关键词:RISC-V、GPGPU、SIMT、OpenCL、Vortex、异构计算

Vortex: OpenCL Compatible RISC-V GPGPU https://arxiv.org/pdf/2002.12151 https://vortex.cc.gatech.edu/ https://github.com/vortexgpgpu/vortex 8000 字,阅读 30 分钟,播客 18 分钟
当前技术缩放(这里指芯片制造工艺向更小尺寸演进,如从 28nm 到 15nm 的过程)面临的挑战正推动半导体行业向硬件专用化方向发展,催生了大量异构片上系统(SoC,指将多个功能不同的处理器或模块集成在单颗芯片上的系统)。
与传统通用架构相比,这些异构片上系统在性能和功耗方面能带来数量级的提升。随着 RISC-V 的出现,这一转型得到了显著推动——RISC-V 凭借其独特的模块化、可扩展指令集架构,能够为各类目标应用设计出低成本的处理器。
此外,OpenCL(开放计算语言,一种用于异构计算平台的跨平台编程框架)目前是主流异构平台中应用最广泛的编程框架,支持主流中央处理器(CPU)、通用图形处理器(GPGPU)、现场可编程门阵列(FPGA)以及自定义数字信号处理器(DSP)。
在本研究中,我们提出了 Vortex——一款支持 OpenCL 的 RISC-V 通用图形处理器(GPGPU)。

Vortex 采用单指令多线程(SIMT,指一条指令同时控制多个线程执行,适用于数据并行任务)架构,并通过对 RISC-V 进行最小化指令集扩展,实现了 OpenCL 程序的执行。
我们还扩展了 OpenCL 运行时框架,以适配这一新指令集,并基于 15nm 工艺对该设计进行了评估,并展示了在异构计算性能测试套件 Rodinia 基准测试集的子集上运行时的性能与能耗数据。

