(1) R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization
论文简介:
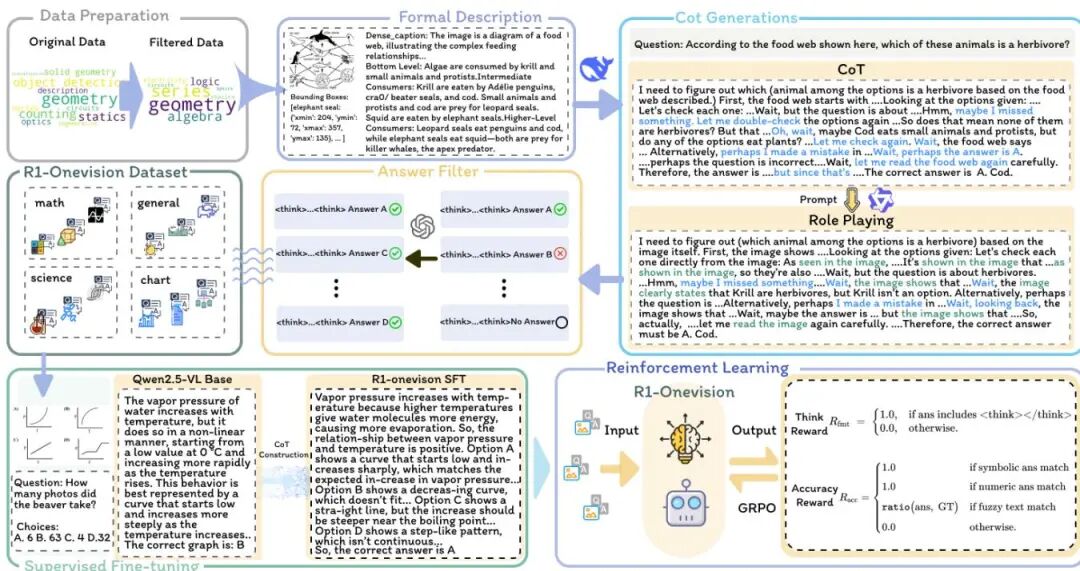
由浙江大学、腾讯微信视觉、中国人民大学等机构提出了R1-Onevision,该工作通过跨模态形式化方法构建了多模态推理模型与数据集,显著提升了视觉与文本联合推理能力。研究团队创新性地设计了跨模态推理流水线,将图像转化为结构化文本表示,使语言模型能够精确解析视觉内容并进行逻辑推理。基于此流水线构建的R1-Onevision数据集包含15.5万条多领域(科学、数学、图表等)推理标注数据,覆盖自然场景、OCR文本、数学公式等复杂场景。模型训练采用两阶段策略:先通过监督微调建立标准化推理模式,再利用基于规则的强化学习优化泛化能力,特别设计了格式奖励与准确性奖励机制。为全面评估模型,团队开发了R1-Onevision-Bench基准,该基准参照人类教育体系设计,涵盖初高中至大学阶段的数学、物理、化学等5大学科38个子任务,包含942道独立题目。实验显示,R1-Onevision在MathVision、MathVerse等基准上超越GPT-4o和Qwen2.5-VL等模型,在MathVerse视觉子任务中准确率达40.0%,较基线提升5.5%。该模型在大学阶段科学推理任务中表现尤为突出,化学与生物学科准确率分别达49.5%和53.0%,接近顶尖闭源模型水平。研究通过形式化视觉描述、角色扮演数据增强及分阶段训练策略,有效解决了多模态推理中视觉信息失真与推理深度不足的问题,为构建通用视觉推理系统提供了新范式。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.1160
(2) Text-guided Visual Prompt DINO for Generic Segmentation

论文简介:
由清华大学深圳国际研究生院和腾讯微信AI团队提出了Text-guided Visual Prompt DINO(Prompt-DINO),该工作提出了一种新型多模态分割框架,通过三大创新突破现有技术瓶颈:1)首创早期融合机制,在初始编码阶段实现文本、视觉和骨干特征的深度统一,通过门控交叉注意力机制解决跨模态语义歧义问题;2)设计顺序对齐的查询选择策略,在DETR解码器中显式优化文本与视觉查询的结构对齐,提升语义空间一致性;3)构建生成式数据引擎RAP,采用双路径交叉验证流水线合成5亿高质量训练样本,将标签噪声降低80.5%。该框架在COCO、LVIS等基准测试中实现SOTA性能,同时通过生成式数据引擎突破固定词汇表限制,在ADE20K等跨域测试中展现出卓越泛化能力,为开放世界检测与分割提供了可扩展的多模态学习范式。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.74
(3) Learning Efficient and Generalizable Human Representation with Human Gaussian Model

