点击下方卡片,关注“大模型之心Tech”公众号
今天大模型之心Tech为大家分享港科大被ICCV 2025接收的大模型相关论文,本文聚焦于多模态大语言模型(MLLMs)的可解释性问题,提出了 Token Activation Map(TAM)方法,通过估计因果推理和秩高斯滤波来提升解释质量,在多个数据集和模型上验证了有效性和广泛适用性。如果您有相关工作需要分享,请在文末联系我们!
论文标题:Token Activation Map to Visually Explain Multimodal LLMs
论文作者:Yi Li等
作者单位:港科大计算机系
论文链接:https://arxiv.org/pdf/2506.23270
开源链接:https://github.com/xmed-lab/TAM
多模态大语言模型解释性的破局之路——文章动机与贡献
研究动机
MLLMs的发展与解释性缺口
多模态大语言模型(MLLMs)已广泛应用于多模态输入(如图像、视频、文本)和类人对话,但相比传统视觉模型(如CNN、ViT、CLIP),其可解释性研究严重不足。解释性对用户信任、模型理解、案例分析和可视化至关重要,但MLLMs的渐进式多token生成特性(而非单输出)使其解释难度更高。现有方法的局限性

图1. 研究动机示意图。(a) 多模态大语言模型(MLLMs)生成多个Token,而非单一输出。(b) 信息流表明MLLM按顺序生成Token,其中每个生成的Token(每行)与上下文(提示词+早期答案Token)相关。(c) 我们随机配对类激活图(CAMs)并计算其与文本相关性的L1距离。文本相关性越高,距离越小,表明存在并发干扰。(d) 该示例显示上下文Token“盘子”对后续待解释Token“叉子”引入了干扰激活(白色方框标注)。(e) 我们的TAM方法揭示了待解释Token“叉子”的原始信息,消除了上下文干扰,效果优于(d)中针对单一输出的CAM方法。(c, d, e)中的结果源自Qwen2-VL-2B模型在COCO Caption数据集上的实验。
传统解释方法(如Class Activation Map(CAM)系列、注意力机制)被直接应用于MLLMs,但忽略了一个关键问题:早期上下文token(提示词+已生成的答案token)会对后续待解释token引入冗余激活干扰。例如,在解释“叉子”token时,上下文“盘子”token会导致激活图中出现无关区域(如图1d),定量分析表明这种干扰普遍存在(文本相关性越高,激活图差异越小,如图1c),严重影响解释可靠性。
MLLMs特有的挑战
MLLMs的token生成具有时序依赖性,每个token的激活与之前所有上下文相关,而传统方法未考虑这种token间的交互干扰,导致解释结果混淆原始信息与上下文噪声。
核心贡献
提出Token Activation Map(TAM)方法
估计因果推理模块:通过量化上下文token的干扰并优化比例因子,消除冗余激活,揭示当前token与输入的因果关系(而非统计相关性)。 秩高斯滤波(Rank Gaussian Filter):针对transformer激活图中的椒盐噪声,设计新的滤波方法,结合排序值与高斯核权重,提升可视化清晰度。
性能超越现有方法
在COCO Caption、OpenPSG等数据集上,TAM相比SOTA方法,F1-IoU指标提升超8.96%,且对Qwen2-VL、InternVL2、LLaVA等7种MLLMs均有效,同时与现有方法互补(最大增益达44.42%)。
广泛的应用场景
TAM支持对象定位、属性分析(颜色、形状、动作等)、失败案例诊断、视频可视化、MLLM比较,以及多轮对话、多图像推理等复杂场景,为MLLM解释提供了通用工具。
关键创新点
首次关注MLLMs的token间干扰问题,并通过因果推理机制解决,不同于传统单输出模型的解释逻辑。 结合因果推理与滤波技术,同时处理语义干扰和噪声,提升解释质量。 实验验证覆盖多模型、多数据集,证明方法的普适性和可扩展性。

