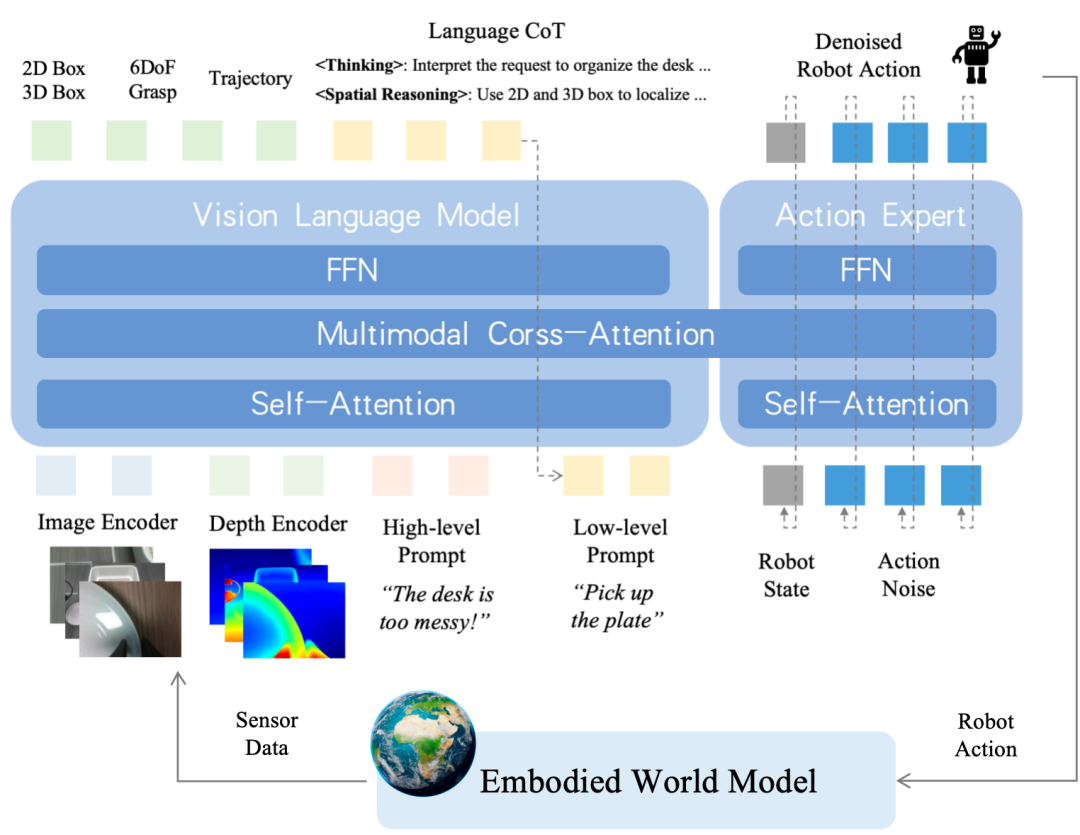
在输入端,对RGB图像与深度信息进行联合编码,提升模型对3D空间结构的理解能力以及对复杂场景的感知表征。
在输出端,系统可利用多种感知模块的中间输出(2D框、3D框、6DoF抓取点,末端执行器轨迹等)作为多模态监督信号,增强决策过程的准确性和鲁棒性。
引入了面向语言任务拆解的思维链(Chain-of-Thought,CoT)机制,将高层用户指令逐步解析为低层可执行的prompt,实现任务逻辑的结构化分解。与此同时,前序感知模块输出的中间结果也为CoT提供了空间推理所需的语义支持。
低层执行prompt将激活对应的action expert模块,并通过降噪解码机制生成机器人可执行的动作序列,从而实现从感知到动作的完整控制。