虽然电子工程专辑过去大半年都没写过任何Panther Lake的技术展望与解析,但这代PC处理器产品对Intel公司未来发展至关重要的属性,想必是绝大部分关注Intel的读者都十分清楚的。
尤其Panther Lake将首度搭载Intel 18A工艺——包含RibbonFET晶体管结构(GAAFET)和PowerVia背面供电技术的应用。18A工艺能否按期量产,都相关于市场对这家公司的发展信心,也相关于企业竞争力与营收数字。
可以说这一代酷睿Ultra处理器和同代的至强处理器,对Intel而言都关乎命运未来。我们此前就撰文提过Intel 18A工艺能否准时交付对现如今Intel的意义已经不单是展示技术先进性这么简单了。最近的媒体会上,高嵩(英特尔公司客户端计算事业部副总裁兼中国区总经理)再度谈到预计明年年初,OEM厂商就会有搭载Panther Lake处理器的笔记本与PC产品上市。

虽然现阶段还没有这一代酷睿Ultra处理器的具体产品信息公开,但对Panther Lake的架构与工艺有个基本了解,也有利于我们对明年的PC产品做前瞻,同时也能更明晰Intel在PC处理器这一基本盘内,是否还有足够的竞争力。
本文篇幅较长,可按照需要做选择性阅读(若不关心实现细节,可仅阅读每个章节的开头部分):
Part 1 制造(Intel 18A)与封装(Foveros)工艺
Part 2 架构与定位综述
Part 3 CPU升级
Part 4 iGPU升级
Part 5 NPU与总结
先谈谈制造与封装工艺
因为这大半年来,个人行程安排实在太满,很难腾出空余时间来关注Panther Lake的各路传言信息;加上Intel在最近一次媒体会上公开有关Panther Lake的信息,在我们看来也远远称不上“干货”,所以本文只能从面上简单谈谈此系处理器新品。
首先来看看Panther Lake芯片的制造工艺与2.5D/3D先进封装技术。Panther Lake沿用了酷睿Ultra一代(Meteor Lake)以来基于chiplet的设计,整颗芯片包括有计算模块(compute tile)、图形模块(GPU tile)、平台控制模块(platform controller tile)、基础模块(base tile),以及用于结构填充和支撑的填充模块。

可能是吸取Arrow Lake(酷睿Ultra 200S/H系列)和Meteor Lake(酷睿Ultra一代)的经验,这代芯片的分片方式显然保守了不少。CPU、NPU、媒体与显示引擎、IPU、内存控制器等关键组成部分都位于计算模块之上;图形模块也就是iGPU;平台控制模块有IO与连接相关的IP(如Wi-Fi, 蓝牙, PCIe等)。
所有die/chiplet,都藉由2.5D Foveros-S先进封装“缝合”到一起。不过Intel仍旧表示,这代产品有着不错的规模化(scaling)能力,借助模组与内存组合可覆盖不同价格区间的终端产品,而且藉由缩放就能面向PC以外的应用。这似乎也一定程度相关于Intel的scalable fabric以及die-to-die互连方式。
前道制造工艺方面,Intel的官方资料提到,Panther Lake的计算模块(compute tile)采用Intel 18A工艺,图形模块(GPU tile)基于Intel 3;平台控制模块(Platform contoller tile)则无意外地仍然采用外部foundry厂的方案——这片die的具体工艺是台积电N6。
不过还有一则信息提到:最高配规格16个CPU核心版本的Panther Lake——后文的参数列表会提到——其中的图形模块(12个Xe3核心)会采用台积电N3E工艺。这可能一方面表明了Intel 3工艺产能并不理想;另一方面也表明Intel 3可能是个与台积电N3E,在器件物理尺寸上很相近的工艺——不要认为这是废话,不同foundry厂的工艺节点即便名字里头的数字一样,也不能代表它们的器件物理尺寸一致甚至相近。
同时,我们也看到Intel Products业务现在似乎更多地开始对同一种设计采用multi-foundry的方案(iGPU一边用自家工艺,一边用台积电工艺;此前Arrow Lake也有相似策略),体现的的确是设计方法标准化及相比从前的转向——不知道是否如此前Intel Foundry所说,在尝试多foundry设计规则的某种抽象。
这里稍微谈一谈Intel 18A工艺:虽然网上有关18A工艺的热议不少,但我们目前尚不掌握任何18A工艺的CD关键物理尺寸信息,也就更不可能知道晶体管密度之类的数字,尤其大部分读者可能会关心Intel 18A与竞争对手的2nm或其他节点对比——待Panther Lake上市,或许会有相关发现。
本次媒体会上,Intel针对18A工艺实则只说了两点(1)RibbonFET,也就是GAA(Gate-All-Around)栅极四面环抱的器件结构;(2)PowerVia背面供电技术的采用。
其实电子工程专辑对于这两个技术已经写过不少技术文章。毕竟在<2nm工艺节点的时代,GAAFET器件结构、BSPDN背面供电网络这两个技术点本来就是三家尖端制造工艺foundry厂争夺的焦点。不止是Panther Lake,面向数据中心的至强处理器(Clearwater Forest)也会采用这些技术。