论文简介:
由清华大学、微信视觉、腾讯等机构提出了Human Gaussian Graph,该工作通过构建双重图结构连接跨帧高斯分布与人体SMPL网格,实现高效通用的可动画人体高斯表示。论文针对传统方法独立预测每帧高斯分布导致时序信息缺失的问题,创新性地设计了双层节点架构:第一层节点为多帧高斯分布,第二层节点为SMPL网格顶点,并通过空间对齐建立跨帧高斯分布与人体结构的关联。在此基础上,提出intra-node操作聚合多帧高斯特征,inter-node操作实现网格邻域节点间的信息传递,使模型能够整合时序信息与人体先验。实验显示,该方法在单目和多视角输入下均取得最佳表现,单帧推理时间仅9.7秒,多视角输入下PSNR达26.536,较现有方法提升显著。尤其在新颖姿态动画任务中,通过SMPL参数驱动的高斯分布实现了高质量姿态迁移,为虚拟人重建、实时渲染等应用提供了新范式。该方法突破了传统优化方法的效率瓶颈,同时解决了通用化方法缺乏时序建模的缺陷,为可动画人体表示提供了高效解决方案。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.1253
(4) Morph: A Motion-free Physics Optimization Framework for Human Motion Generation

论文简介:
由腾讯微信、中国科学院计算技术研究所、鹏城实验室、中国科学院大学、上海交通大学等机构提出了Morph,该工作针对当前人类动作生成模型忽视物理约束导致动作不真实的问题,提出了一种无需真实数据的物理优化框架。Morph通过运动生成器(MG)与运动物理细化模块(MPR)的协同训练,利用合成数据构建物理约束,显著提升生成动作的物理合理性。
Morph框架包含两个核心模块:运动生成器可适配扩散模型、自回归模型等主流生成模型;运动物理细化模块通过物理模拟器和先验奖励机制,将生成器输出的含噪动作投影到符合物理规律的空间。其创新点在于:1)构建无需真实数据的物理优化流程,通过生成器合成大规模数据训练细化模块;2)设计先验奖励模块加速强化学习训练,提升模拟动作的自然度;3)采用多轮迭代优化机制,细化后的数据反哺生成器微调,形成双向增强循环。
实验验证覆盖文本驱动动作生成(HumanML3D数据集)和音乐驱动舞蹈生成(AIST++数据集)两大任务,适配MDM、MotionDiffuse、T2M-GPT等六种主流生成模型。结果表明,Morph在保持生成质量的同时,将动作穿透、漂浮、滑动等物理错误降低90%以上。例如在HumanML3D数据集上,与基线模型相比,穿透错误从23.152降至0,漂浮错误从10.66降至2.14,且文本检索精度RTOP-3提升1.4%。该框架为数字人、机器人控制等需要物理真实感的应用场景提供了通用解决方案。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.1556
(5) MCID: Multi-aspect Copyright Infringement Detection for Generated Images

论文简介:
由北京大学与腾讯微信AI等机构提出了MCID(Multi-aspect Copyright Infringement Detection),该工作针对生成图像版权保护难题,首次提出多维度侵权检测任务,通过融合特征分析与视觉语言模型(VLM)构建混合检测框架HIDM,并建立大规模版权数据集LSCD实现法律合规性验证。研究指出传统方法依赖全局相似度易漏检局部侵权(如风格/结构复制),而MCID任务将侵权细分为内容、风格、结构及知识产权(IP)四类,覆盖生成图像对原创作品的多角度潜在侵害。HIDM模型通过LoRA微调的多特征编码器提取属性级相似度,结合VLM语义推理能力,在侵权判断中实现可解释性与高精度双重突破。实验显示HIDM在MCID测试集平均检测准确率达72.46%,显著优于现有方法,尤其在结构侵权检测上提升45.77%。LSCD数据集包含1,927位艺术家71万张确权图像,经法律专家标注构建的236对侵权样本测试集,为技术落地提供合规基准。该工作为AIGC版权治理提供新范式,推动生成模型产业健康发展。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.486
(6) Bridging the Gap Between Ideal and Real-world Evaluation: Benchmarking AI-Generated Image Detection in Challenging Scenarios