本文目录
本文目录 一、引言 二、背景 A. 开源 OpenCL 实现 三、OpenCL 软件栈 A. Vortex 原生运行时 B. POCL 运行时 C. 屏障支持 四、Vortex 并行硬件架构 A. SIMT 硬件原语 B. Warp Scheduler(Warp 调度器) C. 线程掩码与 IPDOM 栈 D.Warp 屏障 五、评估 A. 微架构设计空间探索 B. 基准测试集 C. simX 模拟器 D. 性能评估 E. 布局与布线 六、相关工作 七、结论 参考文献
一、引言
数据并行架构与通用图形处理器(GPGPU)的出现,为解决多核处理器的功耗限制与扩展性问题提供了新的可能,同时也为挖掘新兴大数据并行应用(如机器学习、图分析)中丰富的数据并行性开辟了新途径。
其中,GPGPU 采用的单指令多线程(SIMT)执行模型,通过深度利用数据并行多线程技术,以相对较低的能耗实现了吞吐量最大化,在当前能效竞赛(如Green500 榜单[12],衡量超级计算机能效的权威榜单)和应用支持方面处于领先地位——其采用以加速器为核心的并行编程模型(如 CUDA[19]、OpenCL[17])。
开源免费的指令集架构(ISA)RISC-V[2,20,21]的出现,凭借其丰富的开源软件与工具生态,为低成本硬件架构设计提供了更高的自由度。
借助 RISC-V,计算机架构师已设计出多款创新处理器与核心,例如 BOOM v1 和 BOOM v2 乱序执行核心(指处理器可打乱指令执行顺序以提高效率,而非严格按程序顺序执行),以及适用于各类应用的片上系统(SoC)平台。 例如,Gautschi 等人[9]将 RISC-V 扩展至数字信号处理(DSP)领域,用于可扩展物联网(IoT)设备; 此外,基于 RISC-V 的向量处理器[22,15,3]以及集成向量加速器的处理器[16,10]也已完成设计与流片。
尽管上述工作具有诸多优势,但目前针对基于 RISC-V 构建开源通用图形处理器(GPGPU)系统的关注仍显不足。
尽管近期已有部分工作提出基于 RISC-V 在 FPGA 上实现大规模并行计算(如 GRVI Phalanx[11]、Simty[6]),但这些工作均未实现“全栈”支持——即未同时完成 RISC-V 指令集扩展、微架构综合(指将硬件描述语言转化为物理电路网表的过程)以及支持 OpenCL 程序执行的软件栈开发。我们认为,**要实现大规模并行平台的可用性与可定制性,此类全栈实现至关重要。**
本文提出了面向 GPGPU 程序的 RISC-V 指令集扩展及相应微架构,并扩展了软件栈以支持 OpenCL。
本文的主要贡献如下:
提出了一种高度可配置的、基于 SIMT 的通用图形处理器(GPGPU)架构,该架构以 RISC-V 指令集为目标,并基于我们的寄存器传输级(RTL,用于描述硬件电路的抽象层级)设计,采用 Synopsys 库完成了架构综合。 我们证明,在 RV32IM(32 位 RISC-V 整数与乘法扩展指令集)的基础上,_仅需新增 5 条指令即可实现 SIMT 执行。_ 阐述了为使 OpenCL 程序能在 Vortex 上执行,软件栈所需进行的必要修改。 通过在 Rodinia 基准测试集[5]的子集上运行程序,验证了该设计的可移植性。
二、背景
A. 开源 OpenCL 实现
POCL[13](可移植计算语言,一款开源 OpenCL 实现)基于 LLVM 实现了灵活的编译后端,能够支持多种目标设备,包括通用处理器(如 x86、ARM、Mips 架构)、通用图形处理器(如英伟达 GPU)、TCE(可配置计算引擎,一种用于设计专用处理器的工具链)架构处理器[14]以及自定义加速器。
其中,自定义加速器支持为 OpenCL 应用提供了高效解决方案,使其能够利用专用固定功能硬件,如 SPMV 稀疏矩阵向量乘法、GEMM 通用矩阵乘法,均为高性能计算中的常用操作。POCL 由两个主要组件构成:后端编译引擎与前端 OpenCL 运行时 API。
POCL 运行时实现了设备无关的公共接口,各目标设备的具体实现可通过该接口接入 POCL,以实现操作的专用化。在运行时,POCL 会调用后端编译器对输入的 OpenCL 内核源码进行处理。
POCL 支持多种目标设备特有的执行模型,包括单指令多线程(SIMT)、多指令多线程(MIMD,指多个线程同时执行不同指令)、单指令多数据(SIMD,指一条指令同时处理多个数据)以及超长指令字(VLIW,指将多条指令打包成一条长指令,由多个功能单元并行执行)。
在支持 MIMD 和 SIMD 执行模型的平台(如 CPU)上,POCL 编译器会尝试将尽可能多的 OpenCL 工作项(work-item,OpenCL 中并行执行的基本单元)打包到同一条向量指令中;随后,POCL 运行时会将剩余工作项分配到设备上的活跃硬件线程中,并提供同步支持。 在支持 SIMT 执行模型的平台(如 GPU)上,POCL 编译器会将工作项的分配任务交由硬件处理,由硬件将执行任务分配到各个硬件线程,并由硬件负责必要的同步操作。 在支持 VLIW 执行模型的平台(如基于 TCE 的加速器)上,POCL 编译器会尝试“展开”内核代码中的并行区域,以便将多个独立工作项的操作静态调度到目标设备的多个功能单元上。
三、OpenCL 软件栈
A. Vortex 原生运行时
Vortex 软件栈实现了一个原生运行时库,用于开发可在 Vortex 上运行的应用,并利用新的 RISC-V 指令集扩展功能。

