大会预告

11月19日,2025中国具身智能机器人大会将于深圳举办。聚焦人形机器人、工业具身机器人、机器人模仿学习与强化学习、VLA、世界模型等议题。首批嘉宾已公布,顶会CoRL 2025最高奖项获得者黄思远将出席,更多嘉宾即将揭晓。欢迎报名~
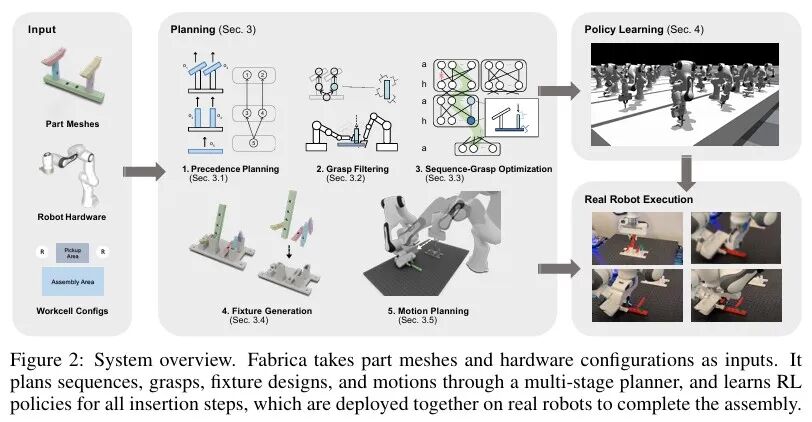
机械臂装配在家庭和工业环境中十分普遍,该领域长期面临一项挑战:如何进行长程规划将CAD模型转化为机器人程序,并在执行密集接触性交互时实现高精度和自适应性。
但目前大多数装配系统仍采用手动编程和特殊设计的基础设施,程序通过刚性控制器重复执行。这导致现有机器人系统往往难以快速适应新的生产需求,且对外部不确定性非常敏感,无法胜任通用多部件物体的组装。
此外,先前的研究主要聚焦于使用单机械臂完成两部件、自上而下的插入任务。而多部件组装需要各种不同的插入与抓取姿态,常常需要双臂协同操作,还要频繁地切换固定手与操作手以平衡插入过程中的相互作用力。
为此,麻省理工大学联合苏黎世联邦理工学院等提出一套具有端到端规划与控制能力的双臂机器人系统Fabrica,用于实现通用多部件物体的自主组装,首次实现了无需领域知识或人类演示、即可完成通用多部件的完整装配。与Fabrica相关的论文成果荣获CoRL 2025 Oral, Best Paper Award。
针对长程规划,开发了一套分层双臂规划器。用于规划与优化组装-固定序列、抓取与机器人运动。对于需要密集接触的组装步骤,提出了一个轻量的强化学习框架。该框架能够训练出适用于不同物体形状、组装方向与抓取姿态的通用策略,实现零样本sim-to-real迁移,在真实机器人上达到81%的步骤成功率。

论文标题:《Fabrica: Dual-Arm Assembly of General Multi-Part Objects via Integrated Planning and Learning》
论文链接:https://arxiv.org/abs/2506.05168
项目主页:
https://fabrica.csail.mit.edu/
收录情况:CoRL 2025 Oral, Best Paper Award
1
方法
1.1 多步骤分层双臂规划
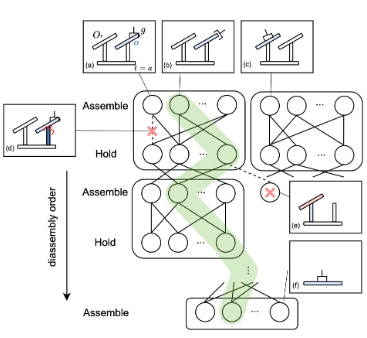
给定一个包含 n 个部件的装配任务,需要计算一个规划,在满足所有物理约束的前提下,将所有部件从初始位姿操作至目标位姿。本论文专注于顺序、协作式的操作方式,即交替使用机器人装配一个部件,并使用另一台机器人持握另一个部件以稳定子装配体。随后,为密集接触式装配步骤训练控制策略。最终,Fabrica系统执行过程会在开环的规划运动与闭环的反应式策略之间交替进行。如图2所示,展示了系统概览。
部件优先级规划
为了评估约束Cprec,研究人员提出一种算法来确定所有部件的完整优先级关系。
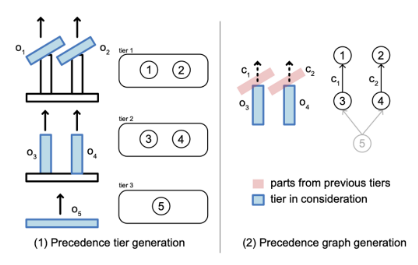
