

构建 “机器人形态宇宙”!
当前主流机器人运动(locomotion)方法,深陷“白板假设”陷阱——
假定智能体能在任务单一、环境纯净的“空白状态”下,通过强化学习从头解决特定问题。
这导致了大量高度专业化却极其脆弱的控制器,本质上是在狭窄的物理动态分布上“过拟合”。
而自然界的生物智能给出了截然相反的答案:
智能并非来自单一任务的极致优化,而是源于在复杂、多变甚至危险的环境中求生的普遍需求。
在此背景下,CoRL 2025 上的这项工作 —— 它不仅是大会最佳论文候选(Best Paper Award Finalist),更可能重塑未来机器人运动控制的发展方向。
它首次在人工系统中成功地复制了这一自然法则——
如何通过试探性交互来推断自身结构,如何基于推断结果规划可行的运动序列,以及如何在前序策略失败后利用记忆进行战略性调整。

方法原理
关键问题:现有机器人运动控制策略缺乏泛化性与适应性
当前基于强化学习的机器人运动控制方法通常针对特定形态进行专门化训练,导致其泛化能力严重受限。
这类策略无法应对本体结构的重大改变(如电机故障、腿部损伤或建模误差)。

因此,在实际部署中常需为每个机器人进行繁琐的系统辨识,且控制器在分布外场景下容易发生灾难性失效。
核心动机:
在训练阶段引入极广的任务分布与极强的领域随机化,将迫使策略学习通用运动规律与在线适应机制。
将策略的上下文长度扩展数个数量级,使其能够从长时程交互数据中提取足够信息,从而在测试时实现对未知形态与动态的持续适应。

这一研究旨在构建一种能够控制任意机器人形态、并适应重大结构损伤的通用运动控制模型,以显著提升机器人的 sim2real 迁移效率与在异常条件下的鲁棒性。
预训练以学习情境适应
目标:
使策略能跨不同机器人形态(双足/四足、腿式/轮式)进行统一控制,而无需依赖精确的系统辨识。

关键设计:
① 程序化生成任务空间:
通过算法大规模生成形态各异的机器人;
并随机化其运动学(关节)和动力学(质量、质心等)参数;
构建一个极其多样化的MDP分布(ρM)进行训练。

② 统一接口设计:
观测与动作空间:统一的关节空间,其维度是所有可能机器人的关节“超集”。策略在该统一空间输出动作,再映射到具体机器人的有效关节上。
奖励函数:采用混合奖励设计,以指令跟踪为主,辅以降低扭矩、平滑动作和防止硬件损伤等惩罚项,引导策略学习既有效又安全的运动模式。
支持长时记忆的策略架构
核心创新:
摒弃传统RNN或短时记忆MLP,采用分段的Transformer架构;
在处理当前状态时能够关注到远超出传统方法数百毫秒的长期历史信息;

从多次试验的失败与成功经验中学习并持续改进。
实现“在线情境学习”的关键
短暂的数百毫秒历史仅能用于微调平衡,无法应对机体结构的巨变。
长上下文记忆为策略很关键
例如,一条腿损坏后,机器人需要多次尝试失败,才能理解新的重心位置和可行的步态。

修改标准RL的回合设定
核心目标:
而在这里,策略会因为“在第一次试验失败后,能利用记忆在第二次试验中成功”而受到奖励。这本质上是在引导策略学习“如何学习”,即元学习。
规模化训练与部署:
训练范式:
采用两阶段PPO训练。
第一阶段(短试验、短适应时间)专注于快速学习适应能力本身;
第二阶段(长试验、长适应时间)则专注于强化稳定性与持久性,为 sim2real 转移做准备。

实验分析总结
该部分通过三项实验,验证证LocoFormer的核心能力:
在未知机器人上的性能评估
核心结论:
在10种未见过的真实机器人模型上,LocoFormer的零样本和少样本性能均逼近为每个机器人单独训练的专家策略,显著优于所有基线。

关键例证:
在无脚踝的TRON1双足机器人上,仅5秒的适应时间就带来了10%的性能提升,证明了其在线优化的有效性。
它表明,“理解身体”不是一个前提,而是一个过程。
模型开始时并没有关于机器人形态的先验知识(初始表征相似),但它通过感知-行动闭环,主动地进行了一种无监督的“身体辨识”。
最终形成的清晰聚类证明,它在内部流形中为不同的身体结构创建了分离且稳定的“概念”。
适应能力量化
核心结论:
在加倍的领域随机化和复杂地形下,LocoFormer的生存时间随着适应预算的增加而持续增长。