论文简介:
由北京师范大学、中国科学院大学、复旦大学、中央财经大学和清华大学等机构提出了Real-World Robustness Dataset(RRDataset),该工作针对现有AI生成图像检测方法在真实场景中评估不足的问题,构建了首个覆盖战争冲突、灾害事故、政治事件等六大高风险场景及日常生活的基准数据集,并系统性模拟了互联网传输和四种再数字化过程,揭示了当前检测模型在真实世界条件下的性能衰减问题,同时通过192人参与的大规模人类实验发现了人类在少量学习后显著提升的检测适应能力,为改进检测算法提供了新思路。
该数据集包含10万张图像,覆盖六大专业场景(每个场景1万张AI生成与1万张真实图像)和4000张日常生活图像,通过Telegram、微信等7个平台进行2-6轮传输,并采用扫描、拍照等四种方式模拟再数字化。在17种检测方法和10种视觉语言模型的基准测试中,最优模型在原始数据上仅达89.59%准确率,而经传输和再数字化后性能显著下降,其中基于扩散模型的方法在传输后表现较稳定,但再数字化时准确率骤降88-90%。人类实验显示,普通场景检测准确率为69.17%,专业场景仅59.52%,但经过2次少量学习后准确率提升13.79%,证明人类具备快速适应能力。研究还发现,当图像质量受损时,人类更倾向判定为AI生成(特殊场景组达89.31%),反映出对图像真实性的信任危机。基于人类决策特征设计的视觉语言模型在位学习策略,使GPT-4o在再数字化场景下的检测准确率提升5.5%,验证了人类认知机制对算法改进的启发价值。该工作揭示了现有检测方法在真实场景中的局限性,并为构建更具鲁棒性的鉴别模型提供了数据基准与设计思路。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.1992
(7) A Visual Leap in CLIP Compositionality Reasoning through Generation of Counterfactual Sets
论文简介:
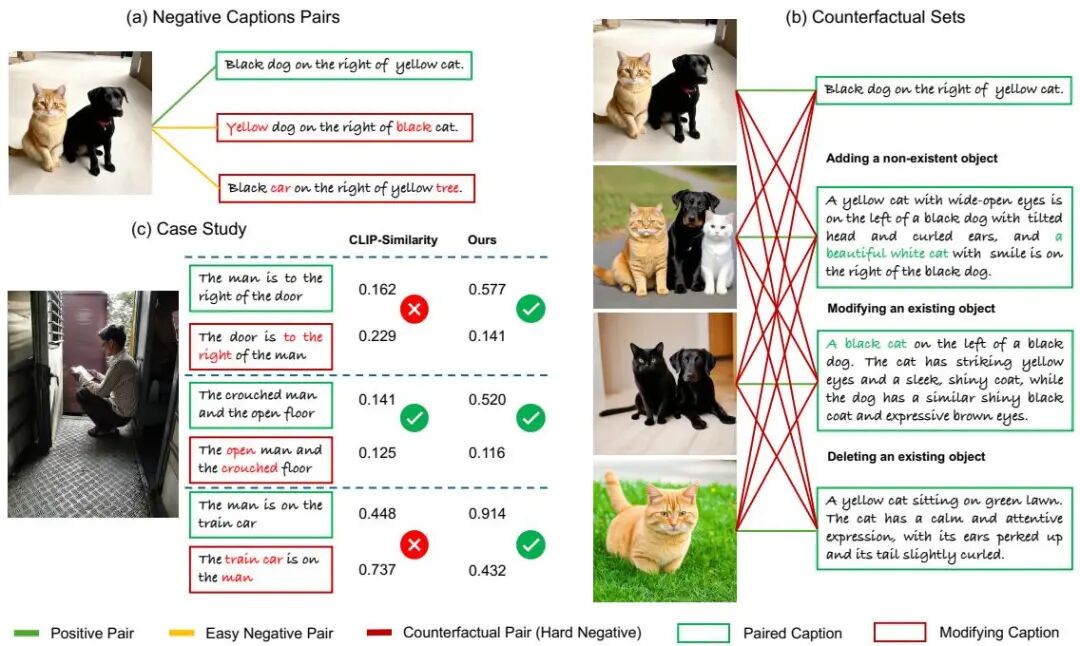
由腾讯微信AI和北京大学等机构提出了基于生成反事实集合的CLIP组合推理增强方法,该工作通过创新的数据合成策略显著提升视觉语言模型的组合推理能力。研究团队发现现有视觉语言模型(VLMs)因缺乏高质量图文对齐数据,在属性、位置和关系理解上存在显著缺陷。为此提出块状扩散生成方法,将图像分解为语义"拼图碎片",利用大语言模型解析文本描述中的实体及空间关系,独立生成对应图像块后按规则重组,实现对组合属性的精确控制。该方法无需人工标注即可自动构建包含实体增删改的反事实图像-文本对,同时设计了专门针对反事实集合的对比损失函数,通过区分集合内/集合间样本对来提升训练效率。实验显示,使用该方法生成的数据微调CLIP模型后,在ARO、VL-Checklist等基准测试中均超越现有方法,尤其在空间关系理解任务上表现突出。值得注意的是,该方法在仅使用10k反事实样本时即超越使用300k样本的对比方法,在sDCI数据集上实现47.9%的SCM@1准确率和90.2%的Neg@1准确率,证明了数据质量和训练策略的有效性。研究还验证了方法的通用性,成功将BLIP-2和MiniGPT-4的组合推理能力分别提升5.1%和6.4%,为视觉语言模型的高效训练提供了新范式。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.1546
(8) WalkVLM: Aid Visually Impaired People Walking by Vision Language Model