RibbonFET是Intel的GAAFET器件名称:相较于此前的FinFET,nanosheet电流通道横置——被栅极从四面环绕,实现更好的沟道控制。
RibbonFET似乎总共有4片nanosheets,一直以来的宣传图都展示了这一点——不过这次Intel提到GAA结构的价值还在于nanosheet的宽度、层数“都是可以调节的”,“搭配工作电压不同阈值,同一个工艺平台可以衍生出不同优化方向的晶体管规格,给客户提供良好的设计自由度,包括高性能、低功耗的选择”——这是从foundry厂的角度谈GAAFET的价值。
另外据说18A节点的RibbonFET“重新定义了晶体管控制的逻辑,为下一步尺寸缩减预留了空间”,为“后续节点延展”做好了准备。
PowerVia作为Intel的BSPDN解决方案应用于18A,也就让18A节点成为市面上最早商用背面供电的产品——我们此前报道过,台积电和三星代工很快也会跟进。将供电轨移到晶圆背面之后,Intel提供的数据是,密度和单元利用率提升10%,同时因为供电给晶体管的路径更短,所以从封装到晶体管的压降减少了30%,“尤其为高频电路提供干净的电流”。
Intel表示“栅极环绕技术释放晶体管的潜能,背部供电技术扫清了供电上的障碍,结合RibbonFET与PowerVia两项技术,共同支撑起了Intel 18A工艺在密度和能效上的同步提升”。因为电子工程专辑对这两技术的撰文已经不少,本文不再深入探讨。

相对数据方面,Intel 18A相较Intel 3每瓦性能提升>15%,单位性能功耗降低>25%;另外芯片密度实现了30%的提升。掌握Intel 3工艺相关数字的读者,或许有机会大致判断,Intel 18A具体达成了怎样的晶体管密度提升——感觉在chiplet时代,具体在封装层面的收益还是很难做出简单判断的。
另外Intel还给出了工艺的HVM预期,虽然PPT中的缺陷率也只是个相对值、没有标尺,但Intel明确了“相比同时期,18A的良率大于或等于此前的每一代节点;预计今年第四季度就能达成大规模生产的良率目标,全面进入高产能生产阶段”;包括实现18A工艺量产的“美国亚利桑那Fab 52晶圆厂本月已经全面投入运营”。

最后也稍微谈一谈Panther Lake后道封装的Foveros-S工艺。长期关注电子工程专辑的读者对于Foveros一定也是不陌生的,这是Intel的2.5D/3D先进封装技术名称,可类比台积电的CoWoS技术方向。
Foveros-S/R/B都属于2.5D封装方案,不同变体的差异在于Panther Lake所用的Foveros-S采用了硅中介(silicon interposer);而Foveros-R的R代表了RDL重排布层;Foveros-B可将硅桥(silicon bridge)与RDL结合。
这张图提供了Foveros 2.5D的关键数据,包括bump pitch(凸点间距)<25μm,C2C能耗效率0.5pJ/bit等。Foveros-S是早在2019年就开始量产的技术。值得一提的是,Clearwater Forest已经开始应用Foveros Direct封装方案,也就是Intel的混合键合3D垂直堆叠方案——还是比我们预想得更快的。
Panther Lake芯片:接棒轻薄本、全能本
Intel对于Panther Lake的定位是:兼具Lunar Lake(酷睿Ultra 200V)的能效与Arrow Lake(酷睿Ultra 200H)的性能的处理器产品。
Panther Lake的确应当属于Lunar Lake与Arrow Lake-H这两条产品线的继任者——也就是说明年的轻薄本、全能本处理器会由Panther Lake担纲主力;更高性能定位的Arrow Lake-HX/S——游戏本与台式机处理器,应该会由Arrow Lake Refresh接替(不过明年台式机的CPU产品线预计会更复杂,不在本文探讨范围内,不再深入)。
虽然Panther Lake的产品信息尚未公开,但Intel已经给出了基于核心数量、IO与内存支持的基本配置信息,如下图所示:

理论上接替Lunar Lake或者说面向超轻薄本的处理器应该是最左边的Panther Lake 8核CPU版,iGPU总共4个Xe核心,内存支持为LPDDR5X-6800和DDR5-6400,12个PCIe通道;
而接替Arrow Lake-H、将主要应用在全能本上的Panther Lake则为16核CPU版——也切分了不同的iGPU核显规格,分有4个Xe核心版与16个Xe核心版;最高内存规格支持也有差异,分别为LPDDR5X-8533/DDR5-7200与LPDDR5X-9600...PCIe通道数也分成了20与12条。
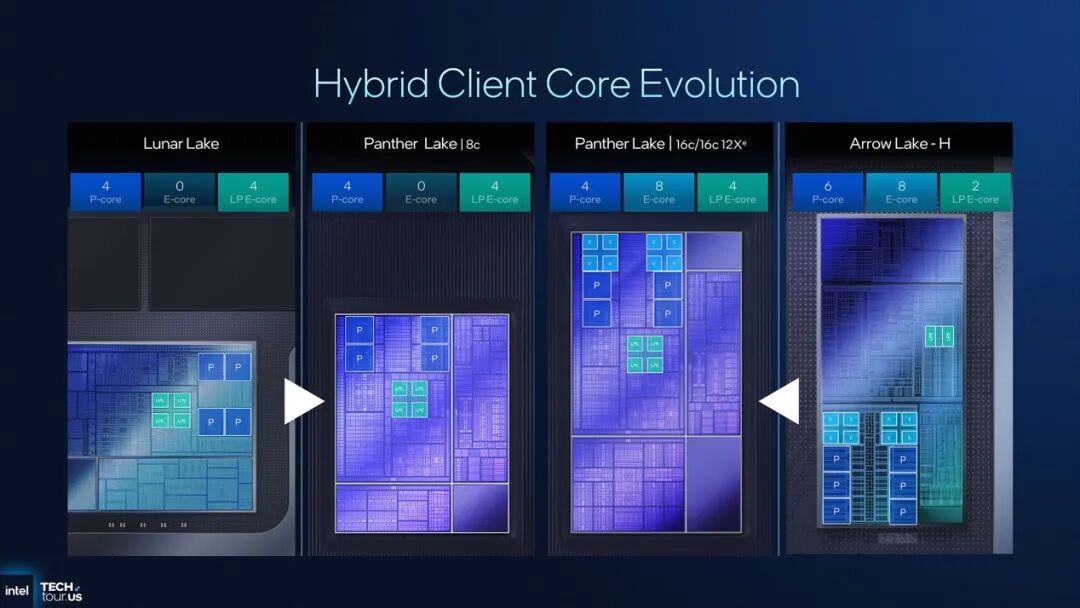
有两点值得单说:(1)8核版的Panther Lake虽然看起来是接替Lunar Lake的,即负责高能效、长续航的轻薄本。但实际上其CPU之外的规格堆料是不及Lunar Lake的,尤其iGPU和内存支持上。我们认为这对轻薄本受众而言反而是更合理的,因为轻薄本用户通常不会特别在意游戏及专业图形类需求。
但需要指出的是,Panther Lake全系都没有再沿用Lunar Lake那种将DDR内存纳入处理器封装的方案,而且应该也没有延续PMIC这种中心化的供电与管理解决方案——可能也是基于成本的考量。
虽然Intel在宣传中也提到Panther Lake的能效表现出色,或者说“延续Lunar Lake能效表现”,但暂未提及Panther Lake在系统闲置状态下的功耗情况。而取消片上内存、PMIC设计,就让我们比较在意Panther Lake轻薄本的续航是否还能达到Lunar Lake的程度。
有关低功耗设计,前两代的Low Power Island(低功耗岛)设计思路得以延续——这是个单独电源域、芯片之上的一部分,低功耗能效核LP E-core就位于该岛——也没有接入L3 cache。后文会提到,Panther Lake的LP E-core架构换代Darkmont。
不知道在新工艺节点(尤其PowerVia技术也能节约功耗)和核心IP升级带来效率提升,但抛弃片上内存、PMIC设计的情况下,Panther Lake能否为笔记本的续航带来提升或至少持平——这是轻薄本用户都很关心的问题。