首先,定义优先级层级为一组可以彼此独立拆卸的部件。层级按顺序排列,较早层级的部件必须在较晚层级的部件之前被拆卸。
为了迭代构建所有层级,使用基于物理的运动规划器来找出所有可在不影响剩余部件的情况下被拆卸的部件,并将其归入当前层级。接着移除这些部件,并在剩余的装配体上重复此过程,直到每个部件都被分配到一个层级。
接下来,构建一个优先级图Gprec,它编码了任何无碰撞装配序列必须遵循的最小顺序约束集。对于每个部件,定义其优先级集合:
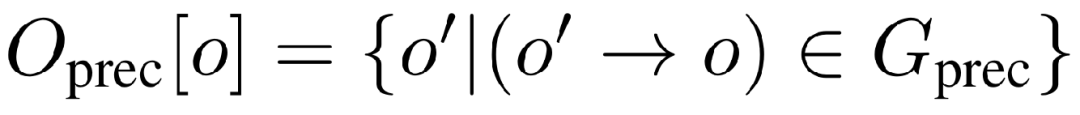
双臂抓取过滤
目标是为每个"装配-持握"部件对识别有效抓取对,这些抓取对能在不与"装配-持握"部件对的优先级部件发生碰撞的情况下,支持插入和持握操作。
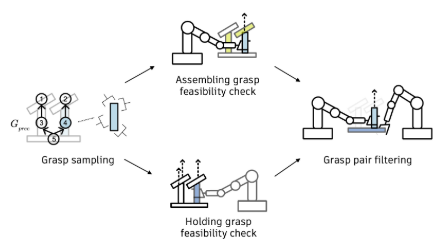
由于在6自由度空间中搜索不可行,假设可行的抓取姿态存在于一个稠密的、有限的抓取集中。因为每个抓取都需要检查其与当前子装配体的碰撞,在线进行此操作会导致针对许多部件组合进行重复且昂贵的检查。为了加速,通过采样抓取候选姿态,并行执行两个机械臂的逆运动学和碰撞检查,来离线预计算有效的抓取。
双臂序列-抓取优化
在所有有效抓取计算完成后,求解公式 2 中的最优序列 ɸ 和抓取 σ。
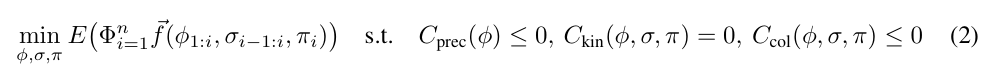
研究人员将其建模为一个状态空间搜索问题,并构建一个有向状态树。从根节点(完整装配状态)开始,通过在装配和持握操作之间交替进行,递归地扩展状态树,并剪枝违反约束的状态。有效的状态转移还必须遵守连续步骤之间预先计算好的抓取可行性。所有碰撞和运动可行性检查都复用先前过滤阶段的结果。
每次状态转移由一个抓取稳定性向量评分,该向量捕获了如持握部件的支撑性、抓取切换频率、扭矩稳定性和接触面积等目标,这些目标轻量且能够有效控制下游。应用动态规划算法在树中传播最佳累积分数,从而确定最优解。
抓取感知的拾取夹具生成
为了实现精确拾取,开发了一种软硬件协同设计方法,基于上文中的规划抓取姿态,自动生成一个用于稳定并定向每个部件以进行自上而下拾取的夹具。这消除了在拾取和装配之间进行重定向或重新抓取的需要,使得系统能够专注于核心的装配挑战。
转移与传送运动规划
最后,使用RRT-Connect规划所有剩余的转移和传送运动。由于所有运动的起始状态和目标状态均已由前述阶段提供,这些运动规划可以并行进行。
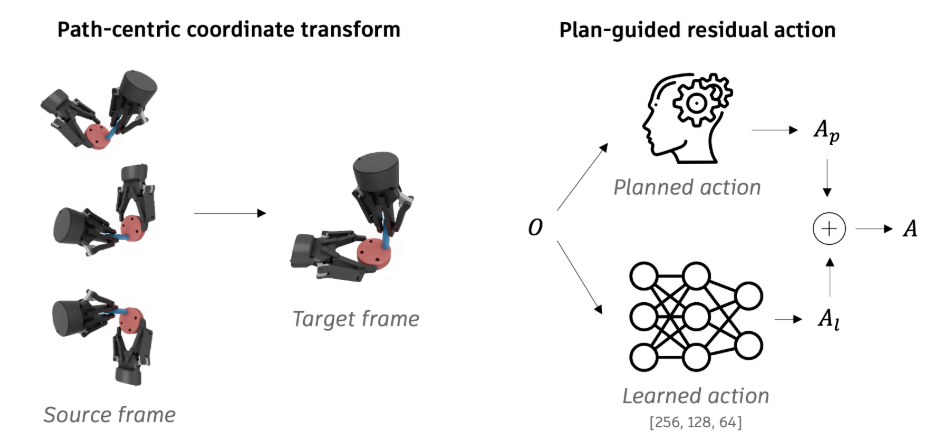
1.2 学习通用单步装配策略
计算出完整的装配计划后,下一步是在真实环境中可靠地执行。采用一种混合控制器,该控制器交替执行:跟踪预先规划的无接触移动和抓取移动;以及对于接触密集的装配步骤,使用基于强化学习的反应式控制器。该控制器需要泛化到不同的物体几何形状、抓取姿态和装配方向。为此,研究人员设计了一个轻量级但高效的强化学习框架,用于训练通用的装配策略。
2
实验
