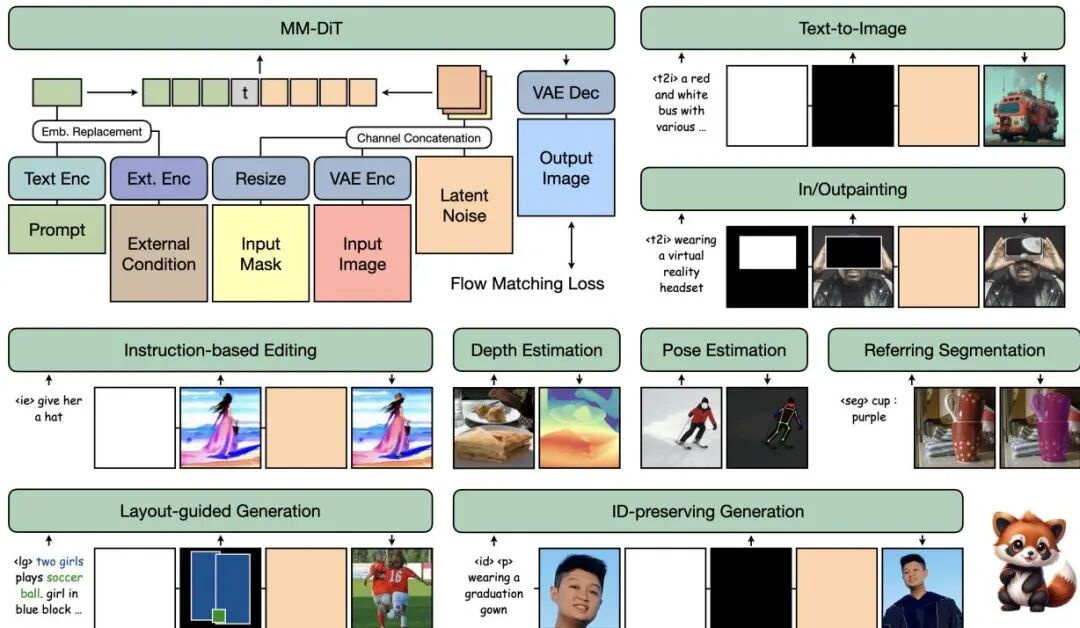 论文简介: 由Meta和Apple等机构提出了UniVG,该工作提出了一种通用扩散模型,通过统一多模态输入实现文本生成图像、修复、指令编辑、身份保留生成、布局引导生成、深度估计和指代表分割等多样化图像生成任务。UniVG基于轻量级改进的MM-DiT架构,将图像潜在特征、噪声和掩码沿通道维度拼接为定长序列,通过嵌入替换注入外部条件实现灵活控制。研究团队通过系统性实验揭示了任务协同效应:指令编辑与文本生成可共存且无性能损耗,辅助任务(如深度估计)能增强编辑能力,并提出三阶段渐进训练策略(先文本生成预训练,再引入多任务混合训练,最后加入身份保留微调)。实验显示,UniVG在GenEval(0.70)、CompBench等基准上超越FLUX.1-dev(0.66)等专用模型,并在指令编辑(MagicBrush CLIP-T达29.5)、身份保留生成(Unsplash-50 ID相似度0.329)等任务中优于OmniGen和OneDiffusion等通用模型。特别在推理效率上,UniVG通过通道维度特征融合策略,在512×512分辨率下编辑任务耗时(10.4秒)显著低于OmniGen(36.8秒),同时保持3.7B参数规模。该工作通过模型设计、数据混合策略和训练方法的系统优化,验证了单模型统一多任务的可行性,为通用生成模型开发提供了重要参考。
论文简介: 由Meta和Apple等机构提出了UniVG,该工作提出了一种通用扩散模型,通过统一多模态输入实现文本生成图像、修复、指令编辑、身份保留生成、布局引导生成、深度估计和指代表分割等多样化图像生成任务。UniVG基于轻量级改进的MM-DiT架构,将图像潜在特征、噪声和掩码沿通道维度拼接为定长序列,通过嵌入替换注入外部条件实现灵活控制。研究团队通过系统性实验揭示了任务协同效应:指令编辑与文本生成可共存且无性能损耗,辅助任务(如深度估计)能增强编辑能力,并提出三阶段渐进训练策略(先文本生成预训练,再引入多任务混合训练,最后加入身份保留微调)。实验显示,UniVG在GenEval(0.70)、CompBench等基准上超越FLUX.1-dev(0.66)等专用模型,并在指令编辑(MagicBrush CLIP-T达29.5)、身份保留生成(Unsplash-50 ID相似度0.329)等任务中优于OmniGen和OneDiffusion等通用模型。特别在推理效率上,UniVG通过通道维度特征融合策略,在512×512分辨率下编辑任务耗时(10.4秒)显著低于OmniGen(36.8秒),同时保持3.7B参数规模。该工作通过模型设计、数据混合策略和训练方法的系统优化,验证了单模型统一多任务的可行性,为通用生成模型开发提供了重要参考。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.251
👤 数字“人”的精雕师:高保真虚拟化身与人体建模
创建逼真的数字人是元宇宙愿景的核心组成部分。Meta 在人体姿态、形状、外观乃至交互的建模方面取得了令人瞩目的进展。
Generative Modeling of Shape-Dependent Self-Contact Human Poses