(2)16核Panther Lake两个版本,以iGPU核显规格区分。其中4个Xe核心的版本,猜测更多应该是准备搭配独显的——尤其给到的PCIe通道也相对充沛;而12个Xe核心的版本显然强调了核显性能——应当是目前所有PC处理器之中最强核显之一(抛开隔壁Strix Halo这种标志性意义大于实际意义的产品不谈)。
两个不同版本的16核Panther Lake不是通过制造过程中的binning process得来,因为Intel渲染的宣传图出现了3种不同的die(如上图),对应8核版、16核4Xe版、16核12Xe版(还是多foundry方案,这真的不会大幅增加成本吗?)。
(3)有关CPU异构核心,Panther Lake的CPU部分仍旧延续了性能核P-core + 能效核E-core + 低功耗能效核LP E-core的方案。P-core代号Cougar Cove,E-core和LP E-core代号Darkmont,用于取代上一代的Lion Cove和Skymont。后文会更详细地谈到这两种核心。
8核版Panther Lake为4 P-core + 4 LP E-core的方案,而16核版则为4 P-core + 8 E-core + 4 LP E-core。16核版的P-core相较上代少了2个,而LP E-core多了2个——从Intel提供的多线程性能数据来看,这也没有影响到Panther Lake的多线程吞吐能力。