Token Activation Map技术细节——因果推理与滤波降噪的协同设计
方法总览

图2. 方法示意图。(a, 公式1-公式3) TAM的整体框架。(b, 公式4-公式5) 估计因果推理模块的细节。(c, 公式6-公式7) 秩高斯滤波模块的细节。(d, 公式8-公式10) 细粒度评估指标。
作者以MLLM的多模态特征流为起点,构建了"特征提取-因果推理-噪声过滤-多模态融合"的四级处理链(如图2a)。具体而言,输入视觉数据与文本提示经MLLM处理后生成三类特征:视觉特征 、提示特征 和答案特征 ,通过token分类器(全连接层)生成激活图。但原始激活图存在双重缺陷:上下文干扰与椒盐噪声,而TAM通过两大核心模块针对性解决,最终输出融合视觉与文本相关性的多模态激活图 。
估计因果推理:剥离上下文干扰的数学建模
1. 激活图的基础计算与干扰建模
传统方法直接使用 计算答案token的激活图(式1),但未考虑上下文影响。作者指出,第 个答案token的上下文包括所有提示token与前 个答案token,其激活图拼接为 。干扰的本质是这些上下文激活图的线性组合,其权重由文本相关性 决定——该相关性通过特征 与 对当前token的激活计算,若上下文token与当前token相同则置零(式4):
这一设计确保了干扰图仅包含“语义相关但非当前目标”的激活,避免自抑制问题。
2. 最优比例因子的因果推断
为求解“应减去多少干扰”,作者引入最小二乘法优化比例因子 。其核心假设是:因果激活图应使原始激活与干扰图的残差最小(式5):
该公式本质上是寻找一个线性变换,使得扣除干扰后的激活图既能保留当前token的语义信息,又能最大程度消除上下文冗余。实验表明,该步骤使Func-IoU提升17.1%(表1),证明对功能词的背景抑制效果显著。
秩高斯滤波:超越传统方法的噪声抑制方案
1. 噪声特性分析与滤波逻辑重构
Transformer激活图的噪声属于“椒盐型”,传统高斯滤波会保留噪声信号,中值滤波则忽略小响应。作者提出的秩高斯滤波(RGF)创新性地将空间滤波与排序操作结合:在大小为 的滑动窗口内,对激活值排序并赋予高斯权重(式6):
其中,排序后的中位数秩 作为高斯核中心,确保中值点权重最大,同时融合邻近秩的信号,形成“平滑的中值滤波”效果。
2. 自适应高斯核的动态调整
为应对不同区域的噪声强度差异,作者用变异系数 替代传统高斯核的固定标准差(式7):
这一改进使核宽度随局部激活的离散程度动态调整:在噪声密集区(如纹理复杂背景)核更宽,平滑效果更强;在目标区域核更窄,保留细节特征。对比实验显示,RGF较自适应中值滤波提升Obj-IoU 1.89%(表2),证明对小目标激活的保留能力更优。
多模态激活图的融合与评估
1. 视觉-文本关联的统一表征
为实现跨模态解释,TAM将精炼后的视觉激活图 与文本相关性 拼接后归一化(式3):
该操作使视觉热点与文本关键词的激活程度可直接比较,例如在“红色叉子”案例中,视觉激活图的红色区域与文本“红色”的高相关性会同步高亮,辅助理解模型的跨模态关联逻辑。
2. 细粒度评估指标的设计
针对MLLM多token输出特性,作者提出三组IoU指标:
Obj-IoU:针对对象词,计算二值化激活图与手动掩码的重叠率(式8),解决传统方法“类固定”的局限; Func-IoU:针对功能词(如“is”“the”),以名词token的平均阈值划分背景,计算与全背景掩码的IoU(式9),衡量对无关区域的抑制能力; F1-IoU:融合前两者的F1分数(式10),避免单指标偏差(如某方法全预测背景时Func-IoU虚高但Obj-IoU极低)。
实验验证与多场景应用
实验设计与数据集配置
核心数据集
COCO Caption:包含5K图像及手动标注掩码,用于定量评估对象定位与功能词抑制能力。 OpenPSG:3176图像的开放集全景场景图,验证模型在复杂场景的泛化性。 GranDf:1K图像的细粒度属性数据集,测试颜色、形状等属性解释能力。 QK-VQA:5046样本的视觉问答集,分析失败案例中的知识对齐问题。 STAR:914视频的场景推理数据集,验证视频时序解释能力。
模型配置
覆盖三大系列7种MLLMs:
Qwen2-VL:2B/7B版本,支持原始图像分辨率。 LLaVA1.5:7B/13B版本,固定图像尺寸336。 InternVL2.5:2B/4B/8B版本,图像尺寸448。
定量结果:TAM的性能优势
消融实验:模块有效性验证
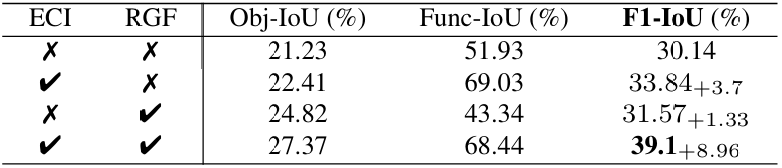
表1. 使用Qwen2-VL-2B在COCO Caption数据集上的消融研究。这两个模块相互受益,其组合效果超过了它们各自增益的总和。ECI表示所提出的估计因果推理,RGF是秩高斯滤波器。指标分别为对象词的IoU、功能词的IoU以及它们类似F1分数的组合。