图 2 展示了 Vortex 运行时层,它由三个主要组件构成:
暴露新指令集接口的底层内置函数库(Intrinsic Library); 实现 NewLib 桩函数(stub functions,指仅提供接口、需用户实现具体逻辑的函数,用于对接系统调用)的支持库[7]; 用于启动 POCL(Portable Computing Language,开源 OpenCL 实现,支持多种硬件目标)内核的原生运行时 API。
具体来说:
1. 内置函数库(Intrinsic Library)
为使 Vortex 运行时内核能在不修改现有编译器的情况下使用新指令,我们实现了一个内置函数层来封装新指令集。

图 2 展示了该内置函数库支持的函数与指令集。我们利用了 RISC-V 的应用程序二进制接口(ABI,Application Binary Interface)——该接口保证函数参数通过参数寄存器传递,返回值通过 a0 寄存器传递。因此,这些内置函数仅包含两条汇编指令:1)用 32 位十六进制编码表示的指令(使用参数寄存器作为源寄存器);2)返回指令(用于返回到 C++程序)。

图 3 展示了此类内置函数的示例。此外,为处理 OpenCL 内核中频繁出现的控制发散(即同一 warp 内线程因分支条件不同而执行不同路径),我们实现了图 3 所示的if和endif宏,以最少的代码修改实现内置函数的插入。目前,这些修改需为每个 OpenCL 内核手动完成。该方案无需限制平台,也无需修改 RISC-V 编译器,即可实现所需功能。
2. NewLib 桩函数库(NewLib Stubs Library)
Vortex 软件栈使用 NewLib 库[7](一种轻量级 C/C++标准库,常用于嵌入式系统),使程序无需依赖操作系统即可使用 C/C++标准库。NewLib 定义了一组最小化的桩函数,客户端应用需实现这些函数以处理文件 I/O(输入输出)、内存分配、时间、进程等必要的系统调用。
3. Vortex 原生 API(Vortex Native API)
Vortex 原生 API 实现了一组通用工具例程,供应用调用。其中一个关键例程是pocl_spawn(),它支持程序在 Vortex 上调度 POCL 内核执行。
pocl_spawn()负责将 POCL 请求的工作组(work group,OpenCL 中线程的组织单位,包含多个工作项)映射到硬件,具体步骤如下:
通过内置函数层获取可用硬件资源; 根据请求的工作组维度和数量,将任务均匀分配到硬件资源中; 针对每个 OpenCL 维度,在全局结构中为每个可用 warp(线程组,通常包含多个线程,共享程序计数器)分配一个 ID 范围; 通过内置函数层启动 warp 并激活线程; 每个 warp 循环处理分配到的 ID,每次使用新的 OpenCL 全局 ID(global ID,OpenCL 中标识每个工作项的唯一 ID)执行内核。

图 4 展示了一个示例:在原始 OpenCL 代码中,内核通过全局/本地尺寸(global/local size)作为参数调用一次;POCL 会用三层循环(对应 x、y、z 维度)封装内核,并通过逻辑将 x、y、z 坐标转换为全局 ID,依次调用内核。
而在 Vortex 版本中,首先启动 warp 和线程,然后为每个线程分配不同的工作组以执行内核。POCL 提供了映射正确 warp ID(wid)的功能——这是 POCL 基准实现的一部分,用于支持向量架构等多种硬件。
B. POCL 运行时
我们对 POCL 运行时进行了修改,在其通用设备接口中添加了一个新的设备目标以支持 Vortex。这个新设备目标本质上是 POCL 基础 CPU 目标的变体——移除了对 pthreads(POSIX 线程库)和其他操作系统依赖的支持,以适配 NewLib 接口。我们还修改了执行工作项(work item,OpenCL 中最小的执行单元)的单线程逻辑,使其使用 Vortex 的pocl_spawn运行时 API。
C. 屏障支持
OpenCL 中工作组内的同步通过屏障(barrier,一种强制线程等待直到所有线程到达同一执行点的机制)实现。POCL 的后端编译器会围绕屏障拆分内核的控制流图(CFG,Control Flow Graph,描述程序执行路径的图形结构),并将内核拆分为两个部分,由所有本地工作组(local work group)按顺序执行。
四、Vortex 并行硬件架构
A. SIMT 硬件原语
单指令多线程(SIMT)执行模型利用了大多数并行应用的一个特性:相同代码重复执行,但处理不同数据。为此,该模型引入了“warp”的概念[19](一组线程,通常共享程序计数器(PC),遵循相同执行路径,分支发散极少)。
一个 warp 中的每个线程都有私有通用寄存器组(GPR,General Purpose Register),算术逻辑单元(ALU)的宽度与线程数匹配。然而,指令的取指(fetch)、译码(decode)和发射(issue)在同一 warp 内是共享的,这有助于减少执行周期。
但在某些情况下,同一 warp 内的线程对分支方向(如 if-else 语句的判断结果)可能存在分歧。此时,硬件必须提供线程掩码(thread mask,用于标记每个线程是否活跃的位向量)来对每个线程的指令进行谓词控制(predicate control,即仅活跃线程执行指令),并通过 IPDOM 栈(用于管理分支发散时的执行路径,确保所有线程正确执行)——这些机制将在 C 节中详细说明。
B. Warp Scheduler(Warp 调度器)