论文简介:
由腾讯微信AI团队等机构提出了WalkVLM,该工作针对视障人士行走辅助任务,构建了包含12,000个视频-标注对的Walking Awareness Dataset(WAD)基准数据集,并提出基于视觉语言模型的行走指导系统。针对现有方法在实时视频处理中存在的响应冗余和效率不足问题,WalkVLM采用链式推理(Chain of Thought)进行分层规划,通过静态属性提取、场景理解到决策生成的三级架构,实现关键信息的精准提取与简洁提醒生成。同时创新性地引入时间感知自适应预测(TAP)模块,通过历史状态分析动态触发模型响应,有效降低时间冗余度达40%以上。实验表明,WalkVLM在ROUGE、TF-IDF等指标上优于GPT-4o等主流模型,尤其在提醒任务的简洁性和时效性方面表现突出。该研究不仅建立了首个标准化的盲人行走辅助基准,更通过模型架构创新推动了视觉语言模型在实时场景下的实用化进程,为视障人士的智能辅助技术提供了新的技术范式。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.934
(9) HQ-CLIP: Leveraging Large Vision-Language Models to Create High-Quality Image-Text Datasets and CLIP Models

论文简介:
由中科大与腾讯微信视觉团队提出了HQ-CLIP,该工作通过构建高效的大型视觉语言模型(LVLM)驱动的数据精炼管道,生成包含1.5亿高质量图文对的VLM-150M数据集,并基于此提出新型CLIP训练框架。研究团队首先采用GPT-4o生成1万高质量图文样本,进而对Qwen2-VL-7B模型进行监督微调(SFT),使其在保持9倍计算效率优势的同时达到与Qwen2-VL-72B相当的描述生成能力。该管道为每幅图像生成四种互补文本:长正描述、长负描述、短正标签和短负标签,形成多粒度语义监督信号。在训练阶段,HQ-CLIP创新性地引入硬负样本识别(HNI)机制,通过动态门控策略将生成的负描述融入对比学习,并设计短标签分类(STC)损失增强类别语义识别。实验显示,在同等1.5亿数据规模下,HQ-CLIP在DataComp基准的零样本分类和跨模态检索任务中全面超越现有方法,其中COCO检索准确率较DFN-2B(使用10倍数据)提升0.6%,ImageNet分类准确率达70.6%。当作为LLaVA-1.5视觉编码器时,在MMBench等多模态评测中超越同规模ViT-B模型。该研究证明了通过LVLM生成的多粒度文本监督信号,可在显著降低数据规模需求的同时提升CLIP模型性能,为多模态学习提供了高效的数据增强范式。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.886
(10) Unleashing High-Quality Image Generation in Diffusion Sampling Using Second-Order Levenberg-Marquardt-Langevin

