
本研究由快手科技 Klear 语言大模型团队完成,核心作者苏振鹏,潘雷宇,吕民轩,胡文凭,张富峥,周国睿等。快手 Klear 语言大模型团队聚焦在基础语言大模型研发、Agent RL 等前沿技术创新等方向,积累务实的探索 AGI 的能力边界,并不断推进 AI 领域新技术和新产品的发展。此前,该团队已开源了 Klear-46B-A2.5B 和 Klear-Reasoner-8B 等模型,其中 Klear-Reasoner-8B 在数学和代码的基准测试上达到了同参数级别模型的 SOTA 效果。
近年来,随着 OpenAI O1、Deepseek R1、KIMI K2 等大模型不断展示出复杂推理与思维链能力,强化学习已成为推动语言模型智能跃升的关键技术环节。相比传统的监督微调,RL 通过奖励信号直接优化模型行为,使模型能够在训练中自我探索、自我修正。
然而,这一阶段的训练并非稳态过程。业界在大规模 RLVR 实践中普遍发现,模型熵的失衡,即探索与利用的不协调,是导致模型训练不稳定、性能难以提升的核心原因。针对这一长期瓶颈,快手 Klear 团队提出了一种新的强化学习算法 CE-GPPO(Coordinating Entropy via Gradient-Preserving Policy Optimization),该方法以「熵」为核心视角,重新审视 RL 中梯度裁剪机制的本质影响,并对应地提出了梯度保留策略,在保证训练稳定的前提下,纳入裁剪区间外的梯度使模型能够在训练过程中达到探索与收敛的平衡。

论文标题:CE-GPPO: Coordinating Entropy via Gradient-Preserving Clipping Policy Optimization in Reinforcement Learning
论文地址:https://www.arxiv.org/pdf/2509.20712
项目地址:https://github.com/Kwai-Klear/CE-GPPO
研究动机
在使用强化学习方法优化大模型以处理复杂推理任务的过程中,策略熵的平衡是核心挑战,原因在于它衡量了动作选择的不确定性,能够代表模型探索与利用的权衡。然而,现有的方法通常面临熵不稳定的问题,具体来说包含两方面,一方面是熵坍缩,这会造成模型的输出趋于单一,丧失探索能力,另一方面是熵爆炸,这会造成模型过度探索,进而导致训练不稳定、难以收敛。

CE-GPPO 通过研究将所有 token 分为四类,分别对熵有不同的作用:
导致熵坍缩的 token 类型:正优势高概率 token(PA&HP)、负优势低概率 token(NA&LP),优化这部分 token 会强化高概率选择或弱化低概率选择,加速策略的收敛。
导致熵爆炸的 token 类型:正优势低概率 token(PA&LP)、负优势高概率 token(NA&HP),优化这部分 token 会强化低概率选择或弱化高概率选择,维持输出多样性。
然而,由于 PPO 等方法广泛采用的 clip 机制,有些低概率的 token(包括 PA&LP token 和 NA&LP token)的梯度被直接截断,这意味着,PPO 在保证稳定性的同时,失去了平衡探索与利用的「安全阀」,从而导致了熵的不稳定变化,具体来说又分为以下两种情况:
PA&LP token 被裁剪,导致模型无法有效探索,进而造成熵坍塌的现象。
NA&LP token 被裁剪,导致模型过度探索,进而造成收敛延迟的现象。
现有的一些方法,比如 DAPO 中的 clip higher 方法拓展了裁剪的上界,仅仅纳入了一部分原本被裁剪的 PA&LP token,并没有解决过度探索的问题。因此,CE-GPPO 的核心目标是:在保证训练稳定的前提下,重新利用裁剪外区间低概率 token 的梯度,实现策略熵的精细调控,平衡模型训练过程中的探索与利用。
算法设计
基于上述洞察,快手 Klear 团队提出了全新的 CE-GPPO 算法,其核心思想是:不再丢弃被裁剪 token 的梯度,而是有控制地保留和缩放它们,让它们作为平衡熵变化,平衡探索与利用的 “阀门”。
核心机制
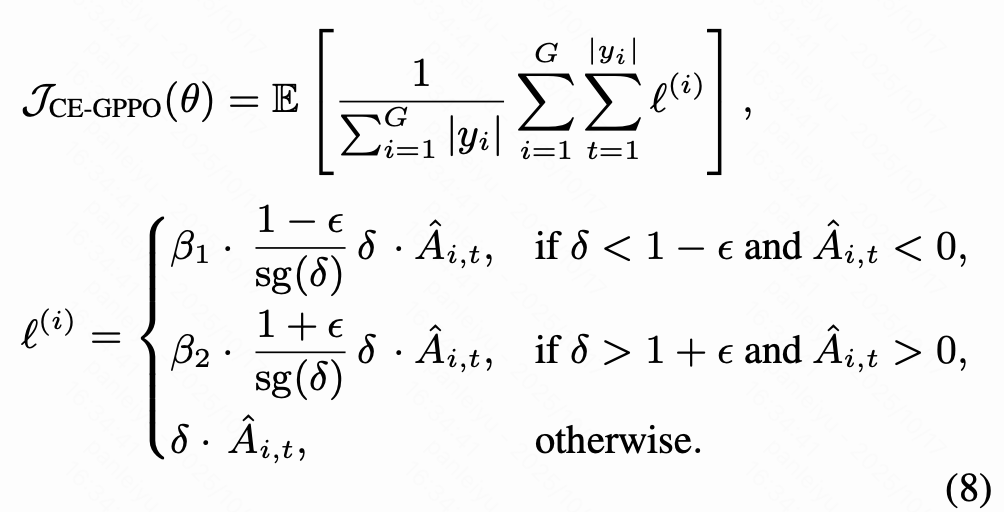
上式是 CE-GPPO 的目标函数,其在原 PPO 框架上引入了两项关键改进:
stop gradient 解耦机制:对超出 clip 区间的 token 应用 stop gradient 操作,在前向传播保持不变的同时在反向传播时恢复其梯度传导。
双系数控制 β₁ 和 β₂ :通过两个可调整的超参数对梯度进行缩放,其中 β₁ 控制原本被截断的 NA&LP token 的梯度,促进收敛;β₂ 控制原本被截断的 PA&LP token 的梯度,鼓励探索。这使得训练可以在探索与利用之间灵活调节。
梯度稳定性证明

