7 篇本周关注到的学术进展(要点版)
【密歇根大学联合佐治亚理工学院】提出一种将模型预测控制(MPC)与基于随机傅里叶特征(RFF)的在线学习残差动力学相结合的框架。
【美国犹他大学】提出Round-Robin Behavior Cloning (R2BC) 方法,允许人类操作员轮流遥控每个机器人,生成单智能体示范。
【华盛顿大学】等提出VAMOS,一种分层的视觉-语言-动作模型(VLA),将语义规划与形态适配解耦。
【清华大学、北京大学等】提出MV-RoboBench,一个专门用于评估VLMs在机器人操作中多视角空间推理能力的基准。
【香港大学联合上海人工智能实验室】提出一种端到端的强化学习(RL)框架,直接从感知输入到全身控制策略进行学习,无需依赖远程操作或固定动作回放。
【意大利热那亚意大利技术学院】提出一种基于四足机器人本体感知信号的多层2.5D网格地图框架,将这些与机器人-地形交互相关的物理量增量式融合到统一的地图表示中。
【湖南大学等】提出一种改进的协同引导矢量场(CGVF)算法,试图解决多机器人在n维欧氏空间中沿m维流形运动时的协同导航问题。
(如果有不全面的地方,欢迎大家补充,以期共同进步。PS:没时间看详细介绍的朋友,【要点速览】可供快速浏览。)
1

1
本文提出了一种通过在线学习与模型预测控制实现自适应足式运动的算法。该算法由两个相互作用的模块组成:模型预测控制(MPC)和残差动力学的在线学习。
本文的研究动机来自于自主系统的未来应用场景,即四足机器人需在存在真实世界未知不确定性(如负载未知、地形不平整等)的情况下,自主完成复杂任务。该算法采用随机傅里叶特征,在再生核希尔伯特空间中对残差动力学进行近似,并基于当前学习到的残差动力学模型实施模型预测控制。
该模型在控制四足机器人过程中持续收集数据,并以自监督方式基于最小二乘法在线更新。该算法具有次线性的动态遗憾(dynamic regret)性能,即其性能相对于已知残差动力学全貌的最优先知控制器而言的次优程度随时间增长较慢。
本文在Gazebo和MuJoCo仿真环境中对该算法进行了验证,仿真任务为四足机器人跟踪参考轨迹。Gazebo仿真中包含了在平坦地形、20度斜坡地形以及高度变化达0.25米的崎岖地形上施加的恒定未知外力,最大可达12倍重力矢量g(其中g为重力矢量)。
MuJoCo仿真则涵盖了在平坦地形上存在时变未知扰动的情形,包括最大8公斤的额外负载以及时变的地面摩擦系数。

文章链接:https://arxiv.org/html/2510.15626v1
2

2
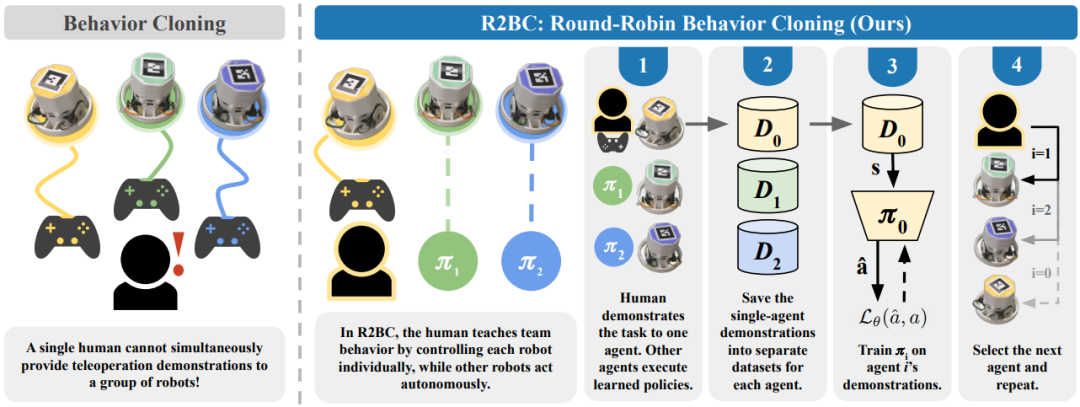
虽然模仿学习已广泛应用于单机器人场景,但将其方法扩展到多智能体系统的研究相对较少,特别是在仅由一名人类为协作机器人团队提供示范的场景中。
本文提出并研究了一种名为“轮转式行为克隆”(Round-Robin Behavior Cloning, R2BC)的方法,该方法使单个人类操作者能够通过顺序进行的单智能体示范,有效训练多机器人系统。
本文的方法允许人类一次遥操作一个智能体,并逐步将多智能体协作行为教授给整个系统,而无需在联合的多智能体动作空间中提供示范。本文证明,在四个多智能体模拟任务中,R2BC方法的表现可与基于特权同步示范训练的“理想”行为克隆方法相媲美,甚至在某些情况下更优。
最后,本文将R2BC应用于两个真实物理机器人任务,并使用实际的人类示范完成了训练。
文章链接:https://arxiv.org/html/2510.18085v1
3