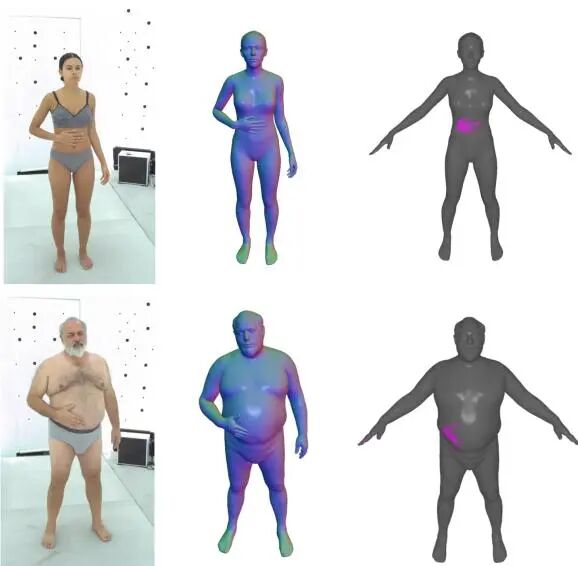 论文简介: 由Meta、东京大学和KAIST等机构提出了Generative Modeling of Shape-Dependent Self-Contact Human Poses,该工作针对人体自接触姿态建模中身体形状依赖性被忽视的问题,构建了包含383K个自接触姿态的Goliath-SC数据集,并提出了基于潜在扩散模型的形状条件生成方法。研究发现,不同BMI人群的"揉肚子"等自接触动作存在显著差异,现有数据集因缺乏精确身体形状参数和多样姿态限制了相关研究。Goliath-SC通过220个摄像头的多视角捕捉系统,实现了130名被试者在自然动作指令下的连续自接触姿态采集,其SMPL-X参数化表示提供了精确的身体形状描述。基于该数据集,研究团队开发了PAPoseDiff扩散模型,通过身体部位感知的自注意力机制,在潜在空间中建模姿态与形状的关联性,特别强化了手部、面部与躯干的交互关系。该模型在生成任务中相比VAE和传统扩散模型取得53%的FID指标提升,并在单视角姿态估计优化中,通过将初始SMPL-X估计与2D关键点观测结合,有效解决了手部穿透和接触错误问题。实验表明,该方法在未见被试者数据上将平均关节误差从58mm降低至31.8mm,显著优于SMPLer-X等最先进回归模型。研究揭示了形状条件生成先验在自接触姿态建模中的关键作用,为人体动作分析提供了新的数据基础和建模范式。
论文简介: 由Meta、东京大学和KAIST等机构提出了Generative Modeling of Shape-Dependent Self-Contact Human Poses,该工作针对人体自接触姿态建模中身体形状依赖性被忽视的问题,构建了包含383K个自接触姿态的Goliath-SC数据集,并提出了基于潜在扩散模型的形状条件生成方法。研究发现,不同BMI人群的"揉肚子"等自接触动作存在显著差异,现有数据集因缺乏精确身体形状参数和多样姿态限制了相关研究。Goliath-SC通过220个摄像头的多视角捕捉系统,实现了130名被试者在自然动作指令下的连续自接触姿态采集,其SMPL-X参数化表示提供了精确的身体形状描述。基于该数据集,研究团队开发了PAPoseDiff扩散模型,通过身体部位感知的自注意力机制,在潜在空间中建模姿态与形状的关联性,特别强化了手部、面部与躯干的交互关系。该模型在生成任务中相比VAE和传统扩散模型取得53%的FID指标提升,并在单视角姿态估计优化中,通过将初始SMPL-X估计与2D关键点观测结合,有效解决了手部穿透和接触错误问题。实验表明,该方法在未见被试者数据上将平均关节误差从58mm降低至31.8mm,显著优于SMPLer-X等最先进回归模型。研究揭示了形状条件生成先验在自接触姿态建模中的关键作用,为人体动作分析提供了新的数据基础和建模范式。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.876
HairCUP: Hair Compositional Universal Prior for 3D Gaussian Avatars
