引言
PaddleOCR-VL 来了!
它是百度飞桨团队最新推出的超轻量视觉语言模型(VLM),以仅 0.9 亿参数的紧凑设计,在全球多模态文档解析评测榜 OmniDocBench v1.5 上以 92.56 分的总成绩荣登榜首,力压 GPT-4o、Gemini-2.5 Pro 和 Qwen2.5-VL 等旗舰模型。

该模型不仅在跨语言文本识别中表现出色,全面超越多款专用 OCR 模型,还在手写文本、竖排文本及历史文档等复杂场景下保持了极高的稳定性和准确率,体现出卓越的泛化能力。
作为百度飞桨 PaddleOCR 团队的最新力作,PaddleOCR-VL 是中国在计算机视觉与多模态理解领域最具影响力的开源项目之一。自开源以来,PaddleOCR 在 GitHub 上已收获超过 58.5k Star,稳居全球 OCR 项目榜首,同时在 Hugging Face 的 Trending 榜单上位列第一。
凭借轻量化设计、卓越的识别精度以及对 100 多种语言的广泛支持,PaddleOCR-VL 正成为文档理解与视觉语言任务中的重要基线模型,吸引全球研究者和开发者进行测试、复现与二次开发。
技术突破:从“看得清”到“看得懂”
协同式双阶段架构
PaddleOCR-VL的强势出圈不是偶然。
其技术突破在于以仅 0.9 亿个参数的超轻量模型,实现了对复杂文档的精准解析,堪称小体量模型在多模态文档处理领域的标杆之作。这一成就得益于其创新的协同式双阶段架构,将布局分析与内容识别有机结合,不仅能高效“看清”文档中的文字、表格、公式和图表,还能深入“看懂”其逻辑结构与语义内容,为文档解析树立了高效、稳定的新范式。
其核心技术由两部分组成:布局分析模块 PP-DocLayoutV2 和内容识别模块 PaddleOCR-VL-0.9B。
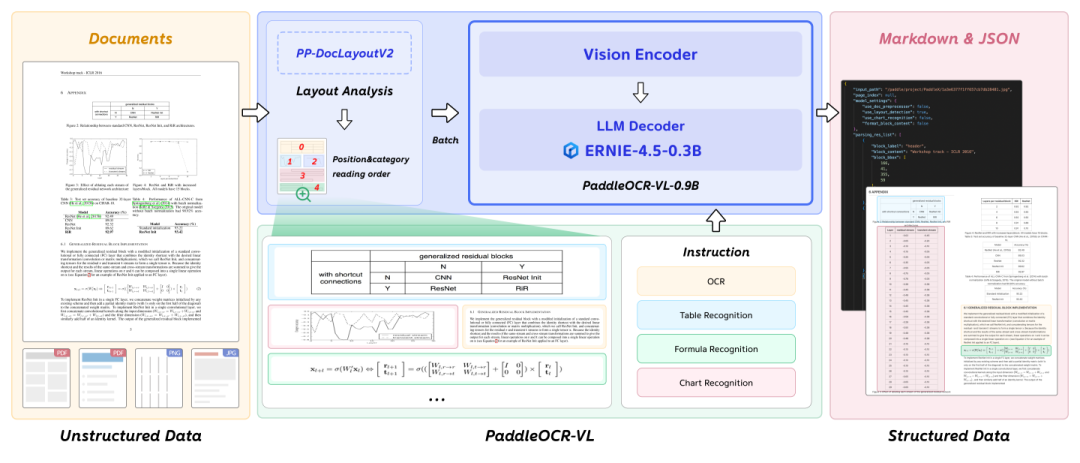
PP-DocLayoutV2 负责解析文档的整体结构,通过高效的元素检测与分类技术,精准定位文本块、表格、公式和图表等元素的位置,并利用指针网络基于空间与语义关系预测合理的阅读顺序。这种设计有效应对了多栏排版和图文混排等复杂场景,避免了传统端到端模型在长序列处理中易出现的顺序错误或内容幻觉问题。
与此同时,PaddleOCR-VL-0.9B 专注于元素内容的精细识别,采用了 NaViT 动态分辨率视觉编码器和 ERNIE-4.5-0.3B 语言模型的组合。前者能够灵活处理任意分辨率的图像,保留高密度文本细节;后者则以轻量化设计实现高效的语义理解与内容生成。此外,通过一个高效的视觉-语言投影器(两层 MLP),视觉特征与语言语义空间得以无缝衔接,从而实现对文字、表格、公式和图表的精准识别,并以结构化的 Markdown、JSON 或 LaTeX 格式输出。
这一架构的协同工作流程清晰而高效:首先,输入复杂的 PDF 文档;PP-DocLayoutV2 迅速完成布局分析,识别各类元素并确定其阅读顺序;随后,文档被拆分为独立的元素图像,交由 PaddleOCR-VL-0.9B 进行内容识别,生成结构化的输出结果;最终,所有结果按阅读顺序整合,形成完整的结构化文档。这种从全局布局到局部内容的解析方式,不仅提升了识别精度,还显著降低了计算开销,使得 PaddleOCR-VL 在资源受限的环境中也能高效运行。
训练数据构建
