▲头图由AI生成

提示词:突然,前方街角的阴影里,一只漆黑的猫像一道闪电般窜出,身形轻盈而敏捷。女孩被吓得微微后退一步,雨水顺着帽沿落在她的肩膀上,溅起一圈细小水花。镜头侧面缓缓跟随,捕捉她的手伸出,试图触碰黑猫。猫的耳朵竖起,眼睛在路灯下闪着绿光,它轻巧地一跃,消失在湿漉漉的街道深处。
女孩愣了一秒,低头看着自己微湿的手指,嘴角悄悄上扬,露出一丝忍俊不禁的笑意。她摇摇头,雨伞下的脸被灯光映出温暖的光晕。随后,她调整步伐,撑开雨伞,加快了前行的脚步,雨水拍打伞面,伴随着她鞋底溅起的水花,融入街道的喧嚣中。
音效提示词:猫叫声轻响,随即消失;雨点拍打伞面滴答作响;远处偶尔传来汽车轰鸣声和脚步声,街道弥漫湿润气息。
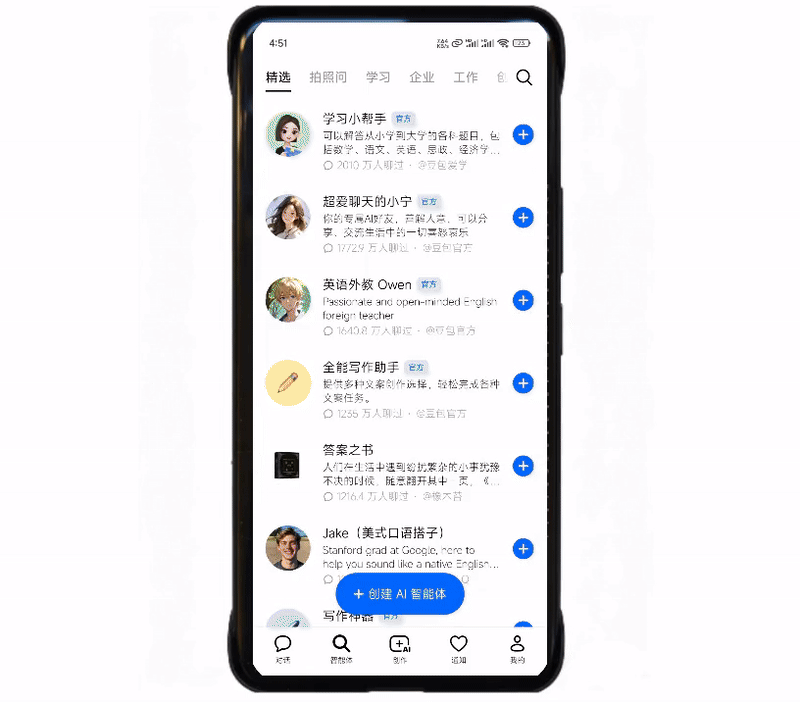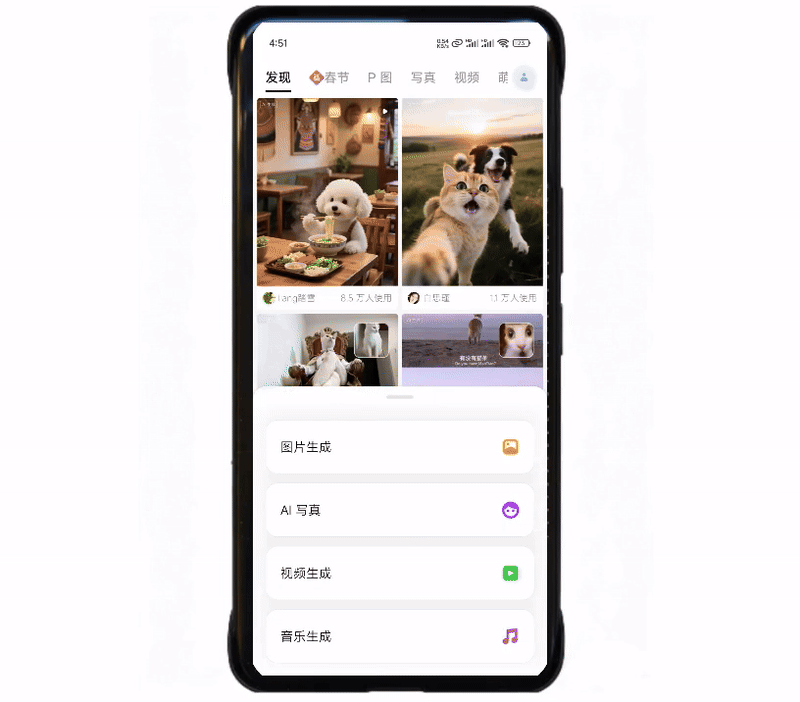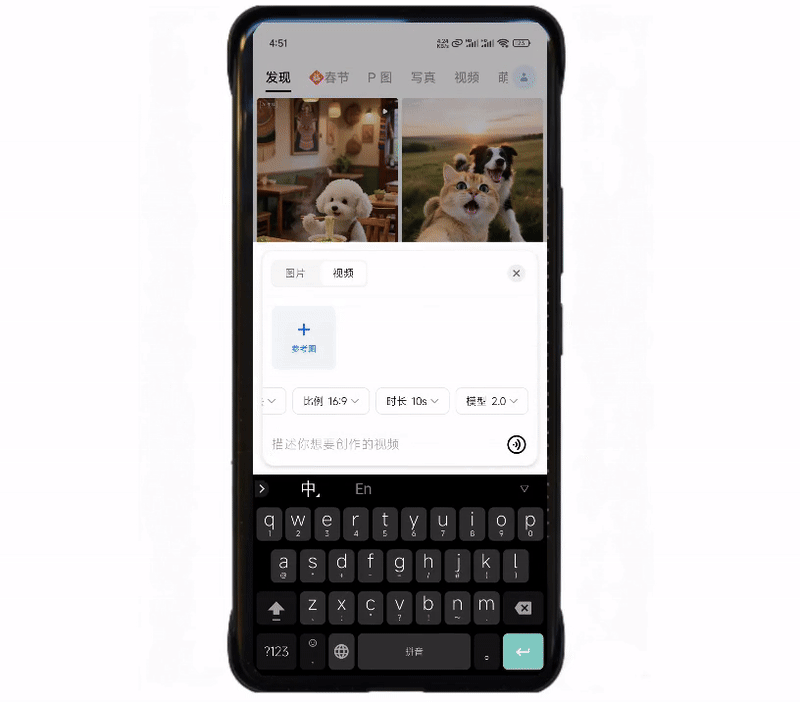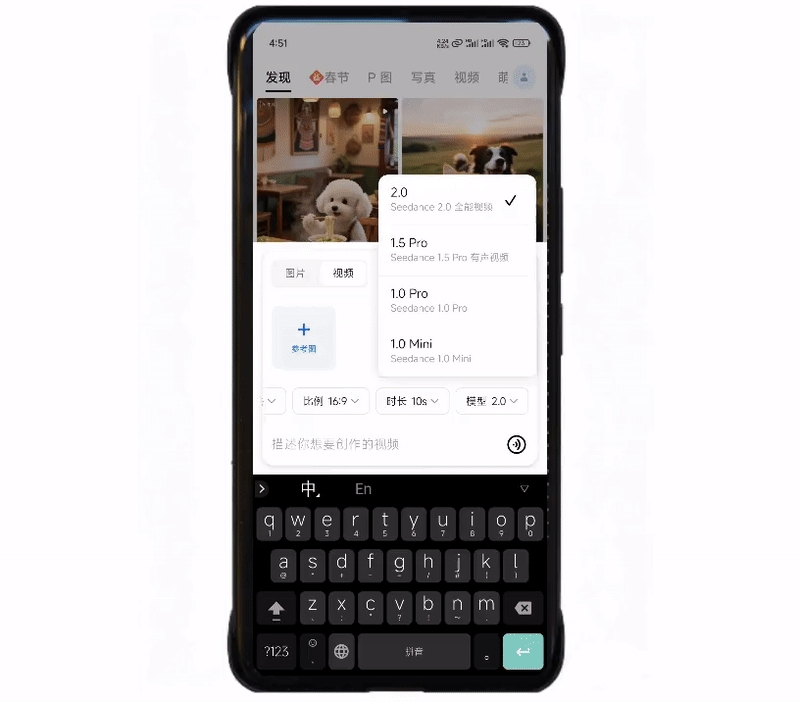
在大约等待了30秒后,豆包向我们发送了生成结果。提示词中描述的几个关键动作都在视频中得到了呈现,同时,画面中人物的衣着、样貌在不同的镜头中都保持了一致,视觉效果比较稳定。
音效方面,Seedance 2.0的配音与画面内容调性一致,而像是猫叫声、脚步声这些声音则与画面内容匹配,基本实现了音画同步。
美中不足的是,对于“雨水顺着帽沿落在她的肩膀上”这部分的描述,Seedance 2.0未能还原。平心而论,液体的渲染对大多数视觉生成模型来说还是较为困难的。