2.1 基准测试套件与实验设置
研究人员开发了一个涵盖家具、玩具和工业设备的多样化基准测试套件,包括不同几何形状、插入方向(top-down 插入或侧插)、多个零件,适用于配备夹爪的双臂机器人。为了在仿真中进行规划,在仿真中发多个不同的机器人上进行了演示,包括Franka Emika Panda、UFactory xArm7和配备不同夹爪的UR5e。在真实世界中使用Panda机器人进行策略训练和任务执行。

2.2 在仿真中规划多步装配
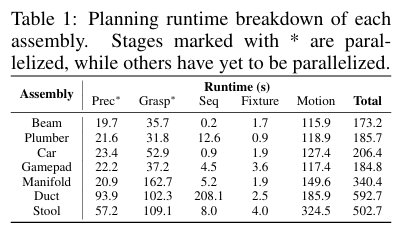
效率:如表1展示了不同任务各阶段规划时间。在高效的并行化计算下,Fabrica求解最优计划的总体速度在分钟量级。
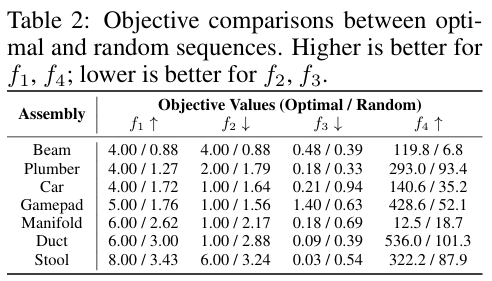
最优性:表2展示了在f1至f4的优先级标准下的优化序列的目标函数得分。
通用性:不同机械臂(Panda、xArm7、UR5e)与夹爪组合的规划效果表明。本论文提出的规划框架对不同的机械臂具有很好的兼容性。
2.3 仿真环境中的单步装配学习
基于IsaacGym仿真平台并采用RL Games中的PPO算法进行策略训练与仿真验证。在1024次随机试验中,采用不同方法完成基准仿真测试的平均步骤成功率:
1、开环跟踪:严格遵循预设路径且无反馈校正的基准方法;
2、专用RL策略:针对特定零件组单独训练的策略;
3、集成策略:基于单个装配体全部零件训练的整合策略;
4、通用策略:基于测试套件所有装配体零件训练的通用策略。

实验结果如表3所示,开环跟踪法在所有装配体中成功率最低,其在应对不确定性和个体差异方面存在局限性。集成策略与专用RL策略表现相当,在单装配体内构建共享策略具备良好的泛化能力。通用策略虽略逊于专用RL策略,仍展现出稳定性。
2.4 真实机械臂上的多步装配执行
将Fabrica部署在真实双臂机器人上的各装配步骤的独立成功率如表4所示。
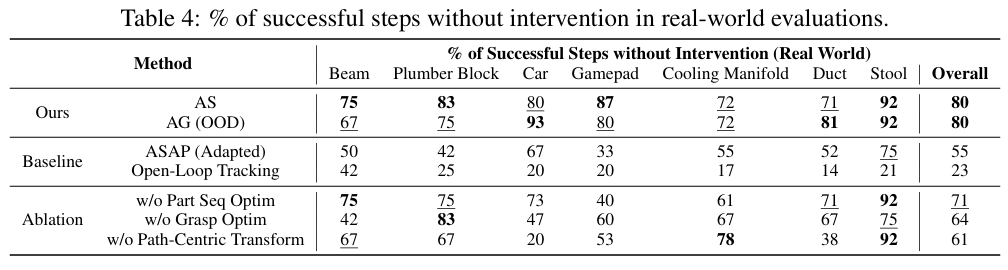
表5则展示了允许0/1/2次人工干预时的多步累计成功率(系统级统计)。
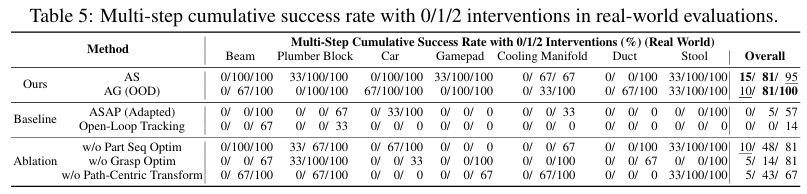
尽管仿真中预设了3毫米误差,但真机环境中存在多种误差远超仿真设定,这仍是未来工作需要突破的难点。由于存在固有的高难度步骤,所有方法在零干预场景下的多步成功率均接近零值。但在引入适度干预后,Fabrica优势显著:单次干预成功率可达81%,两次干预后成功率更提升至95%。
3
总结
本论文提出一个融合了全局分层规划与局部通用策略学习的创新双臂机器人系统Fabrica,用于实现自主多部件装配。为支持严谨且可复现的评估,提出了一套涵盖多样化多部件装配场景的综合性基准测试套件。Fabrica能真实世界中的各类装配任务中,既实现了鲁棒性又具备很强的泛化能力。单次干预的任务成功率可达81%,两次干预后成功率更是达到95%。
END
智猩猩矩阵号各专所长,点击名片关注