Warp 调度器位于取指阶段(fetch stage,CPU 流水线中获取指令的阶段),负责决定从指令缓存(I-cache)中取哪些指令,如图 5 所示。它包含两个组件:
一组 warp 掩码:用于选择下一个要调度的 warp; 一个 warp 表:存储每个 warp 的私有信息。
调度器使用 4 种线程掩码:
活跃 warp 掩码(active warps mask)——每一位表示对应 warp 是否活跃; 停滞 warp 掩码(stalled warp mask)——表示哪些 warp 需暂时停止调度(例如,等待内存请求完成); 屏障停滞 warp 掩码(barrier warps stalled mask)——表示因屏障指令而停滞的 warp; 可见 warp 掩码(visible warps mask)——用于支持分层调度策略[18]。
每个周期,调度器从可见 warp 掩码中选择一个 warp,并将该 warp 在掩码中标记为无效。当可见 warp 掩码为 0 时,通过检查当前活跃且未停滞的 warp,重新填充活跃掩码。



wspawn指令(见下面表 I)时,该指令会激活新的 warp,并通过将 warp 2 和 warp 3 设为活跃来修改活跃 warp 掩码。当可见掩码需要重新填充(且无其他可调度 warp)时,warp 2 和 warp 3 会被加入可见掩码。这些 warp 将一直处于活跃掩码中,直到其线程掩码被设为 0,或 warp 0 通过wspawn指令将其设为非活跃
C. 线程掩码与 IPDOM 栈
为支持 A 节所述的线程机制,硬件中添加了线程掩码寄存器和 IPDOM 栈,这与其他 SIMT 架构[8]类似。
线程掩码寄存器的作用类似每个线程的谓词:若某线程在掩码中的对应位为 0,则该线程的寄存器组不会被修改,且其操作不会对缓存产生影响。

IPDOM 栈(如图 5 所示)用于处理控制发散,由split和join指令控制——这些指令通过 IPDOM 栈实现发散功能,如图 3 所示。

当一个 warp 执行split指令时,会评估每个线程的谓词值(分支条件结果):
若仅一个线程活跃,或所有线程的分支方向一致,则 split指令相当于空操作(nop),不改变 warp 状态;若存在多个活跃线程且谓词值不一致(即分支发散),则会触发三个微架构事件:
将当前线程掩码作为“直通”(fall-through,指不满足分支条件的执行路径)条目压入 IPDOM 栈; 将谓词值为 false 的活跃线程对应的条目(包含 split指令的 PC+4,即下一条指令地址)压入栈;更新当前线程掩码,仅保留谓词值为 true 的活跃线程。
当执行join指令时,会从 IPDOM 栈中弹出一个条目,触发两种场景之一:
若弹出的条目不是“直通”条目,则将程序计数器(PC)设为该条目的 PC 值,并将线程掩码更新为该条目的掩码值——这使得谓词值为 false 的线程能执行其对应的路径; 若弹出的条目是“直通”条目,则 PC 继续执行下一条指令(PC+4),并将线程掩码更新为该条目的掩码值——这对应分支的两条路径均已执行完毕的场景。
D.Warp 屏障
Warp 屏障在 SIMT 执行中至关重要,它提供了 warp 间的同步机制。硬件中实现了屏障功能,以支持工作组间的全局同步。