表2. 使用Qwen2-VL-2B在COCO Caption数据集上的有效性研究。ECI-mean和ECI-attnWeights是补充材料D中描述的ECI候选实现。
估计因果推理(ECI):单独使用使Func-IoU提升17.1%(从51.93%→69.03%),显著减少上下文干扰。 秩高斯滤波(RGF):单独使用使Obj-IoU提升3.59%(从21.23%→24.82%),降低激活噪声。 联合使用:F1-IoU提升8.96%(从30.14%→39.1%),效果超越模块叠加(表1)。
与SOTA方法对比

表3. 在不同数据集上使用Qwen2-VL-2B与最先进(SoTA)方法的对比。我们采用“Logit”类型,该类型使用公式1中的分类器权重,在“Gradient”和“Combination”(Gradient + Attention)中不进行反向传播。此外,我们支持不返回注意力权重的FlashAttention[18]和SdpaAttention,而“Attention”和“Combination”则依赖于注意力权重。我们的TAM方法也与现有方法互补,增益用“+”Token。注意,如补充材料D中所讨论的,CAM和Grad-CAM是等价的。主要指标是F1-IoU(%),它通过对象词的IoU(Obj-IoU)和功能词的IoU(Func-IoU)合并来反映整体结果。
COCO Caption:TAM的F1-IoU达39.1%,较Grad-CAM++(33.71%)提升5.39%,较Attention-Rollout(25.19%)提升13.91%。 OpenPSG:F1-IoU提升8.54%,Obj-IoU提升3.47%,证明对开放集对象的定位优势。 互补性:与CAM结合时,F1-IoU最大增益达44.42%,说明TAM可作为现有方法的通用增强模块(表3)。
跨模型 scalability

表4. TAM在不同多模态大语言模型(MLLMs)和数据集上的可解释性提升。具体结果列于补充材料K的表6。
在Qwen2-VL-7B、LLaVA1.5-13B等模型上,F1-IoU提升幅度5.45%-11.0%,且模型规模越大,解释质量提升越显著(表4)。
定性分析:多场景解释能力验证
对象定位与属性分析

图3. 使用Qwen2-VL-2B[51]模型在COCO Caption数据集[13]上TAM与最先进(SoTA)方法的可视化对比。最后一行中的“is”是一个具有背景真实标签的功能词。更多示例(包括复杂案例)见补充材料G。

