点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!
0. 论文信息
论文标题:Advances in Feed-Forward 3D Reconstruction and View Synthesis: A Survey
论文链接:https://arxiv.org/abs/2507.14501
论文主页:https://fnzhan.com/projects/Feed-Forward-3D/

在3D视觉领域,如何从二维图像快速、精准地恢复三维世界,一直是计算机视觉与计算机图形学最核心的问题之一。从早期的 Structure-from-Motion (SfM) 到 Neural Radiance Fields (NeRF),再到 3D Gaussian Splatting (3DGS),技术的演进让我们离实时、通用的 3D 理解越来越近。然而,以往的方法往往依赖于每个场景的反复优化(per-scene optimization),既慢又缺乏泛化能力。在 AI 驱动的新时代,一个全新的范式正在崛起 —— Feed-Forward 3D。

这篇由 NTU、Caltech、Westlake、UCSD、Oxford、Harvard、MIT 等 12 所机构联合撰写的综述论文《Advances in Feed-Forward 3D Reconstruction and View Synthesis》,主要总结了过去五年(2021–2025)间涌现的数百项创新工作,首次建立了完整的 Feed-Forward 3D 方法谱系与时间线。

五大代表性技术分支
综述将所有Feed-Forward 3D方法划分为五类主流架构,每一类都推动了该领域的关键进展:
1. NeRF-based Models:
Neural Radiance Fields (NeRF) 提出了体积渲染的可微分框架,但其“每个场景都要优化”的缺点导致效率低下。自 PixelNeRF [CVPR'21] 起,研究者们开始探索“条件式 NeRF”,让网络直接预测辐射场。这一方向发展出多个分支:
1D 特征方法(如 CodeNeRF、ShaRF) 2D 特征方法(如 GRF、IBRNet、GNT、MatchNeRF) 3D 特征方法(如 MVSNeRF、GeoNeRF、NeuRay)

2. PointMap Models:
这一分支由 DUSt3R (CVPR'24) 引领,直接在 Transformer 中预测像素对齐的 3D 点云(pointmap),无需相机姿态输入。后续工作 MASt3R、Fast3R、CUT3R、SLAM3R、VGGT 等相继提出更高效的多视整合,长序列记忆机制,以及大场景处理能力等。

3. 3D Gaussian Splatting (3DGS):
3DGS 是近年来最具突破性的表示之一,将三维场景表示为高斯点云,兼顾了体积渲染的质量与光栅化的速度。然而原始 3DGS 仍需优化。Feed-Forward 研究者通过引入神经预测器,实现了“直接输出高斯参数”的能力,主要方法包括:
Image-based Gaussian Map:如 PixelSplat、GS-LRM、LGM、FreeSplatter,实现从单张图像到高斯场的预测; Volume-based Gaussian Representation:如 LaRa、GaussianCube、QuickSplat、SCube,将场景嵌入可学习体素或三平面结构中。
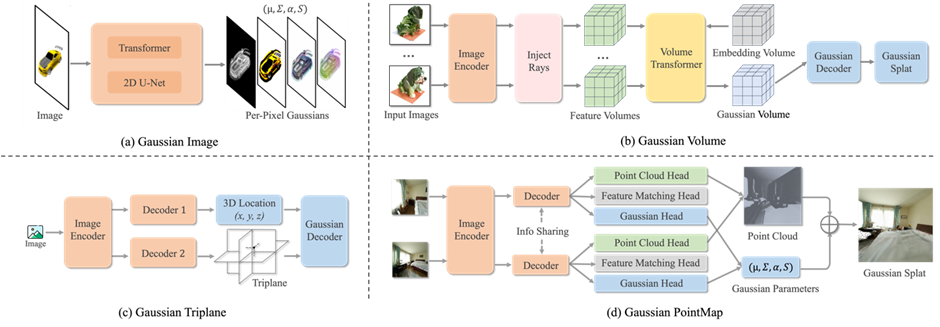
4. Mesh / Occupancy / SDF Models:
这一类方法延续了传统几何建模思路,并与 Transformer 与 Diffusion 模型结合:
MeshFormer、InstantMesh、MeshGPT、MeshXL 引入可自回归或大模型结构; SDF 方法(如 SparseNeuS、C2F2NeuS、UFORecon)结合体积感知与 Transformer 特征聚合,实现了高精度表面建模。
5. 3D-Free Models:
这类方法不再依赖显式三维表示,而是直接学习从多视图到新视角的映射。
Regression-based:如 SRT、OSRT、RePAST、LVSM,利用深度神经网络直接端到端拟合目标结果; Generative Diffusion-based:以 Zero-1-to-3、SyncDreamer、MVDream、CAT3D、CAT4D 为代表,将图像或视频扩散模型迁移到三维生成领域。 这些模型让“一张图生成整个场景”成为可能。
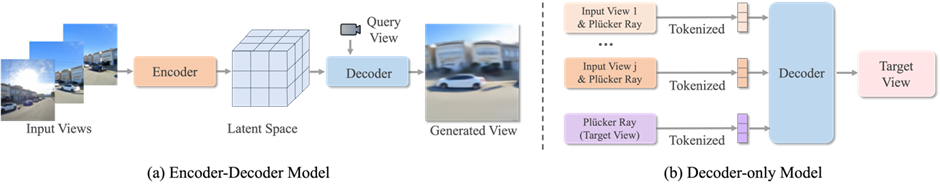

多样化任务与应用场景
论文系统总结了 Feed-Forward 模型在多个方向的应用:
Pose-Free Reconstruction & View Synthesis(PF3Plat、NoPoSplat) Dynamic 4D Reconstruction & Video Diffusion(MonST3R、4D-LRM、Aether) SLAM 与视觉定位(SLAM3R、VGGT-SLAM、Reloc3R) 3D-Aware 图像与视频生成(DiffSplat、Bolt3D) 数字人建模(Avat3R、GaussianHeads、GIGA) 机器人操作与世界模型(ManiGaussian、ManiGaussian++)
Benchmark 与评测指标
论文收录了超过 30 个常用 3D 数据集(见第13页表1),涵盖对象级、室内、室外、静态与动态场景,标注模态包括 RGB、深度、LiDAR、语义与光流等。
同时总结了 PSNR / SSIM / LPIPS(图像质量),Chamfer Distance(几何精度),AUC / RTE / RRA(相机姿态)等标准指标体系,为未来的模型比较提供统一基线。

评测结果: Feed-Forward 3D 的量化进展
根据Table 2–5的结果,本综述对多项任务进行了系统对比:
相机姿态估计(Camera Pose Estimation) 点图重建(Point Map Estimation) 视频深度估计(Video Depth Estimation) 单图新视角合成(Single-Image NVS)
未来挑战与趋势
论文在第5章提出四大开放问题:
多模态数据不足:RGB-only 仍占主流,缺乏统一的深度/LiDAR/语义对齐数据; 重建精度待提升:尚未全面超越 MVS 在细节层面的表现; 自由视角渲染难度高:遮挡与光照建模仍受限; 长上下文推理瓶颈:处理 100+ 帧序列需 40 GB 以上显存。
未来方向包括:
Diffusion Transformers 与 长程注意力结构; 可扩展的 4D 记忆机制; 多模态大规模数据集构建(RGB + Depth + LiDAR + 语义); 同时具有生成和重建能力的Feed-Forward模型。
3D视觉1V1论文辅导来啦!

3D视觉学习圈子
星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001