3
机器人导航中的一个根本性挑战在于,如何学习能够在不同环境中泛化、同时又能适应特定机器人本体独特物理约束与能力的策略(例如,四足机器人可以上楼梯,而轮式机器人则不能)。
本文提出了VAMOS,一种分层的视觉-语言-动作模型(VLA),将语义规划与本体具身化实现解耦:通用型规划器从多样化、开放世界的数据中学习,而专用型可供性模型则在安全且低成本的仿真环境中学习机器人的物理限制与能力。
本文通过精心设计一个接口实现了这种分离:高层规划器直接在图像空间中提出候选路径,再由可供性模型对其进行评估和重新排序。本文在真实环境中的实验表明,VAMOS在室内和复杂室外导航任务中的成功率均超过了当前最先进的基于模型和端到端学习的方法。
本文还证明,这种分层设计能够支持在轮式和腿式机器人之间进行跨本体的导航,并可通过自然语言轻松引导。真实环境中的消融实验进一步证实,专用模型对于实现本体具身化至关重要,使得同一个高层规划器可以部署于物理结构截然不同的轮式和腿式机器人上。最后,该模型显著提升了单个机器人的可靠性,通过拒绝物理上不可行的计划,使其成功率提高了3倍。

文章链接:https://arxiv.org/html/2510.20818v1
4

4
视觉-语言模型(VLM)对具身人工智能(Embodied AI)至关重要,使机器人能够在复杂环境中实现感知、推理与行动,并构成了近期视觉-语言-动作(VLA)模型的基础。然而,当前对VLM的大多数评估集中于单视角场景,导致其整合多视角信息的能力尚未得到充分探索。
与此同时,多摄像头配置在机器人平台上正变得越来越普遍,因为它们能提供互补的视角,有助于缓解遮挡和深度模糊问题。因此,VLM能否有效利用此类多视角输入来支持机器人推理,仍是一个悬而未决的问题。
为填补这一空白,本文推出了MV-RoboBench——一个专门用于评估VLM在机器人操作任务中多视角空间推理能力的基准测试。
MV-RoboBench包含1700个经过人工精心筛选的问答项目,涵盖八个子任务,分为两大类别:空间理解与机器人执行。
本文对一系列现有的VLM进行了评估,包括开源和闭源模型,并测试了结合了受思维链(CoT)启发技术的增强版本。结果表明,当前最先进的模型表现仍远低于人类水平,凸显出VLM在多视角机器人感知方面面临巨大挑战。此外,本文的分析揭示了两个关键发现:
(i)在多视角机器人场景中,空间智能与机器人任务执行能力呈正相关;
(ii)在现有通用单视角空间理解基准上表现优异,并不能可靠地转化为在本基准所评估的机器人空间任务中的成功表现。