仔细观察不难发现,Panther Lake的LP E-core也是Darkmont,相较Arrow Lake的LP E-core(Crestmont)更新了两代,则多线程性能、整体能效提升应该是可预期的...
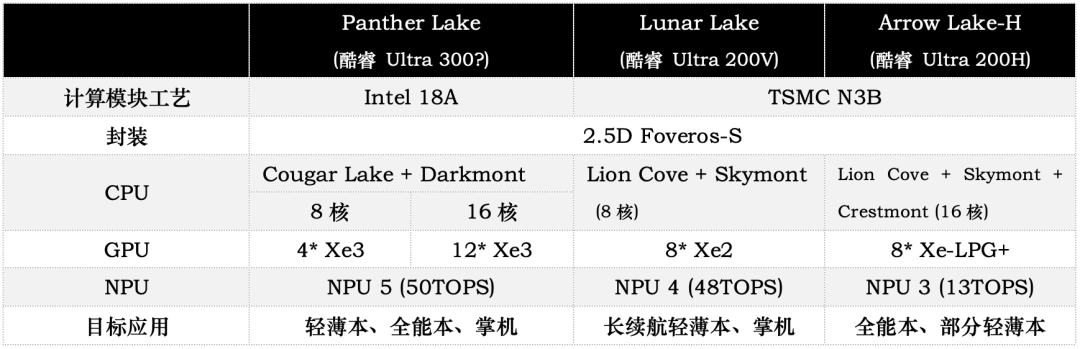
我们针对其中的关键信息,做了两张相比上代芯片的对比表格,如上图所示。除CPU、GPU之外的其他信息还包括NPU架构换代,算力应该是保持了全系一致(50TOPS);
另外还有此处没有列出的集成的IPU换代(IPU 7.5)——用于摄像头视觉信息处理的ISP;无线连接MAC控制和配套软件,加入Wi-Fi 7 R2功能支持,支持蓝牙LE Audio低功耗音频、蓝牙6信道探测、双蓝牙,以及引入新版无线连接套件ICPS 5.0...这部分内容本文不做展开。
消它们带来的影响吗?这也是个很值得观察的问题。
CPU:核心IP改良、调度机制换新
如前所述,Panther Lake的CPU部分换用了两种新的核心IP:Cougar Lake和Darkmont,用去替换上代的Lion Cove和Skymont。从介绍来看,Cougar Lake和Darkmont应当都属于基于前代核心的改良款。
直接来看两种核心IP改良带来的性能与能效提升成果,如下图所示:
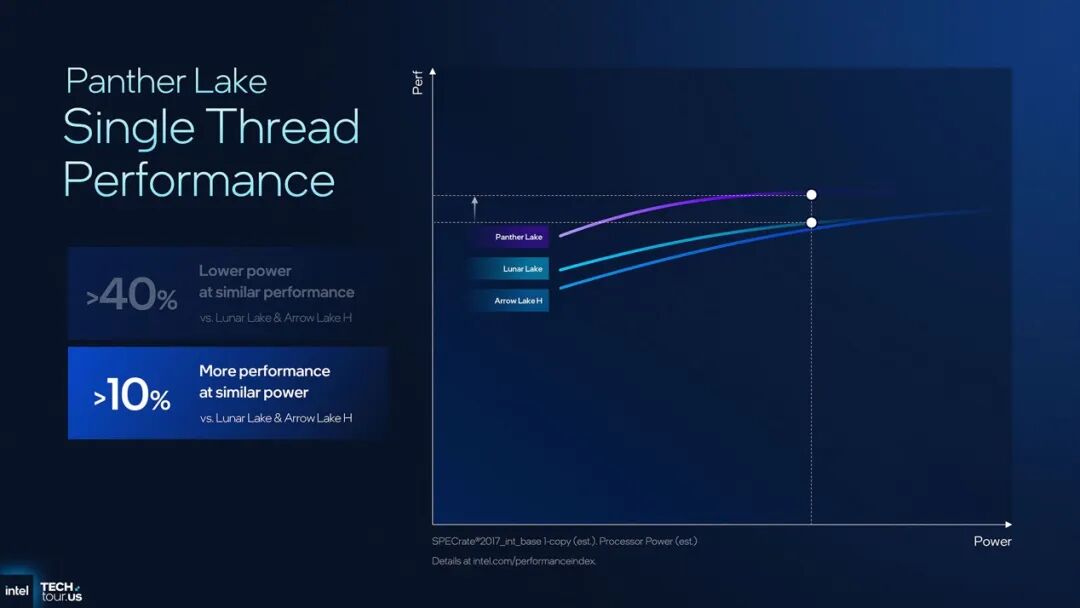
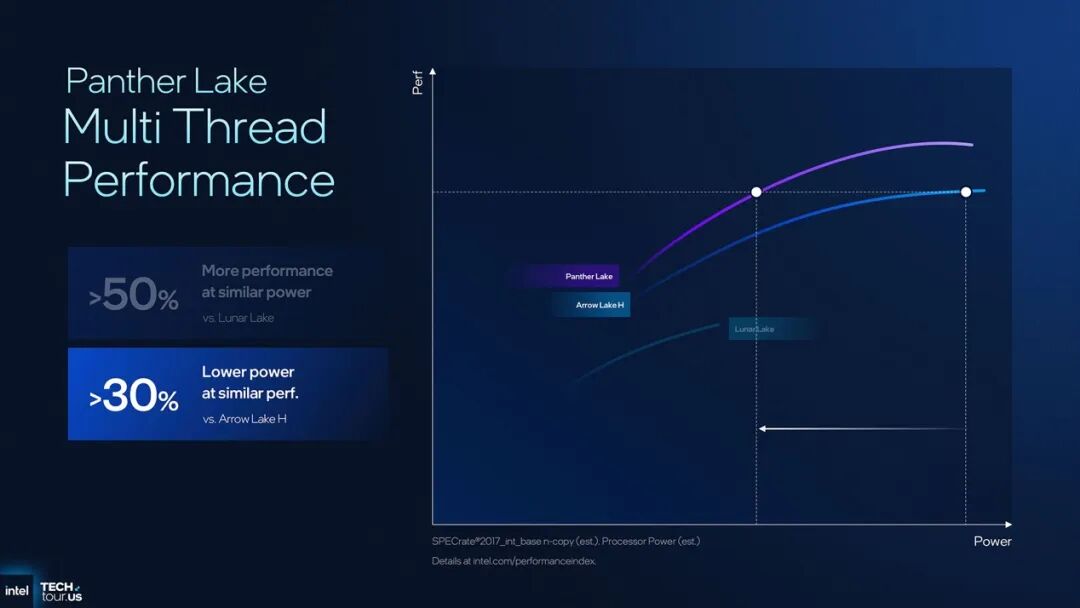
单线程性能方面,Intel的数据是相较Lunar Lake和Arrow Lake-H,在相似性能之下功耗降低>40%,同功耗下则可提升>10%的性能——这代表的就是Cougar Lake的能力了。多线程性能方面,对比Lunar Lake,相似功耗下Panther Lake性能至多提升>50%,而同性能功耗降低至多>30%——表明这代E-core的表现也是很亮眼。(基于SPECrate2017_int_base)
看这两份数字都还算理想的。不过Intel没有给出峰值性能提升数字。实际上关乎峰值性能的,在于Panther Lake处理器的核心频率高低。这也直接关乎到Intel 18A工艺的实际水平;就只有等酷睿Ultra新品问世时才有机会知晓了。
更具体地,针对性能核Cougar Cove,Intel列出的关键提升有:18个执行端口;共享的L3 cache增大到18MB(Lunar Lake为12MB);“基于AI的电源管理”——“基于用户使用对CPU负载的动态变化,更好地调配资源,及时响应负载变化”;
TLB size增大;分支预测增强;内存消歧(memory disambiguation)达成对存储敏感型负载的效率提升;16.67MHz更精准的时间间隔;PPA优化;还有微架构的其他调整,包括拆分乱序引擎、更广泛的调度等...