图4. 在Qwen2-VL-7B[51]模型下,TAM在多种数据集[13,42,57]上呈现出高质量的定位结果。

图5. TAM支持解释和分析多模态大语言模型(Qwen2-VL-7B)的各种属性。更多示例见补充材料M。
高精度定位:在COCO Caption中,TAM准确高亮“叉子”“蛋糕”等对象,较CAM减少50%以上的背景冗余激活(图3)。 属性解释:支持颜色(“红色”)、动作(“奔跑”)、数量(“三个苹果”)等细粒度属性,例如在分析“圆形盘子”时,激活图精准覆盖圆盘轮廓(图5)。
失败案例诊断

图6. 在STAR[52]数据集上使用Qwen2-VL-2B[51]模型时,TAM显著提升了视频可视化的质量,冗余激活和噪声大大减少。请参见补充材料27中的大量示例以及图25中的视频失败案例分析。

图7. TAM支持在QK-VQA[37]数据集上进行失败案例分析。更多关于VQA的案例见补充材料(图24)、视频案例(图25)、视觉推理案例(图28)以及多轮对话案例(图31)。
QK-VQA失败分析:模型正确定位“沙漠”,但因缺乏“沙漠形成年份”的外部知识输出“don’t know”,激活图显示提示词“year”与视觉区域未建立有效关联(图7)。 视频理解错误:在STAR数据集中,模型误将“笔记本电脑”识别为“粉色盒子”,TAM显示激活焦点从电脑本体偏移至外壳(图25)。
视频与多模态场景
视频可视化:在STAR数据集上,TAM减少70%以上的时序冗余激活,清晰呈现“人开门”的动作序列,而CAM存在大量背景噪声(图6)。 多图像对话:支持4图像输入的相似性分析,例如识别“四张图中的狗”并高亮共同特征(图29)。
MLLM比较与应用扩展

图8. TAM支持多模态大语言模型(MLLMs)之间的定性比较。补充材料K中的图17和图18提供了大量示例。
模型可视化对比
Qwen2-VL vs. LLaVA vs. InternVL:Qwen2-VL在视觉激活强度上优于LLaVA,InternVL更依赖文本线索(如“西兰花”案例中,InternVL的视觉激活弱但文本相关性高)(图8)。 规模效应:LLaVA-13B较7B的Obj-IoU提升2.11%,但Func-IoU下降3.38%,表明大模型可能过度关注对象而忽略背景抑制(表4)。
潜在应用场景
医疗影像:结合TAM的像素级激活,可辅助定位病灶区域(如肺部结节),已有研究将其用于中文医疗MLLM的联合诊断(引用[21])。 自动驾驶:在鸟瞰图中解释模型对“行人”“交通灯”的识别逻辑,支持安全关键场景的决策追溯(引用[22])。
总结
这项工作聚焦于多模态大语言模型(MLLMs)在视觉可解释性方面的独特属性——其渐进式生成多个Token(token)的特性使解释过程复杂化。为此,本文提出了Token激活图(Token Activation Map, TAM)这一新颖方法:通过估计因果推理来减轻上下文Token的干扰,并结合秩高斯滤波器降低激活噪声,从而提供更清晰的视觉解释。实验结果表明,TAM显著优于现有最先进(SoTA)方法,能生成适用于多种场景的高质量可视化结果。
局限性。尽管取得了成功,但本文目前聚焦于视觉输入,其他模态(如音频)仍有待深入探索。此外,解释模型决策是一个可扩展的研究方向。所提出的TAM方法具有广泛的潜在应用,包括开放词汇分割、检测、图像 grounding、异常检测、遥感以及需要像素级激活的医学领域。本文的工作为提升这些领域的可解释性和实际应用价值奠定了基础。
知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,欢迎扫码加入一起学习一起卷!