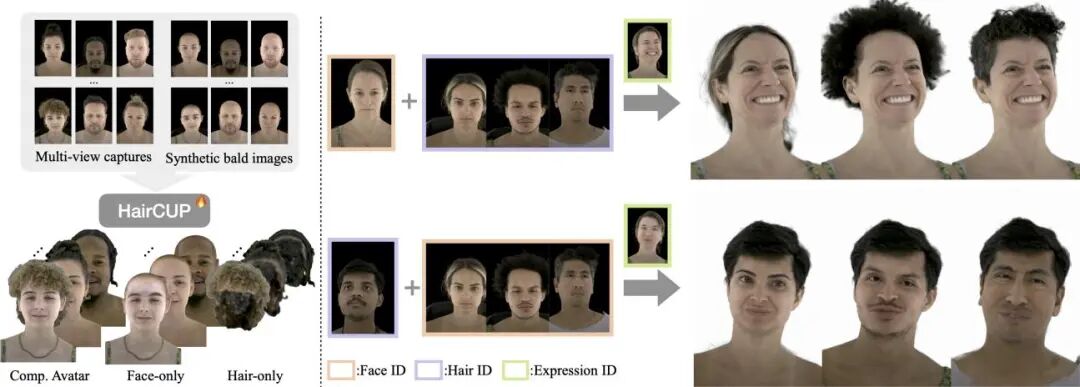 论文简介: 由韩国首尔大学与Meta Codec Avatars Lab提出HairCUP,该工作通过显式建模面部与头发的组成性,构建了首个支持跨身份发型迁移的3D高斯头像通用先验模型。针对传统整体建模难以分离面部与头发特征的问题,研究者创新性地构建了合成无发数据生成管道:通过扩散先验估计无发几何与纹理,将原始多视角数据与渲染的无发网格合成配对数据集。基于该数据集,模型采用双编码器结构分别学习面部与头发的独立潜空间,并通过身份条件超网络实现跨身份组合。核心贡献包括:基于UV纹理映射的3D高斯头发表示方法,支持相对头皮坐标系的发型迁移;边界自适应的分割损失函数,确保面部与头发区域的自然过渡;以及基于合成数据训练的通用先验模型,仅需少量单视角数据即可实现高保真人像微调。实验表明,该方法在面部与头发细节重建质量上超越DELTA等基线方法,LPIPS指标降低54%,PSNR提升14%,并首次实现无刚性边界的自然发型迁移效果。该研究为个性化3D头像生成提供了新的技术路径,但对动态发型的建模能力仍有待提升。
论文简介: 由韩国首尔大学与Meta Codec Avatars Lab提出HairCUP,该工作通过显式建模面部与头发的组成性,构建了首个支持跨身份发型迁移的3D高斯头像通用先验模型。针对传统整体建模难以分离面部与头发特征的问题,研究者创新性地构建了合成无发数据生成管道:通过扩散先验估计无发几何与纹理,将原始多视角数据与渲染的无发网格合成配对数据集。基于该数据集,模型采用双编码器结构分别学习面部与头发的独立潜空间,并通过身份条件超网络实现跨身份组合。核心贡献包括:基于UV纹理映射的3D高斯头发表示方法,支持相对头皮坐标系的发型迁移;边界自适应的分割损失函数,确保面部与头发区域的自然过渡;以及基于合成数据训练的通用先验模型,仅需少量单视角数据即可实现高保真人像微调。实验表明,该方法在面部与头发细节重建质量上超越DELTA等基线方法,LPIPS指标降低54%,PSNR提升14%,并首次实现无刚性边界的自然发型迁移效果。该研究为个性化3D头像生成提供了新的技术路径,但对动态发型的建模能力仍有待提升。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.841
ATLAS: Decoupling Skeletal and Shape Parameters for Expressive Parametric Human Modeling
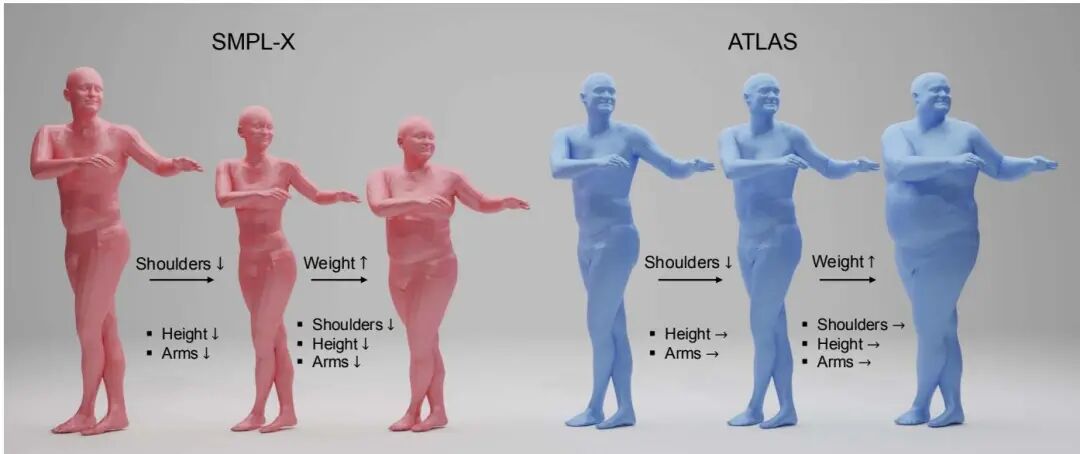 论文简介: 由Meta和卡内基梅隆大学等机构提出了ATLAS,该工作通过显式解耦骨骼和形状参数构建了高保真人体模型。ATLAS采用60万次高分辨率扫描数据训练,构建了包含11.5万顶点的模板网格和77个关节的解剖学骨架,通过分离形状基和骨骼基实现了对身体属性的精确控制。模型引入了76个可独立调节的骨骼属性(包括15个身体部位缩放和61个骨长参数),允许在保持表面细节的同时单独调整肩宽、臂长等内部骨骼特征。针对传统线性姿态校正的局限性,研究团队提出稀疏非线性姿态校正机制,通过局部非线性操作与地理初始化的稀疏线性映射结合,在保持关节局部影响的同时提升复杂姿态下的形变真实性。实验显示,ATLAS在3DBodyTex数据集上以32个参数实现比SMPL-X低21.6%的顶点误差,在Goliath测试集上达到2.34mm的拟合精度。研究还开发了基于关键点解耦优化的单图像拟合框架,通过先拟合骨骼姿态再优化表面形状的两阶段策略,结合相对深度和边缘梯度约束,使单目重建误差较SMPLify-X降低37%。该模型在保持实时性能(高分辨率版本GPU推理5.37ms)的同时,为虚拟人建模、动作捕捉等应用提供了更精准的参数化控制方案。