Intel在宣传中着重强调了Cougar Cove的三项改进:内存消歧、TLB、分支预测提升。内存消歧旨在提升存储敏感型负载的性能核效率:在当代CPU的乱序执行过程中,load和store也就是读和写指令可能存在前后相关性;内存消歧就是用来预测和决策load是否依赖于上一个store操作的机制,也就提升了效率。
Intel对于Cougar Cove之中的内存消歧是这么说的:“它能精准预测哪些操作可以并行执行,哪些存在真实依赖。一旦预测错误或检测到实际冲突,它能以极快的速度进行恢复(recovery),确保程序的正确性。”最终起到提升CPU与内存之间带宽利用率的目的。“相比Lion Cove做了更好的提升,消歧技术性能更可靠,细节更准,恢复更快。”
TLB本身无需多做解释了,Cougar Cove令TLB容量达成1.5倍提升,主要是因为Intel 18A工艺提升了器件密度,也就有机会塞下更多的资源;更大的TLB有利于降低TLB未命中率、实现更大的内存区域覆盖,对于存储敏感型应用也产生正面价值。只是不清楚Cougar Cove的TLB层级结构是怎么设计的。
分支预测的提升,主要是“继承Lunar Lake中新颖BPU方案”,基于该方案“进一步提高准确性”,并“增加结构容量以降低延迟”。

能效核Darkmont在Panther Lake之上肩负了更大的多线程性能使命,毕竟这次的P-core数量不及上代多了。不过Intel也提到Darkmont在低功率释放区间,能够以更低的功耗达成相较Raptor Cove(酷睿13、14代CPU的核心)的更高性能(SPECrate2017_int_base,固定频率,且不考虑存储子系统影响)。
强调有关Darkmont核心微架构的亮点涵盖:保留26个调度端口;同样引入内存消歧;4MB L2 cache,维持128B/cycle带宽;提升nanocode性能;以及分支预测、动态预取器控制、深度队列提升等。
其中,内存消歧与Cougar Cove的改进相似;分支预测则通过“提升容量预测更稳”,“提高准确性降低延迟”;“引入动态的pre-fetcher控制,根据负载变化来动态响应”,甚至节约功耗;
而nanocode作为相比microcode更低一个层级的指令,实则是在Skymont核心中就引入的——它实现了更靠近硬件、更高效的资源分配——Darkmont的优化在于nanocode覆盖了更多的指令,“以前只能针对某几种类型的负载,而Panther Lake在更多场景中实现了覆盖,能够更充分发挥能效核的性能和能效。”

拔高视角、从SoC层级来看,Intel还提到了三点:(1)Panther Lake的E-core接入了L3 cache——虽然听起来是废话,这一条主要是比对 Lunar Lake的LP E-core没有接入L3 cache,强调Panther Lake的E-core有着更强的性能;不过话说回来,Panther Lake的LP E-core作为低功耗岛的一部分,其实也没有接入L3 cache。
(2)只不过相比Meteor Lake和Arrow Lake,Panther Lake的LP E-core的L2 cache容量翻倍——LP E-core也因此能承载更多工作,不致如Meteor Lake时期那般不堪用。
(3)和Lunar Lake一致,保留了8MB memory-side cache(类似于system level cache,上图左下角)——不同处理器都可以访问,不过据说Intel针对这部分的充分利用还在做更进一步的调优;内存控制器也保留在了计算模块上——Arrow Lake饱受诟病的一点也在于内存控制器与CPU核心位于不同的两片die。
还有一些数据一致性机制的调整都旨在减少多核心或多die访问相同数据时的同步问题,也让系统层面未来有机会扩展到更高的核心数目。另外,国内媒体会上,Intel没有再谈封装层面的一致性机制:从外媒的报道来看,若上升到封装层级,据说某些需要跨die的共享工作负载(如视频编码、GPU加速的计算负载)也能够直接以共同数据结构的方式,连接不同处理单元,也不需要维护单独的内存拷贝。
具体情形未知,未来有机会我们可就系统级的更多优化机制再做深入探讨。