上式是 CE-GPPO 的梯度表达式,可以观察到,虽然 CE-GPPO 引入了 clip 区间外的梯度,其仍然能够维持训练稳定,一个核心的原因是梯度幅度是可控的:裁剪区间外的梯度被限制在 β₁(1-ɛ) 或 β₂(1+ɛ) ,其中 β₁ 和 β₂ 通常接近于 1,避免梯度爆炸。公式的其他项与 PPO 的梯度表达式一致,继承了 PPO 的「保守更新」的特性。
实验结果
为验证 CE-GPPO 在稳定性与性能上的有效性,研究团队在多个数学推理基准上进行了系统实验,包括 AIME24、AIME25、HMMT25、MATH500 和 AMC23。所有实验均基于 DeepSeek-R1-Distill-Qwen 模型(1.5B 与 7B)进行训练。
主要观察:
CE-GPPO 在所有 benchmark 上均超越强基线方法。
提升最显著的任务为 AIME25 与 HMMT25,这类高难度推理任务对熵稳定性与探索能力最敏感,验证了 CE-GPPO 在保持探索性的同时确保收敛的效果。
模型规模越大,CE-GPPO 带来的收益越明显,说明方法拥有能够 scale 到更大规模模型的潜力。
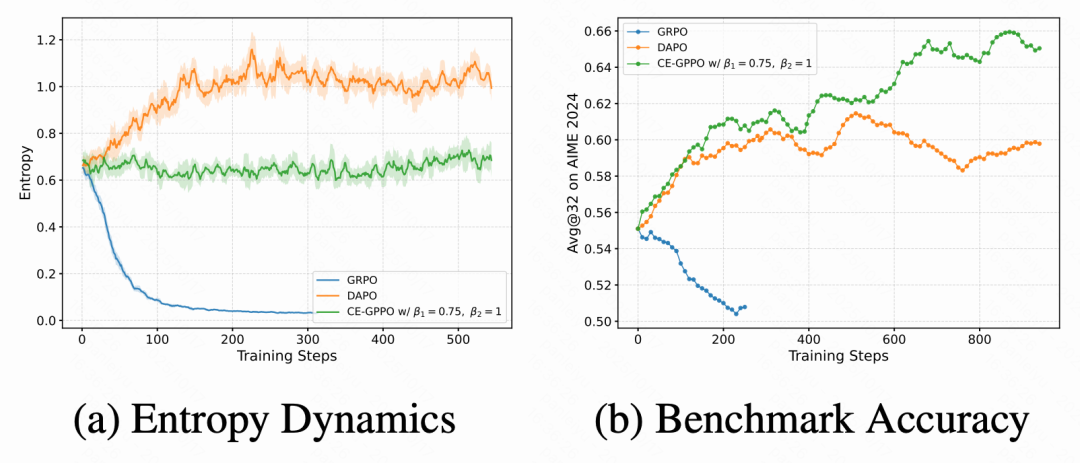
此外,训练过程中对比了各方法的熵动态曲线与验证集准确率变化:
GRPO 出现显著的熵塌缩,训练后期输出趋同;
DAPO 通过 clip-higher 缓解了塌缩,但存在 “熵反弹”,后期出现过度探索;
CE-GPPO 保持稳定且中等偏高的熵水平,全程无震荡,最终收敛性能更高。