论文简介:
由浙江大学、腾讯微信视觉、上海交通大学和腾讯光子工作室等机构提出了Levenberg-Marquardt-Langevin(LML)方法,该工作通过低秩近似和阻尼机制近似扩散模型中的Hessian几何信息,显著提升预训练扩散模型的图像生成质量。现有扩散模型采样方法多依赖一阶朗之万动力学,而利用二阶Hessian几何信息虽能提升采样精度,但直接计算存在二次复杂度问题。LML方法受优化领域Levenberg-Marquardt算法启发,创新性地通过低秩近似避免显式计算完整Hessian矩阵,同时引入阻尼机制稳定近似矩阵的逆运算。理论分析表明该方法在保持目标分布不变性的前提下,具有指数收敛速率。实验验证覆盖CIFAR-10、CelebA-HQ、Stable Diffusion系列等多模型,在保持计算效率的同时,FID指标在10 NFE条件下较DDIM降低41.5%,在文本生成图像任务中Colorful、Shape等指标提升显著,且与ControlNet等插件兼容。代码已开源于https://github.com/zituitui/LMLdiffusion-sampler。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.781
(11) Unified Adversarial Augmentation for Improving Palmprint Recognition

论文简介:
由合肥工业大学、腾讯优图实验室和腾讯微信支付实验室等机构提出了Unified Adversarial Augmentation(UAA)框架,该工作针对掌纹识别中几何失真和纹理退化导致的性能下降问题,通过结合对抗训练范式与动态采样策略,生成兼具几何变化和纹理多样性的增强样本,在保持身份一致性的同时显著提升了模型在挑战性数据集上的识别精度。
当前掌纹识别模型在约束数据集上表现良好,但在处理几何失真(如位置偏移、尺度缩放)和纹理退化(如过曝、模糊)样本时存在明显局限。传统数据增强方法因缺乏针对性且易破坏身份特征,难以生成有效增强样本。该研究提出统一对抗性增强框架(UAA),通过对抗训练优化增强策略,生成兼具几何变换和纹理变化的挑战性样本。框架包含三个核心模块:1)可微分空间变换模块,通过仿射变换引入几何变化;2)身份保持生成网络,采用风格迁移技术合成纹理变化同时保留身份特征;3)动量驱动的动态采样策略,根据历史优化轨迹自适应调整参数空间。在对抗增强阶段,通过最大化分类损失优化控制向量,使生成样本更具挑战性;在识别阶段,利用优化后的向量生成样本训练识别模型。实验在MPD、XJTU-UP等挑战性数据集上实现显著性能提升,例如在MPD数据集上TAR@FAR=1e-5指标从基线的46.77%提升至80.75%,同时在约束数据集也保持高精度。消融实验证明空间变换、纹理生成和动态采样各组件均对性能提升有贡献。该方法首次将对抗训练范式引入掌纹识别领域,为生物特征识别提供了新的数据增强范式。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.686
(12) From Enhancement to Understanding: Build a Generalized Bridge for Low-light Vision via Semantically Consistent Unsupervised Fine-tuning

论文简介:
由华东师范大学、腾讯优图实验室和腾讯微信支付实验室等机构提出了GEFU(Generalized Enhancement For Understanding),该工作通过构建低光增强与理解的通用桥梁,解决传统方法在泛化性和可扩展性上的局限。研究团队创新性地将预训练生成扩散模型(如Stable Diffusion)与语义一致的无监督微调框架结合,提出照明感知图像提示(Illumination-Aware Image Prompt)引导图像生成,并设计循环注意力适配器(Cycle-Attention Adapter)最大化语义潜力。针对无监督训练中的语义退化问题,引入字幕一致性(Caption Consistency)和反射一致性(Reflectance Consistency)分别学习高层语义和空间语义。实验表明,该方法在传统图像质量指标(PSNR/SSIM/LPIPS)及下游任务(分类、检测、分割)中均超越现有SOTA方法,例如在CODaN分类任务中Top-1准确率达60.92%,Darkface检测mAP达16.9%,BDD100k夜间分割mIoU达20.1%,且推理速度优于多数扩散模型方法。该工作首次系统性构建了"增强-理解"统一评估范式(GEFU),为低光视觉任务提供了兼顾图像质量和语义保真度的解决方案。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.102
论文解读由 Intern-S1 生成