对应的,基于CPU核心与微架构调整,
Intel Thread Director(硬件线程调度器)也做了优化和改进。Thread Director的基本机制是通过ACPI CPPC2定义的Hardware Feedback Interface(HFI)完成工作;对应的调度参考信息由SoC控制器形成HFI表格,向上提供给操作系统,实时指导scheduler做跨不同核心的调度工作。不同PC OEM厂商为笔记本设定的不同性能或电源模式,就是通过Intel的平台软件层(Dynamic Tuning Technology,构建于微软的Processor Power Management框架之上),去通知SoC电源管理逻辑——SoC电源管理再与Thread Director配合,并面向操作系统scheduler提供hint,最终执行调度。
受限于篇幅,本文不对更新后的Thread Director做展开:Intel的宣传点大致包括不同核心间的高度并行实现;优化负载分类模型——可以给到操作系统更准确的参考;基于OEM预设电源模式和更多信息来调整给到操作系统的反馈表;
“扩大‘繁忙’用例的覆盖范围”——也就是Thread Director会在更多场景下给出调度参考;以及“操作系统隔离区”(OS containment zones)——操作系统可以限定特定负载跑在特定核心组——比如据说“混合”zone之下,游戏场景负载集中分配在E-core与P-core,甚至相较“不分区”有助于实现更低功耗下的更高性能。
值得一提的是,据说这次Intel在平台软件层面给出了“智能自动切换”特性,在Windows的平衡性能模式下,可以“自动根据工作负载切换到定义好的性能模式”,令设备处在闲置状态时更省电、需要性能时达成更强的性能释放。Intel给出的数据是,平衡模式下,采用智能自动切换,能实现UL Procyon Office和Cinebench 2024单线程性能测试19%的成绩提升。
这应该也是很多Windows用户期望看到的:具体实践估计还要看OEM厂商的决策。
iGPU:Intel有史以来最大核显,多帧生成也来了
iGPU核显是我们看来Panther Lake升级的最大亮点:尤其12 Xe3核心版的Panther Lake,达成了Windows PC处理器之中,除Strix Halo这种相对难买、价格还贼高的产品之外的最强核显:相比Lunar Lake提升超过50%的图形性能;能效方面,相比Arrow Lake-H的“每瓦图形性能”提升超过40%。
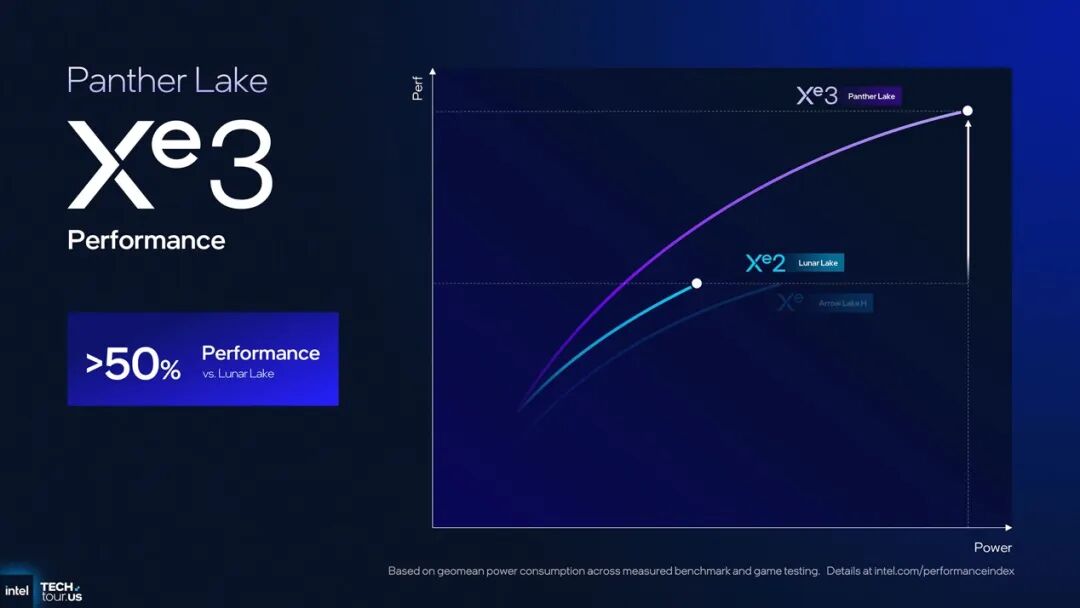
虽然>50%的性能提升在后半程也需要靠功耗来换——达成极致游戏性能大约会成为考验OEM厂商做散热与供电的一部分,但这部分提升在Windows PC核显领域也绝对堪称惊艳。
去年我们体验过Lunar Lake笔记本,Lunar Lake所用的8个Xe2核心达成大约4200分的3DMark Time Spy图形分——我们说要玩当代3A游戏中画质完全可行,玩多年前3A游戏画质全开也没压力……
若Intel所说Panther Lake核显性能提升50%为真,则其图形渲染性能应该就已经追上笔记本GeForce RTX 3050独显了——真正的核显玩3A不是梦。
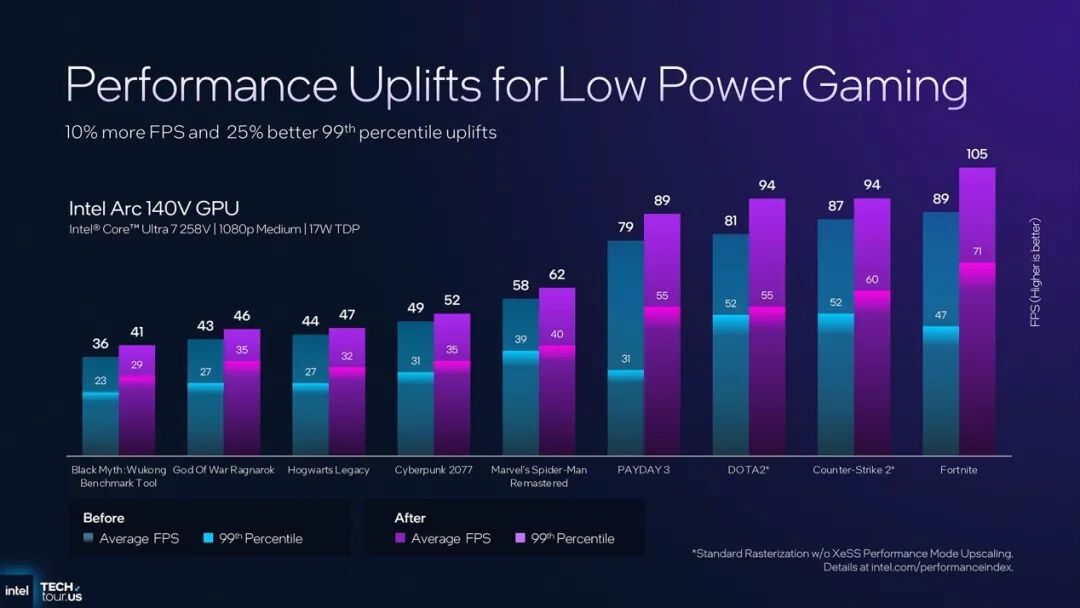
实际游戏测试中,同样限定17W TDP,12 Xe3(Panther Lake)相较8 Xe2(酷睿Ultra 7 258V)在部分3A及网游中的帧数提升如上图——注意所有游戏皆为1080p中画质。
前一阵有传言说Intel砍掉了Arc显卡业务部门,从Panther Lake的iGPU堆料,以及Intel在媒体会上顺带提了句下一代Arc独显会采用Xe3P架构来看,Intel做显卡的决心还是在的。
就是不知道未来12 Xe3核心版Panther Lake的笔记本售价几何,考虑到iGPU这么大的占地面积,Intel也说是自己“有史以来性能最强、die size最大的iGPU”……这两年PC平台卷核显的竞争态势还真是一点没放松。老黄表示很受伤…