这直接证明了长上下文学习的优势——
模型能够利用更长的交互时间来理解和适应极端困难、分布外的动态环境。
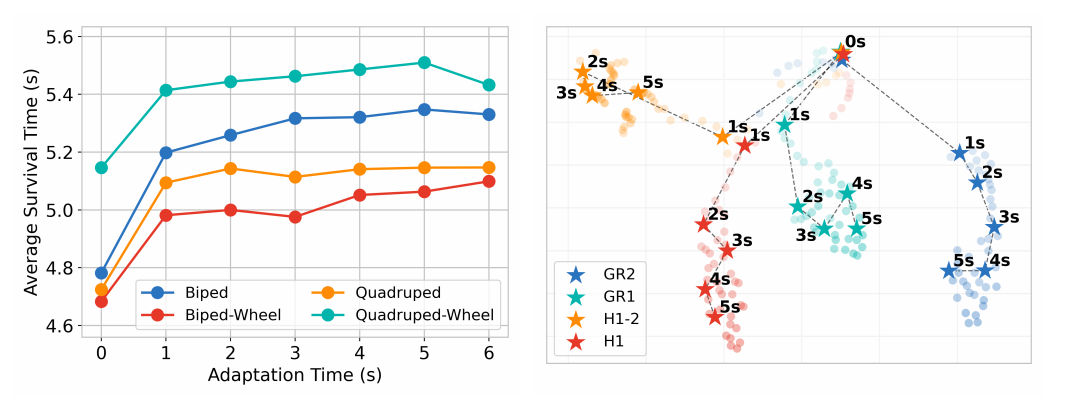
在长达数秒的时间尺度上,模型仍在从历史中提取有效信息并改进策略。
这彻底颠覆了传统myopic策略(仅在几百毫秒内有效)的范式,将机器人控制的决策范围扩展到了一个全新的量级。
内部表征动态分析
核心发现:
模型内部表征会随时间推移而演化。对于不同的机器人,其初始表征相似,但在几秒内会逐渐分化并形成各自独立的聚类。
这为模型的适应能力提供了神经科学式的解释——
LocoFormer并非静态地处理信息,而是在交互过程中动态地、在线地构建起针对特定身体的内部模型。

当将这个预训练模型部署到真实机器人上时,它在前几秒内的“蹒跚”不再是失败,而是宝贵的、构建内部模型的探索数据。随后,它的行为会迅速稳定。
核心演示场景
腿部锁定(场景A, E):在四足机器人行走时,程序化锁定其一个或多个膝关节。LocoFormer能迅速适应,调整步态将重心转移到剩余腿上,甚至在2-3秒内恢复三足行走。
跨试验学习(场景B):在极不稳定的双足模式下,首次试验失败后,模型能利用缓存中的失败记忆,在后续试验中持续改进,最终实现稳定行走甚至抗干扰。
轮式锁定与负载变化(场景C):当轮式机器人的轮子被锁定后,模型能检测到动态变化,自动从滚动切换为步行步态;当轮子解锁后,又能切换回更节能的滚动模式。附加质量时也能调整步态保持平衡。
踩高跷行走(场景D):为机器人装上远超出训练分布的长腿(高跷),改变了运动学和动力学。模型能快速调整步态时序和脚部位置,实现稳定行走。
腿部截断(场景F):直接切掉机器人的小腿,使其在未训练过的“跪姿”形态下,经过7-8秒的探索,自主发现需要大幅摆动大腿关节才能有效移动,并成功实现行走。
这意味着,我们未来可能不再需要为每个实物机器人进行繁琐的模拟调参,而是直接使用一个通用的“大脑”,让它自己“学会”如何控制新身体。

总结
涌现的“故障应对”能力标志着向通用智能的迈进
这些演示证实模型处理了许多完全不在训练分布内的极端情况(如三足机器人、截肢)。
这表明它学会的不是具体的步态,而是一个通用的“运动问题解决”原则:
通过与环境的物理交互来发现自身身体的约束,并寻找能满足目标(前进、不摔倒)的动作序列。这是一种涌现的故障恢复能力,是向真正鲁棒、通用的具身智能迈出的关键一步。
“身体模型”是在线构建并持续更新的
LocoFormer在内部维护着一个动态的、可更新的身体模型。证明模型的内部表征不仅包含状态,更包含了对“我当前是一个什么样的物理系统”的在线估计。
统一模型实现多模态控制
在轮腿式机器人上,同一个LocoFormer模型能够根据轮子的可用性,在滚动和步行这两种截然不同的运动模式间无缝切换。这证明了其不再是传统的“步态发生器”,而是一个更高级的运动决策器,能够为当前的身体状态和物理约束选择最有效的移动策略。
对机器人可靠性与耐久性的范式变革
传统机器人一旦发生硬件损伤(如电机损坏、结构断裂),通常意味着任务的立即失败。
LocoFormer展示了一种新的可能性:机器人能够在受损后“带伤工作”。
这种“断腿求生”的能力对于在搜救、太空探索等不可预测且维修困难的环境中长期运行的自主机器人来说,具有革命性的意义。它将系统的鲁棒性从硬件设计层面,部分地转移到了智能体的软件能力层面。
结语
所以,未来的机器人会是什么样子?
LocoFormer给了我们一个充满想象力的答案:
它们出厂时或许不再需要预装复杂的步态库,只需要搭载一个如LocoFormer般的通用“运动大脑”。
从“编码特定技能”到“激发适应智能”,LocoFormer不仅是一个技术模型,更是一个范式转变的信使。未来的机器人,终将学会“用自己的身体,走自己的路”。
编辑|无意
审编|具身君
Ref
论文题目:LocoFormer: Generalist Locomotion via Long-context Adaptation
论文地址:https://arxiv.org/pdf/2509.23745
项目地址:https://generalist-locomotion.github.io/
>>>现在成为星友,特享99元/年<<<


【具身宝典】||||
【技术深度】|||||||
【先锋观点】|||
【非开源代码复现】||
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

【深蓝具身智能】的内容均由作者团队倾注个人心血制作而成,希望各位遵守原创规则珍惜作者们的劳动成果。
投稿|商务合作|转载:SL13126828869(微信)

点击❤收藏并推荐本文