PaddleOCR-VL 的成功还得益于其在训练数据构建上的创新。通过结合开源数据集、数据合成、网络可访问数据以及内部积累的高质量数据集,团队构建了一个包含超过 3000 万样本的多样化训练集。数据标注过程利用了专家模型 PP-StructureV3 进行初步伪标签生成,并通过 ERNIE-4.5-VL 和 Qwen2.5VL 等高级多模态模型进行优化,确保标签的精准性和一致性。此外,针对复杂场景的性能瓶颈,团队设计了专门的硬样本挖掘机制,通过自动化的评估引擎识别模型在特定任务上的弱点,并利用字体库、CSS 库等资源生成针对性的高难度样本。这种系统化的数据策略为模型的泛化能力和鲁棒性提供了坚实支撑。
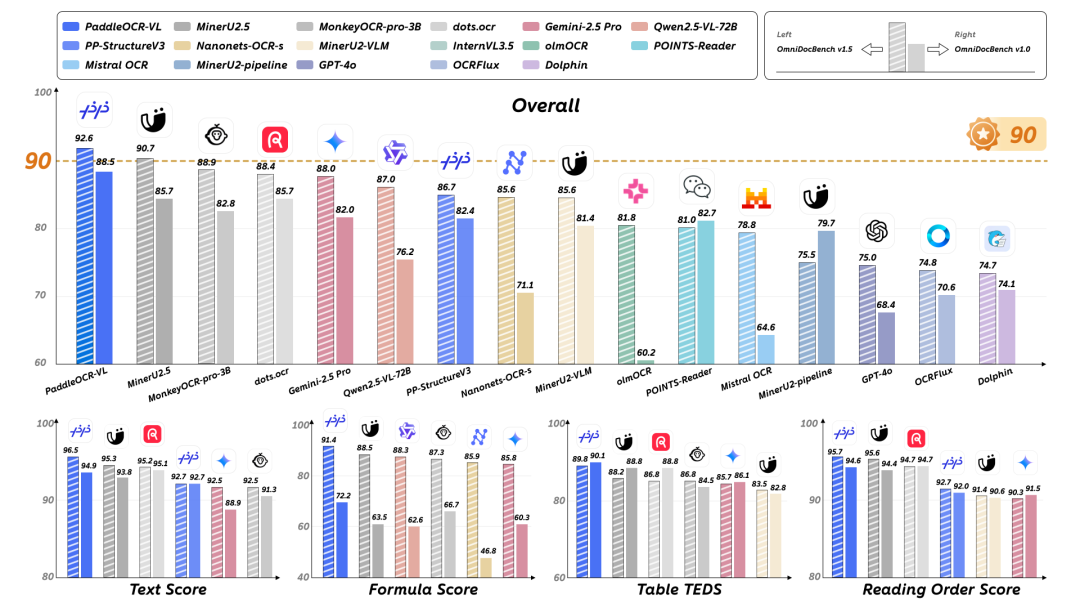
在实际测试中,PaddleOCR-VL 展现了卓越的性能表现。在 OmniDocBench v1.5 评测中,其以 92.56 的总分位居榜首,超越了包括 GPT-4o 和 Qwen2.5-VL 在内的众多旗舰模型,尤其在文本、公式和表格识别等子任务中均取得了领先成绩。其对 109 种语言的支持,以及在手写文本、竖排文本和历史文档等复杂场景下的稳定表现,进一步验证了其强大的跨语言和跨场景泛化能力。
通过将布局分析与内容识别解耦并优化,PaddleOCR-VL 不仅实现了从“看得清”到“看得懂”的飞跃,还以轻量化的设计和高效的推理速度,为实际部署提供了极大的灵活性。无论是在学术研究、财务报表处理,还是古籍数字化等场景中,PaddleOCR-VL 都能以其精准的解析能力和稳定的性能,为用户提供高效的文档理解解决方案。
真实使用场景
接下来,让我们看看这款模型是如何在不同领域“大显神通”的。
学术论文
科研论文通常包含复杂的排版、图表与交叉引用,传统 OCR 很容易在多栏结构或图文混排中“迷路”。
PaddleOCR-VL 通过 布局识别 + 内容解析 的双阶段架构,可精准识别论文中的图表标题、图例与正文段落。

财务报表
面对格式繁多的财务报表,PaddleOCR-VL 能精准识别表格边界与层级结构,将复杂报表转换为结构化数据。
模型不仅识别精度高,还能自动保持字段逻辑与行列对应关系,极大简化企业在财务审计、数据录入等场景的人工整理工作。

古文书法
在古文与书法识别方面,PaddleOCR-VL 也展现了强大的泛化能力。
即使面对竖排、连笔或生僻字较多的书法文稿,模型依然能高保真还原文字内容,为古籍数字化、文献研究和文化遗产保护提供了新的技术路径。
开箱即用:两种体验方式
在线使用
应用体验:https://aistudio.baidu.com/application/detail/98365
只需上传文档或截图(支持拖拽上传),点击 “Parse Document” 即可自动解析整页文档结构;若需对表格、公式或图表等单个元素进行更精细的识别,可切换至 Element-level Recognition 模式。系统支持输出 Markdown、JSON 等结构化结果,并提供可视化展示,方便直观查看解析效果。

本地部署(开发者模式)
PaddleOCR-VL 同样支持本地快速部署,方便开发者在私有环境中进行测试与集成。
(1)快速开始
安装 PaddlePaddle 与 PaddleOCR:
python -m pip install paddlepaddle-gpu==3.2.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
python -m pip install -U "paddleocr[doc-parser]"
python -m pip install https://paddle-whl.bj.bcebos.com/nightly/cu126/safetensors/safetensors-0.6.2.dev0-cp38-abi3-linux_x86_64.whl