每个屏障在屏障表(如图 5 所示)中都有一个私有条目,包含以下信息:
该屏障是否当前有效; 仍需执行该屏障指令(且使用对应屏障 ID)的 warp 数量(达到该数量后屏障释放); 因该屏障而停滞的 warp 掩码。
需注意的是,图 5 仅展示了单核屏障表;在多核配置中,还存在另一个全局屏障表,支持所有核心间的全局同步。屏障 ID 的最高位(MSB)用于标识该指令使用的是本地屏障(单核内)还是全局屏障(多核间)。
当执行屏障指令时,微架构会检查使用同一屏障 ID 的已执行 warp 数量:
若已执行 warp 数量未达到指定值,则当前 warp 停滞,且释放掩码(release mask)中会加入该 warp; 当已执行 warp 数量达到指定值时,将使用释放掩码释放所有因该屏障 ID 停滞的 warp。
该机制同时适用于本地屏障和全局屏障;不同之处在于,全局屏障表为每个核心维护一个独立的释放掩码。
五、评估
本节将对 Vortex 的 RTL(寄存器传输级,硬件设计的一种抽象层级,描述寄存器与组合逻辑间的数据传输)Verilog 模型和软件栈进行评估。
A. 微架构设计空间探索
在 Vortex 设计中,可通过两种方式提升数据级并行性(DPL,即同时处理多个数据的能力):增加线程数,或增加 warp 数。
增加线程数类似于提升 SIMD(单指令多数据,与 SIMT 不同,SIMD 是单个指令同时处理多个数据元素)宽度,需对硬件进行以下修改:
增加通用寄存器(GPR)的读写宽度; 增加算术逻辑单元(ALU)数量,使其与线程数匹配; 增加 GPR 读取阶段之后所有流水线阶段的寄存器宽度; 增强缓存和共享内存中的仲裁逻辑(用于检测存储体冲突(bank conflict,即多线程同时访问同一存储体导致的延迟)和处理缓存缺失); 增加 IPDOM 栈的条目数。
相比之下,增加 warp 数无需增加 ALU 数量——因为 ALU 会被更多 warp 时分复用(即不同 warp 轮流使用 ALU)。增加 warp 数需对硬件进行以下修改:1)增强 warp 调度器的逻辑;2)增加通用寄存器(GPR)表的数量;3)增加 IPDOM 栈的数量;4)增加寄存器计分板(register scoreboard,用于跟踪寄存器的使用状态,避免数据冲突)的数量;5)扩大 warp 表的大小。
需注意的是,增加 warp 数的成本取决于每个 warp 中的线程数——因此,对于线程数较多的配置,增加 warp 数的成本会更高。这是因为每个 GPR 表、IPDOM 栈和 warp 表的大小均与线程数相关。
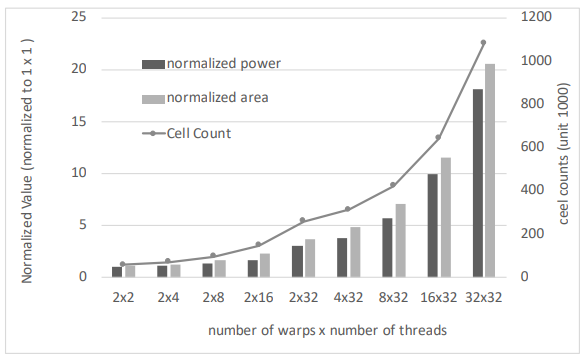
图 8 展示了线程数和 warp 数增加时,面积与功耗的变化趋势(所有数值均以支持 1 个 warp 和 1 个线程的配置为基准进行归一化)。
所有数据均包含以下模块:1KB 2 路组相联指令缓存(I-cache)、4KB 2 路组相联 4 存储体数据缓存(D-cache)、8KB 4 存储体共享内存。
B. 基准测试集
所有用于评估的基准测试程序均来自 Rodinia[5]——一个常用的 GPGPU 基准测试套件。
C. simX 模拟器
由于 Rodinia 基准测试套件中的程序数据集较大,使用 Modelsim(一种常用的硬件仿真工具)仿真会耗费大量时间,因此我们采用了 simX——一款用于 Vortex 的 C++周期级(cycle-level,即按 CPU 时钟周期精度模拟)自研模拟器。该模拟器的周期精度与实际 Verilog 模型的误差在 6%以内。需注意的是,功耗与面积数据均来自 RTL 合成结果。
D. 性能评估