论文简介: 由Meta和卡内基梅隆大学等机构提出了ATLAS,该工作通过显式解耦骨骼和形状参数构建了高保真人体模型。ATLAS采用60万次高分辨率扫描数据训练,构建了包含11.5万顶点的模板网格和77个关节的解剖学骨架,通过分离形状基和骨骼基实现了对身体属性的精确控制。模型引入了76个可独立调节的骨骼属性(包括15个身体部位缩放和61个骨长参数),允许在保持表面细节的同时单独调整肩宽、臂长等内部骨骼特征。针对传统线性姿态校正的局限性,研究团队提出稀疏非线性姿态校正机制,通过局部非线性操作与地理初始化的稀疏线性映射结合,在保持关节局部影响的同时提升复杂姿态下的形变真实性。实验显示,ATLAS在3DBodyTex数据集上以32个参数实现比SMPL-X低21.6%的顶点误差,在Goliath测试集上达到2.34mm的拟合精度。研究还开发了基于关键点解耦优化的单图像拟合框架,通过先拟合骨骼姿态再优化表面形状的两阶段策略,结合相对深度和边缘梯度约束,使单目重建误差较SMPLify-X降低37%。该模型在保持实时性能(高分辨率版本GPU推理5.37ms)的同时,为虚拟人建模、动作捕捉等应用提供了更精准的参数化控制方案。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.2270
Gaze-Language Alignment for Zero-Shot Prediction of Visual Search Targets from Human Gaze Scanpaths
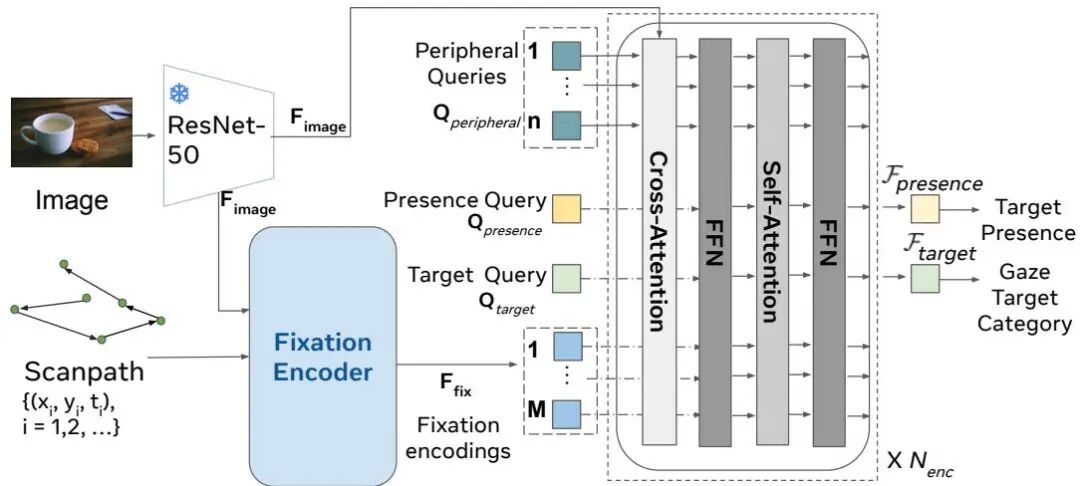 论文简介: 由Stony Brook University和Meta Reality Labs Research等机构提出了Gaze-Language Alignment Model (GLAM),该工作提出了一种新型视觉-语言模型GLAM,通过结合眼动轨迹编码和语言描述对齐,实现对无标注新类别目标的零样本预测。研究团队创新性地设计了包含中央-周边视觉信息的眼动编码器,通过GLAD对齐策略将眼动轨迹与大语言模型生成的搜索描述进行跨模态对齐,在零样本设置下准确率较传统对比学习提升近三分之一,甚至超越全监督基线模型。GLAM通过双编码器架构将眼动扫描路径与目标类别描述映射到共享语义空间,其核心贡献在于:1)首创性实现零样本眼动目标预测,突破传统分类模型的类别限制;2)提出GLAD训练策略,通过预训练阶段注入2500+类别的搜索过程描述知识;3)眼动编码器创新性融合中央凹与周边视觉信息,提升空间上下文建模能力;4)在COCO-Search18数据集上全面超越现有方法,在零样本和全监督设置下均达到SOTA性能。该模型为AR/VR等交互系统提供了突破性技术路径,使眼动预测能力可扩展至无限新类别目标,为智能交互系统理解用户意图提供了新范式。
论文简介: 由Stony Brook University和Meta Reality Labs Research等机构提出了Gaze-Language Alignment Model (GLAM),该工作提出了一种新型视觉-语言模型GLAM,通过结合眼动轨迹编码和语言描述对齐,实现对无标注新类别目标的零样本预测。研究团队创新性地设计了包含中央-周边视觉信息的眼动编码器,通过GLAD对齐策略将眼动轨迹与大语言模型生成的搜索描述进行跨模态对齐,在零样本设置下准确率较传统对比学习提升近三分之一,甚至超越全监督基线模型。