文章链接:https://arxiv.org/html/2510.19400v1
5

5
本文提出了一种在真实场景中实现人形机器人自主守门的强化学习框架。尽管先前的研究已在四足机器人平台上展示了类似能力,但人形机器人守门面临两个关键挑战:
(1)生成自然、类人的全身运动;
(2)在响应时间相当的情况下覆盖更大的防守范围。
与现有依赖于独立遥操作或固定动作追踪的全身控制方法不同,本文的方法学习单一的端到端强化学习策略,从而实现完全自主、高度动态且类人的机器人与物体交互。
为实现这一目标,本文通过对抗性机制,在强化学习训练过程中融合了多种基于感知输入的人类运动先验知识。本文通过真实世界实验验证了该方法的有效性,人形机器人成功完成了对高速飞行球体的敏捷、自主且自然的拦截动作。除了守门任务外,本文还通过球体躲避和抓取等任务展示了该方法的良好泛化能力。
本研究为实现机器人与运动物体之间的高度动态交互提供了一种实用且可扩展的解决方案,推动该领域向更灵活、更逼真的机器人行为迈进。

文章链接:https://humanoid-goalkeeper.github.io/Goalkeeper/
6

6
月球两极附近的永久阴影区(PSRs)因其可能含有水冰并保存地质记录而成为未来探测的重要目标。这些区域地形复杂且崎岖不平,适合使用足式机器人进行探索,此类机器人能够穿越复杂地表并原位采集数据。以往在地球类似环境(包括黑暗洞穴)中的实践表明,配备机载照明的足式机器人已展现出良好的有效性。尽管摄像头和激光雷达等外部传感器能够获取地形的几何结构甚至语义信息,却无法量化地形与机器人之间的物理交互特性,而这一能力正是本体感知传感所具备的。本文提出一种面向四足机器人的地形建图框架,该框架利用运动过程中的本体感知数据,估计地形高程、足端打滑情况、能耗代价以及稳定性裕度。这些指标被逐步融合到一个多层2.5D栅格地图中,从而从机器人的视角反映其与地形的交互状态。该系统在模拟月球环境的仿真器中进行了验证,实验采用重21公斤的四足机器人Aliengo,在月球重力和地形条件下表现出稳定可靠的建图性能。
文章链接:https://arxiv.org/html/2510.18986v1
7

7
本文研究了多机器人在n维欧氏空间中沿期望的m维(即m-D)流形运动时的导航问题,同时保持一种灵活的空间排序。
本文考虑的情形为m ≥ 2,并通过非欧几里得度量实现多机器人协调。然而,由于该m维流形可由n个隐函数的零水平集刻画,若辅助向量选择不当,则广义向量场(GVF)传播项的最后m个分量将与这些隐函数的偏导数产生强烈的耦合。这种耦合不仅影响机器人在流形上的运动行为,也为进一步基于非欧几里得度量设计具备排序灵活性的协调机制带来了显著挑战。
为解决这一问题,本文首先构造出一组可行的辅助向量,使得传播项的最后m个分量被有效解耦并恒等于同一常数。接着,本文重新设计了协调式广义向量场(CGVF)算法,通过将m个流形参数视为额外的m个虚拟坐标,从而增强其消除奇点和实现全局收敛的优势。此外,本文通过允许每个机器人与其时变邻居及一个虚拟目标机器人共享这m个虚拟坐标,实现了流形上的排序灵活运动协调,从而规避了若采用欧几里得度量可能带来的复杂计算。
最后,本文通过大量仿真展示了所提出算法在不同初始位置、高维流形以及机器人故障等情况下的灵活性、适应性和鲁棒性。
文章链接:https://arxiv.org/html/2510.18063v1
>>>现在成为星友,特享99元/年<<<


【具身宝典】||||
【技术深度】|||||||
【先锋观点】|||
【非开源代码复现】||
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

【深蓝具身智能】的内容均由作者团队倾注个人心血制作而成,希望各位遵守原创规则珍惜作者们的劳动成果。
投稿|商务合作|转载:SL13126828869(微信)

点击❤收藏并推荐本文