实验分析
超参数对熵变化的影响
CE-GPPO 的两个核心超参数 β₁ 和 β₂ 控制了裁剪区间外梯度的权重,在 1.5B 与 7B 模型上进行了系统超参数实验,结果如图所示:
当 β₁ 较大(例如 β₁=1, β₂=0.5)时,模型更偏向利用,熵下降更快。
当 β₂ 较大(例如 β₁=0.5, β₂=1)时,模型倾向于探索,熵下降变缓且保持在较高水平,甚至也有可能出现熵上升的趋势。
这一现象验证了 CE-GPPO 的 “可控熵调节” 机制:通过调整两个系数,训练可以在「快速收敛」与「持续探索」之间取得理想平衡。

熵变化与性能的关系
进一步的,研究还分析了熵变化与性能之间的关系,并得出了以下结论:
维持相对高且稳定的熵通常有利于训练过程中的持续性能提升,熵的过快下降和上升都不利于模型性能的稳定提升。
给予 PA&LP tokens 更大的梯度权重 β₂ ,同时给予 NA&LP tokens 更小的权重 β₁ ,有助于维持模型的探索能力,更有利于性能提升。
CE-GPPO 对超参数具有鲁棒性,在不同规模模型上,β₁=0.5/0.75 和 β₂=1 的设置都能带来显著的性能提升。
训练稳定性实证性验证
为了验证 CE-GPPO 的训练稳定性,研究可视化分析了训练过程中 KL 散度和 gradient norm,并与 GRPO 的训练动态进行对比,结果表明,CE-GPPO 虽然纳入了 clip 区间外 token 的梯度,但由于梯度限制在固定区域,所以其整体训练过程是平稳的。

与其他 RL 算法比较
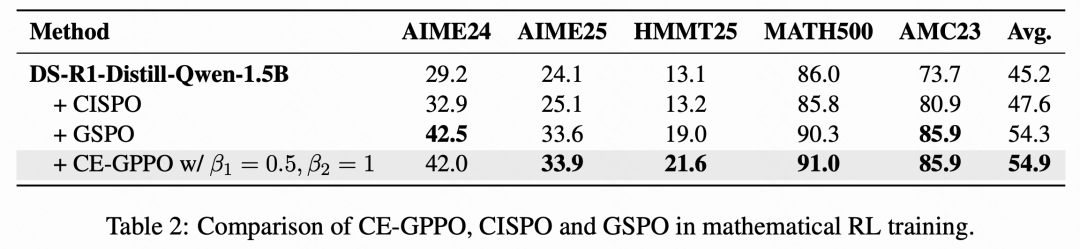
研究还对比了 CE-GPPO 与其他近期提出的强化学习算法的性能,比如 CISPO 和 GSPO 算法,CE-GPPO 在不同基准上取得了最好的结果,进一步的,可以分析出如下结论:
CISPO 虽然采用了类似的通过 stop gradient 的方法保留梯度,但在训练后期仍出现熵急剧下降和性能崩溃的现象,它与 CE-GPPO 的区别主要在于 CE-GPPO 继承了 PPO 的悲观更新的特性,并且 CE-GPPO 对于 clip 区间外梯度的管理更加细粒度,这些原因导致 CE-GPPO 的性能超过 CISPO 算法。
GSPO 使用序列级别的重要性采样,这导致了大约 15% 的 token 被裁剪,而 CE-GPPO 方法纳入了 clip 区间外 token 的梯度,其对于采样样本的利用率更高,所以性能更好。
与其他熵调节方法的比较
最后,研究还比较了 CE-GPPO 和其他熵调节的算法,比如传统的熵正则化以及 DAPO 的 clip-higher 策略,结果表明:
直接加入熵正则项虽然能延缓熵坍缩,但其对超参数稀疏很敏感,并且性能均较差。
DAPO 的 clip higher 策略虽然能纳入部分高熵 token 的梯度,但在训练后期出现熵反弹和过度探索的现象,这限制了模型的收敛。
CE-GPPO 全程保持了较为平稳的熵曲线,并且性能随训练不断提升,达到了最优性能。


© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