GLAM通过双编码器架构将眼动扫描路径与目标类别描述映射到共享语义空间,其核心贡献在于:1)首创性实现零样本眼动目标预测,突破传统分类模型的类别限制;2)提出GLAD训练策略,通过预训练阶段注入2500+类别的搜索过程描述知识;3)眼动编码器创新性融合中央凹与周边视觉信息,提升空间上下文建模能力;4)在COCO-Search18数据集上全面超越现有方法,在零样本和全监督设置下均达到SOTA性能。该模型为AR/VR等交互系统提供了突破性技术路径,使眼动预测能力可扩展至无限新类别目标,为智能交互系统理解用户意图提供了新范式。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.2565
PHD: Personalized 3D Human Body Fitting with Point Diffusion
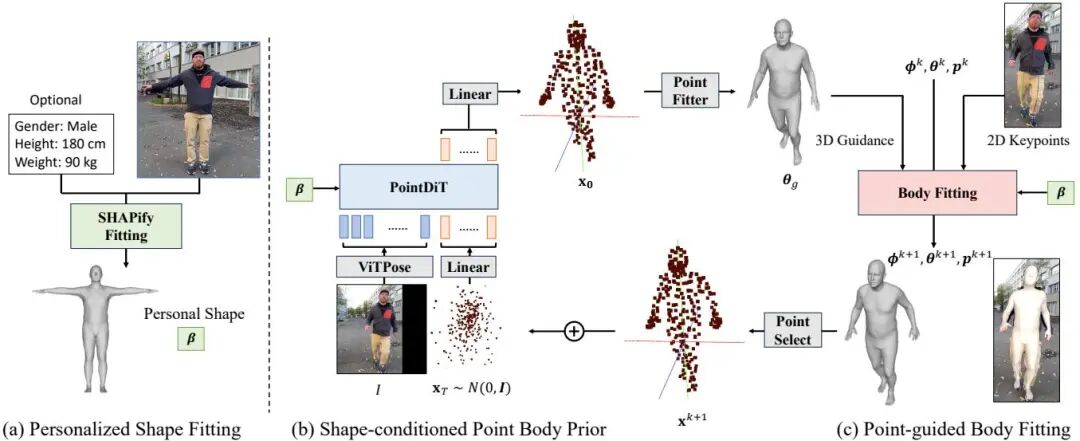 论文简介: 由 ETH Zurich 和 Meta Reality Labs 等机构提出了 PHD,该工作提出了一种基于点扩散的个性化3D人体姿态拟合方法,通过解耦人体形状与姿态估计流程,显著提升了单目视频中的3D姿态精度。PHD 创新性地将传统广义模型解耦为形状校准和姿态拟合两个阶段:首先通过 SHAPify 模块从单帧图像中估计用户个性化形状参数,并可结合身高体重信息进一步优化;随后在姿态拟合阶段引入基于点扩散的3D姿态先验 PointDiT,该模块采用扩散Transformer架构,通过点蒸馏采样损失实现形状条件下的表面点云生成,有效克服了传统方法过度依赖2D约束导致的3D姿态失真问题。实验表明,PHD 在 EMDB 数据集上实现了绝对姿态精度(C-MPJPE)115.8mm 的 SOTA 结果,较 ScoreHMR 提升 44.6%,在保持高效计算的同时,其插件式设计可无缝集成于现有3D姿态估计框架。该方法通过显式建模用户个性化特征,在解决运动模糊、遮挡等挑战性场景时展现出显著优势,为AR/VR等需要精确人体姿态的场景提供了新范式。
论文简介: 由 ETH Zurich 和 Meta Reality Labs 等机构提出了 PHD,该工作提出了一种基于点扩散的个性化3D人体姿态拟合方法,通过解耦人体形状与姿态估计流程,显著提升了单目视频中的3D姿态精度。PHD 创新性地将传统广义模型解耦为形状校准和姿态拟合两个阶段:首先通过 SHAPify 模块从单帧图像中估计用户个性化形状参数,并可结合身高体重信息进一步优化;随后在姿态拟合阶段引入基于点扩散的3D姿态先验 PointDiT,该模块采用扩散Transformer架构,通过点蒸馏采样损失实现形状条件下的表面点云生成,有效克服了传统方法过度依赖2D约束导致的3D姿态失真问题。实验表明,PHD 在 EMDB 数据集上实现了绝对姿态精度(C-MPJPE)115.8mm 的 SOTA 结果,较 ScoreHMR 提升 44.6%,在保持高效计算的同时,其插件式设计可无缝集成于现有3D姿态估计框架。该方法通过显式建模用户个性化特征,在解决运动模糊、遮挡等挑战性场景时展现出显著优势,为AR/VR等需要精确人体姿态的场景提供了新范式。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.1497
InteractAvatar: Modeling Hand-Face Interaction in Photorealistic Avatars with Deformable Gaussians