这一代Xe3在架构设计上更多考虑了可扩展性,所以才在设计层面推出了4核与12核两种规格,不知道未来会不会有其他Xe核心数目的SKU(也可能通过binning来达成核心屏蔽)。4核版与12核版的高抽象层级框图如上图所示。
从这两张框图可见,Xe render slice渲染切片单元的构成是比较灵活的——4核版的Xe3核显每个render slice有2个Xe3核心,2个RTU光线追踪单元,以及其他固定共享图形单元。所以核显总共4个Xe3核心,配套总体4MB L2 cache。
而12 Xe3 iGPU的每个render slice扩展到了6个Xe3核心——上代Xe2的单个render slice可容纳最多4个Xe核心。实现了iGPU核显共12个Xe3核心;配套更多的RTU光追单元,更多的像素后端、几何管线、采样器,以及总体共享的16MB L2 cache。

看单个Xe3核心内部,每个Xe3核心内有8个512位的矢量引擎,8个2048位的XMX矩阵扩展引擎——专用于AI加速的部分;L1 cache/SLM容量增加了1/3。
这次的矢量引擎也变宽了,线程数最多增加25%,增加“可变寄存器分配”,整体提升矢量引擎的使用效率和并行数量,同时支持了FP8反量化。
XMX矩阵扩展方面,每个XMX支持的单周期操作数分别为TF32 1024、FP16/BF16 2048、INT8 4096、INT4/INT2 8192——对峰值算力数字感兴趣的读者可以去查一查Xe2的对应数据,相比上代的理论性能提升幅度应该是不小的。
顶配12个Xe3核心之中XMX所能达成的最高INT8算力为120 TOPS,也就是很多人关心AI PC的算力组成部分所在。
Intel还强调了RTU光线追踪单元的加强,“支持异步光线追踪的动态光线管理”,“通过更好的调度机制,在拥塞即将到来时降低光线分发频率,提升光线追踪负载性能。”以及在固定功能管线部分,采用新的URB(Unified Return Buffer,用于线程或固定功能单元的数据传输)管理器——支持仅部分URB传输同步,“帮助最高支持2倍异向性过滤”以及“模板测试速率最高提升2倍”。
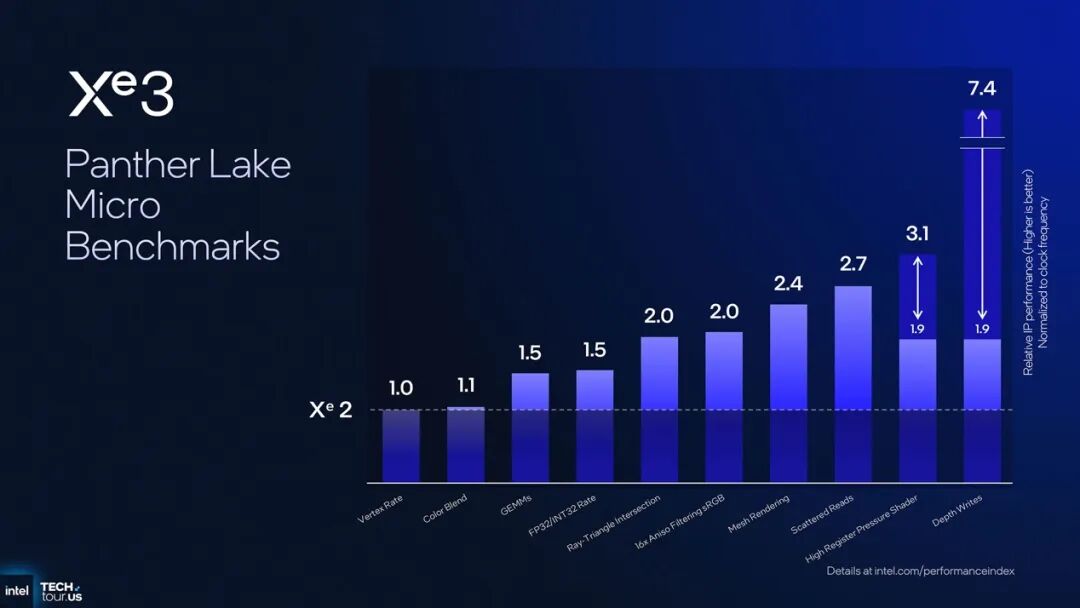
以上是相较于上代Xe2,本代Xe3在部分micro-benchmark中的性能提升。“后端部分由于Xe3保持同样的硬件资源,定点速率、颜色混合这类性能基本保持不变”;“在主要相关运算单元的GEMM、FP32/INT32速率测试中,性能提升约1.5倍,源于更大的render slice设计”;
“微架构层面的新特性引入,则帮助我们实现了在如射线三角形焦点、滤波、网格体渲染、分散读取方面的2倍性能提升;对一些关键单元的特殊优化,则让高寄存器压力着色器和深度写入测试拿到了更大幅度的提升。”
图形特性支持上,现在不得不谈的一定少不了AI:尤其基于AI的超分、帧生成,乃至多帧生成。无论你是否喜欢DLSS/XeSS这类技术,是否认可AI生成而非渲染的像素与帧,它们都实打实地提升了游戏静态清晰度与动态流畅度,而且正成为图形学事实上的标准。
关注XeSS技术的读者应该知道,XeSS2在超分(XeSS-SR)之外,也新增了帧生成(XeSS-FG)核低延迟(XeLL)配套技术,虽然游戏生态建设进度还不及绿厂,但作为一种开放技术,实则我们已经能在很多游戏里看到XeSS选项,至少超分特性已经有了。
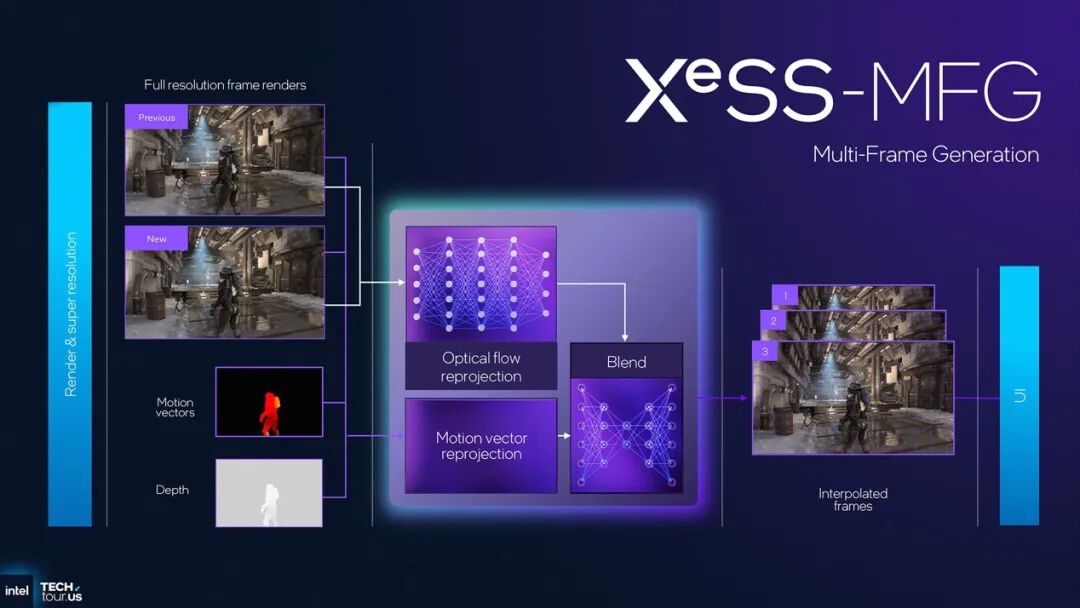
这次随Panther Lake及Xe3新核显的发布,Intel也开推了XeSS-MFG多帧生成——也算是意料之中:即在渲染的帧之间生成、插入不止1帧,倍增游戏帧率,简单流程如上图所示。媒体会上Intel并未谈到有关XeSS-MFG的实现细节及生态构建情况(如预期加入支持的游戏),或许未来的Arc独显发布会上有机会听到更多相关XeSS-MFG的信息。
Xe媒体和显示引擎部分在此也多提一句:新增10bit AV1、AVC和索尼XAVC格式的支持,显示引擎开始支持eDP 1.5标准;据说在效率上,两者也做了升级——虽然实际上媒体和显示引擎并不在图形模块(GPU Tile)上。
AI PC还在延续:NPU瘦身,将来走向Agentic AI
最后不得不提的当然就是AI PC的话题了。Intel这些年推AI PC始终在坚持XPU驱动的AI能力,即CPU、GPU、NPU都出力,借助Intel的OpenVINO实现多处理器的AI推理协同。
从XPU的角度来看,除了前文已经提到Xe3 iGPU的XMX引擎能带来120TOPS的INT8算力,CPU部分提供10TOPS算力,还有专用加速单元NPU的AI算力保持与Lunar Lake的基本一致为50TOPS——所以最高配Panther Lake所能提供的AI算力为180TOPS。