图 9 展示了各基准测试程序的归一化执行时间(以 2 个 warp×2 个线程的配置为基准)。正如预期,多数情况下,增加线程数(即提升 SIMD 宽度)会带来性能提升,但增加 warp 数的性能提升效果不明显。
部分基准测试程序(如 bfs,广度优先搜索,一种图算法)能从增加 warp 数中获益,但多数情况下,warp 数的增加无法转化为性能提升。主要原因是:为缩短仿真时间,我们对缓存进行了预热(cache warm-up,即提前加载部分数据到缓存,模拟实际运行中的缓存状态),并减小了数据集大小——这使得评估中基准测试程序的缓存命中率较高。
增加 warp 数的主要作用是通过提升线程级并行性(TLP)和内存级并行性(MLP)来隐藏长延迟操作(如缓存缺失);因此,从高 warp 数中获益最多的基准测试程序是 bfs(一种不规则程序,缓存缺失率相对较高)。

随着线程数和 warp 数的增加,功耗会上升,但性能未必同比提升。因此,最优能效(性能/功耗)的设计点因基准测试程序而异。图 10 展示了能效指标(类似性能每瓦)——以 2 个 warp×2 个线程的配置为基准进行归一化。结果表明:
对于多数基准测试程序,能效最优的设计是 warp 数较少且线程数为 32 的配置; bfs 基准测试程序除外——正如前文所述,bfs 在 32 个 warp×32 个线程的配置下性能最优,因此该配置也是其能效最优的设计点。
E. 布局与布线
我们基于 15nm 教学用工艺库对 RTL 进行了综合,并使用 Innovus(一种常用的芯片物理设计工具)完成了布局与布线(PnR,Place and Route,芯片物理设计的关键步骤,将逻辑单元映射到芯片物理位置并连接导线)。

图 7 展示了 Vortex 处理器的 GDS 布局和功耗密度图。从功耗密度图可观察到:
功耗在单元区域内分布均匀; 寄存器(GPR)、数据缓存、指令缓存(I-cache)和共享内存等存储模块的功耗相对较高。
六、相关工作
七、结论
在本文中,我们提出了 Vortex——一款支持 RISC-V 扩展指令集的通用图形处理器(GPGPU),可用于运行 GPGPU 应用。我们还修改了 OpenCL 软件栈,使其能够运行各类 OpenCL 内核,并通过实验验证了这一设计的有效性。
我们计划将 Vortex 的寄存器传输级设计代码以及 POCL 的修改部分公开。[2]
我们相信,这款开源的 RISC-V 通用图形处理器(GPGPU)将丰富 RISC-V 生态系统,并为其他研究人员在更广泛的领域如 GPGPU 性能优化、功耗控制、架构创新等,开展 GPGPU 相关研究提供助力——因为整个软件栈同样基于开源实现,便于研究人员修改和扩展。
文章来源于NeuralTalk
参考文献

欢迎加入 EETOP 微信群