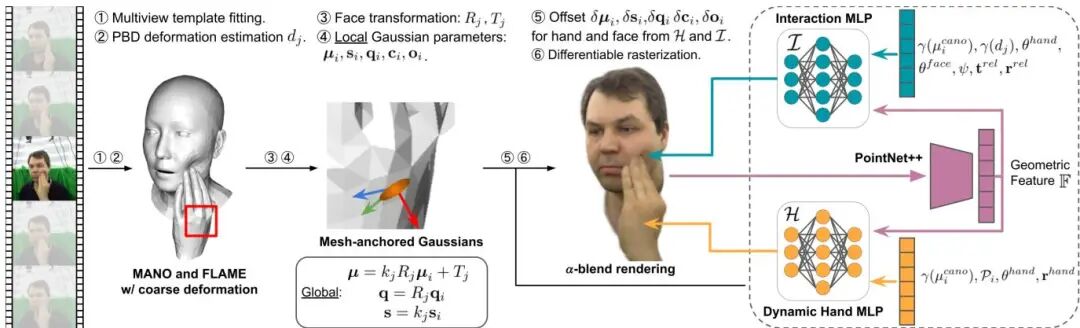 论文简介: 由Brown University和Meta Reality Labs等机构提出了InteractAvatar,该工作首次实现了基于可变形高斯点的动态手部建模与手脸交互渲染。核心创新包括:1)动态高斯手模型通过将高斯核锚定到手部模板网格并引入姿态相关的几何/外观调整模块,精准捕捉关节运动产生的皱纹、阴影等细节;2)手脸交互模块通过物理模拟与可学习的MLP网络结合,实时优化面部受手部接触产生的非刚性形变与阴影变化;3)构建首个支持跨身份手脸动作迁移的高保真数字人系统。实验基于DECAF数据集验证,在新视角合成、自我重演和跨角色重演任务中,PSNR分别达到29.85/28.17,相比基线模型提升显著。该方法突破了传统数字人模型忽略手部交互的局限,为AR/VR、虚拟社交等场景提供更自然的沉浸式体验。
论文简介: 由Brown University和Meta Reality Labs等机构提出了InteractAvatar,该工作首次实现了基于可变形高斯点的动态手部建模与手脸交互渲染。核心创新包括:1)动态高斯手模型通过将高斯核锚定到手部模板网格并引入姿态相关的几何/外观调整模块,精准捕捉关节运动产生的皱纹、阴影等细节;2)手脸交互模块通过物理模拟与可学习的MLP网络结合,实时优化面部受手部接触产生的非刚性形变与阴影变化;3)构建首个支持跨身份手脸动作迁移的高保真数字人系统。实验基于DECAF数据集验证,在新视角合成、自我重演和跨角色重演任务中,PSNR分别达到29.85/28.17,相比基线模型提升显著。该方法突破了传统数字人模型忽略手部交互的局限,为AR/VR、虚拟社交等场景提供更自然的沉浸式体验。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.1015
AV-Flow: Transforming Text to Audio-Visual Human-like Interactions
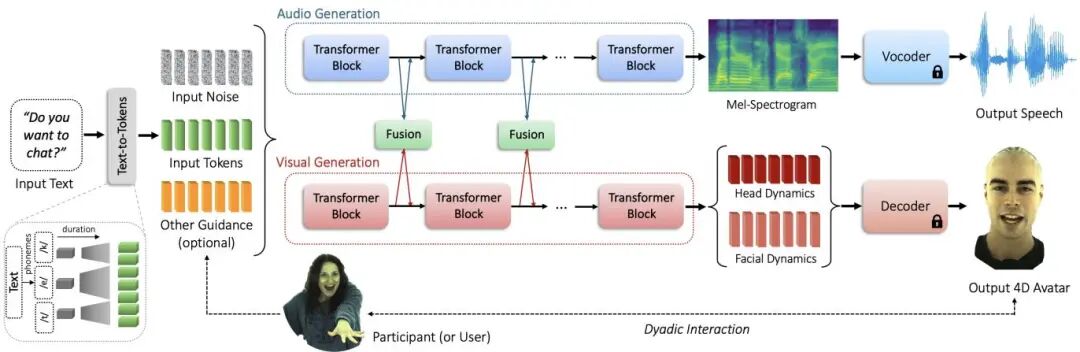 论文简介: 由 Stony Brook University 和 Meta 等机构提出了 AV-Flow,该工作通过创新的视听联合生成架构实现了仅需文本输入即可驱动4D虚拟人物的突破性进展。AV-Flow 采用双流扩散Transformer结构,通过中间高速公路连接实现语音与视觉模态的实时交互,首次实现从纯文本到语音、唇动、表情及头部动作的同步生成。其核心创新在于:1)提出并行扩散Transformer架构,通过流匹配训练目标实现毫秒级实时推理;2)设计跨模态交互机制确保语音韵律与面部动态的精准同步;3)引入对话者视听信号引导机制,使虚拟人物具备主动倾听和情感反馈能力。实验表明,该方法在唇动同步精度(F1值达0.964)、视听对齐度(Beat Alignment Score提升15%)等指标上全面超越VASA-1、Audio2Photoreal等现有方案,推理速度较扩散模型提升3倍。特别在双向对话场景中,模型能根据用户表情实时生成点头、微笑等反馈动作,成功构建具有情感共鸣的交互体验。这项工作突破了传统级联式文本到视听生成的局限,为未来元宇宙交互和AI助手开发提供了全新范式。