相关Panther Lake换新的NPU 5这里做个简单介绍:新版NPU的核心设计理念应该是die size的缩减或面积效益的提升。不仅在Intel 18A工艺带来的器件微缩,还在于NPU 5整体增大了神经计算引擎(Neural Compute Engine)及其中的MAC乘加矩阵——单个引擎算力翻倍;
但单个切片中的神经计算引擎数量缩减到了3个(12K MAC, 4.5MB Scratchpad RAM, 6 SHAVE DSP, 256KB L2 cache),“有效提升运算效率、提升die size利用率”,总体实现了单位面积内TOPS性能>40%的提升。所以在与Lunar Lake保持相似INT8算力(50TOPS vs 48TOPS)的前提下,NPU的占地面积应该是有了大幅缩减的——估计也考虑对冲因iGPU增大带来的成本增加。
另外还有一些更具针对性的优化,比如最新激活函数的支持、原生FP8/INT8运算支持等,在“部分主流AI负载,尤其LLM中带来更好的用户体验”。
这部分最后值得一提的是,Intel在媒体会上也特别说到未来期望“通过软件创新,赋能不同级别的AI智能体应用”——大致意思应该是对现在流行的、结合不同agent及具备深度思考能力的Agentic AI的本地推理支持。大约这也能在AI模型进化的加持下,带来更好的、更有实际价值的AI PC体验。
最后的最后,如果让我们给Panther Lake划个重点,那么首先必然是Intel 18A工艺的应用:GAAFET晶体管及背面供电技术的真正大规模商用,若能如预期般达成在明年初的交付,无疑很快,我们每个人都能借助PC享受到最新的半导体尖端制造工艺;另外对18A工艺器件关键物理参数感兴趣的读者,也应当关注一下传说进入了埃米时代的这个新节点,及其与竞品2nm节点的对比。
其次是Panther Lake在iGPU核显规格上的堆料,最高配12个Xe3核心,令Panther Lake成为真正意义上的“大核显”。它对Intel持续推广自家的GPU生态有价值,同时也让轻薄本和全能本有机会具备更出色的图形与AI性能。这也是相当一颗赛艇的。
最后,单纯就已掌握的信息来看,CPU部分大概率是一次架构改良,或许不会带来飞跃式的性能与能效进步。不过有关CPU,我们更好奇的还是在于Panther Lake 4c版能否延续Lunar Lake的续航佳绩,毕竟它去掉了片上DRAM设计与PMIC电源管理方案:而更先进的制造工艺、微架构改良足够抵