(2)基本用法
📍 命令行(CLI)
paddleocr doc_parser -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_ocr_vl_demo.png
🐍 Python API
from paddleocr import PaddleOCRVL
pipeline = PaddleOCRVL()
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_ocr_vl_demo.png")
for res in output:
res.print()
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")
(3)使用 vLLM 加速 VLM 推理
启动推理服务(默认端口 8080):
docker run \
--rm \
--gpus all \
--network host \
ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlex-genai-vllm-server
💡 如果使用 SGLang 推理服务,可替换为同名镜像:
ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlex-genai-vllm-server
调用 CLI 或 Python API 进行加速推理:
命令行:
paddleocr doc_parser \
-i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_ocr_vl_demo.png \
--vl_rec_backend vllm-server \
--vl_rec_server_url http://127.0.0.1:8080
Python API:
from paddleocr import PaddleOCRVL
pipeline = PaddleOCRVL(
vl_rec_backend="vllm-server",
vl_rec_server_url="http://127.0.0.1:8080"
)
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_ocr_vl_demo.png")
for res in output:
res.print()
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")
✅ 提示:
推荐使用 GPU 环境运行,可显著提升推理速度;
结语
让每一个文档,都能“被理解”。
PaddleOCR-VL 不只是一个模型,更像是一台“AI 阅读引擎”。 它让文档解析不再是冷冰冰的字符提取,而是一次智能理解的过程。
未来,随着多模态与大模型技术的融合,PaddleOCR-VL 有望在科研、医疗、财务等更多场景中展现价值,让每一份文档都能被真正理解。
📚 延伸阅读:
PaddleOCR-VL 技术报告:https://ernie.baidu.com/blog/publication/PaddleOCR-VL_Technical_Report.pdf GitHub 项目主页:https://github.com/PaddlePaddle/PaddleOCR huggingface主页:https://huggingface.co/PaddlePaddle
> 本文由 Intern-S1 等 AI 生成,机智流编辑部校对