论文简介: 由 Stony Brook University 和 Meta 等机构提出了 AV-Flow,该工作通过创新的视听联合生成架构实现了仅需文本输入即可驱动4D虚拟人物的突破性进展。AV-Flow 采用双流扩散Transformer结构,通过中间高速公路连接实现语音与视觉模态的实时交互,首次实现从纯文本到语音、唇动、表情及头部动作的同步生成。其核心创新在于:1)提出并行扩散Transformer架构,通过流匹配训练目标实现毫秒级实时推理;2)设计跨模态交互机制确保语音韵律与面部动态的精准同步;3)引入对话者视听信号引导机制,使虚拟人物具备主动倾听和情感反馈能力。实验表明,该方法在唇动同步精度(F1值达0.964)、视听对齐度(Beat Alignment Score提升15%)等指标上全面超越VASA-1、Audio2Photoreal等现有方案,推理速度较扩散模型提升3倍。特别在双向对话场景中,模型能根据用户表情实时生成点头、微笑等反馈动作,成功构建具有情感共鸣的交互体验。这项工作突破了传统级联式文本到视听生成的局限,为未来元宇宙交互和AI助手开发提供了全新范式。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.323
🚀 效率与应用的探索者
除了追求 SOTA 性能,Meta 也同样关注 AI 技术的实用性和可部署性,致力于让前沿技术能够在资源受限的设备上高效运行。
A Real-world Display Inverse Rendering Dataset
 论文简介: 由POSTECH和Meta的研究团队提出了首个面向显示逆渲染的真实世界数据集,该工作构建了基于LCD显示器和立体偏振相机的成像系统,通过校准显示器背光非线性特性与空间变化参数,实现了近场光照条件下的可控捕获。研究者采集了16个涵盖树脂、陶瓷、金属漆、木材等多样化材质的物体数据,每个物体包含144种单光源照明模式下的偏振图像、高精度地面真实几何数据(精度达0.05mm),以及通过Stokes矢量分解获得的漫反射/镜面反射分离图像。数据集支持合成任意显示模式下的图像,并模拟不同噪声水平,为评估逆渲染方法提供了标准化基准。实验表明,现有光度立体方法(如SDM-UniPS)在法向重建上表现优异(平均角度误差14.896°),但传统逆渲染方法在处理近场照明、背光干扰等显示系统特有挑战时存在显著局限。研究者提出的基线方法通过引入BRDF基表示和不同iable渲染优化,在仅150秒内实现了高质量重光照效果(PSNR 39.33dB,SSIM 0.9821),显著优于现有方法。该数据集填补了显示逆渲染领域缺乏真实世界基准的空白,为探索偏振特性利用、多路复用显示模式优化等方向提供了关键资源。
论文简介: 由POSTECH和Meta的研究团队提出了首个面向显示逆渲染的真实世界数据集,该工作构建了基于LCD显示器和立体偏振相机的成像系统,通过校准显示器背光非线性特性与空间变化参数,实现了近场光照条件下的可控捕获。研究者采集了16个涵盖树脂、陶瓷、金属漆、木材等多样化材质的物体数据,每个物体包含144种单光源照明模式下的偏振图像、高精度地面真实几何数据(精度达0.05mm),以及通过Stokes矢量分解获得的漫反射/镜面反射分离图像。数据集支持合成任意显示模式下的图像,并模拟不同噪声水平,为评估逆渲染方法提供了标准化基准。实验表明,现有光度立体方法(如SDM-UniPS)在法向重建上表现优异(平均角度误差14.896°),但传统逆渲染方法在处理近场照明、背光干扰等显示系统特有挑战时存在显著局限。研究者提出的基线方法通过引入BRDF基表示和不同iable渲染优化,在仅150秒内实现了高质量重光照效果(PSNR 39.33dB,SSIM 0.9821),显著优于现有方法。该数据集填补了显示逆渲染领域缺乏真实世界基准的空白,为探索偏振特性利用、多路复用显示模式优化等方向提供了关键资源。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.1052
EgoAdapt: Adaptive Multisensory Distillation and Policy Learning for Efficient Egocentric Perception
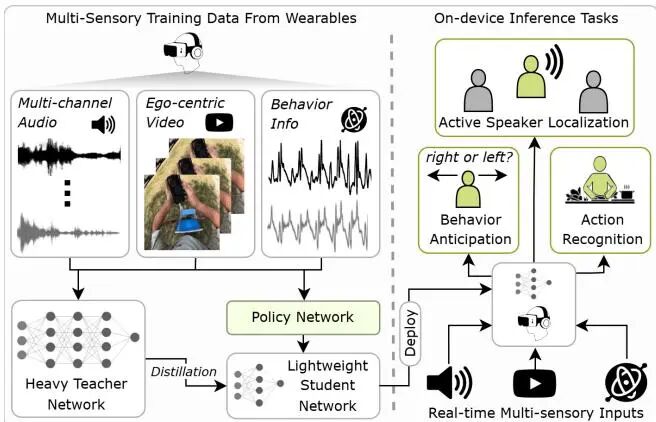 论文简介: 由马里兰大学、Meta Reality Labs等机构提出了EgoAdapt,该工作通过自适应跨模态蒸馏与策略学习实现高效的多模态眼动感知。针对现有感知模型计算成本高、难以部署的问题,EgoAdapt创新性地将轻量化蒸馏模型与动态策略模块结合,通过多模态特征对齐和任务驱动的模态选择机制,在保证性能的同时显著降低计算开销。其核心贡献在于:1)构建统一框架同步优化知识蒸馏与策略决策,利用Gumbel-Softmax采样实现端到端训练;2)设计可扩展的策略网络,通过音频预判、视觉帧筛选和多模态切换适应动作识别、说话人定位及行为预测任务;3)在EPIC-Kitchens、EasyCom等数据集验证,相较SOTA模型减少89.09% GMACs、82.02%参数和9.6倍能耗,同时在动作识别(Top-1准确率提升3.35%)、说话人定位(mAP提升17.91%)等任务保持领先性能。该方法通过动态分配计算资源,在资源受限场景下实现高效精准的多模态感知,为AR/VR设备的实时交互提供新范式。
论文简介: 由马里兰大学、Meta Reality Labs等机构提出了EgoAdapt,该工作通过自适应跨模态蒸馏与策略学习实现高效的多模态眼动感知。针对现有感知模型计算成本高、难以部署的问题,EgoAdapt创新性地将轻量化蒸馏模型与动态策略模块结合,通过多模态特征对齐和任务驱动的模态选择机制,在保证性能的同时显著降低计算开销。其核心贡献在于:1)构建统一框架同步优化知识蒸馏与策略决策,利用Gumbel-Softmax采样实现端到端训练;2)设计可扩展的策略网络,通过音频预判、视觉帧筛选和多模态切换适应动作识别、说话人定位及行为预测任务;3)在EPIC-Kitchens、EasyCom等数据集验证,相较SOTA模型减少89.09% GMACs、82.02%参数和9.6倍能耗,同时在动作识别(Top-1准确率提升3.35%)、说话人定位(mAP提升17.91%)等任务保持领先性能。该方法通过动态分配计算资源,在资源受限场景下实现高效精准的多模态感知,为AR/VR设备的实时交互提供新范式。
PaperScope.ai 解读: https://paperscope.ai/hf/iccv2025.1588
总结
从 Meta 在 ICCV 2025 的论文布局可以看出,其研究正朝着更通用、更高效、更具交互性的方向全面演进。无论是构建宏大的 3D 虚拟世界,还是精雕细琢逼真的数字人,亦或是打造能理解并生成多模态内容的智能体,Meta 都在通过坚实的基础研究,一步步将通往未来的技术蓝图变为现实。让我们共同期待这些研究成果在未来应用中的精彩表现!
本文由 Intern-S1 等 AI 生成!