紧接着,我们又尝试了一个涉及音画同步的高难度场景:乐器演奏。此前,在我们的体验中,大部分视频模型都无法准确地将音乐与画面的演奏动作同步,要么节奏对不上,要么手指动作与音符不符,要么整体演奏显得生硬、不自然。
Seedance 2.0拿到的提示词如下:
街头音乐表演,鼓手敲击节奏、吉他手弹奏旋律,观众随节奏轻拍手,音乐是拉美风格。
Seedance 2.0的生成结果可以说是较为惊艳的,在音乐风格上,它满足了我们的“拉美风格”限定词,背景中的人物、建筑风格也符合拉美风的要求。
乐器演奏方面,鼓手的桶鼓轮奏动作与音乐的鼓点,基本达到了8成的契合度,这要比我们之前测试的字节视频生成模型好得多。
而在吉他手的演奏中,画面中手部按压的和弦和视频里模型生成的音乐也是基本契合的,左右手的手法都是自然、连贯且细节丰富,琴弦拨动与音符节奏高度对应。
细看还可以注意到,背景中观众拍手的动作和视频里的声音是精准卡点的。
我们的最后一个纯文本提示词考察的是一个超现实场景,这种场景在模型训练数据里可能分布较少,考察的是对罕见视觉元素、超现实组合和非日常场景的生成能力。
画面开场是一座夜晚的城市,全景俯拍,城市灯光闪烁,街道像河流般流动。随后,镜头慢慢拉近,出现几栋建筑缓缓离地漂浮,建筑底部闪烁着微光能量。空中漂浮的汽车像鱼群般游动,偶尔从建筑间穿梭而过。主角是一位身穿银色风衣的少年,脚下踩着悬浮板,从高楼之间穿行而过。 镜头切换至近景,少年伸手触碰漂浮的建筑,触碰瞬间建筑表面出现液态光纹,建筑缓缓旋转、折叠,随后化作光粒飞向夜空。背景出现巨大月亮,月亮上投射出城市倒影,光线折射在漂浮建筑和人物身上。
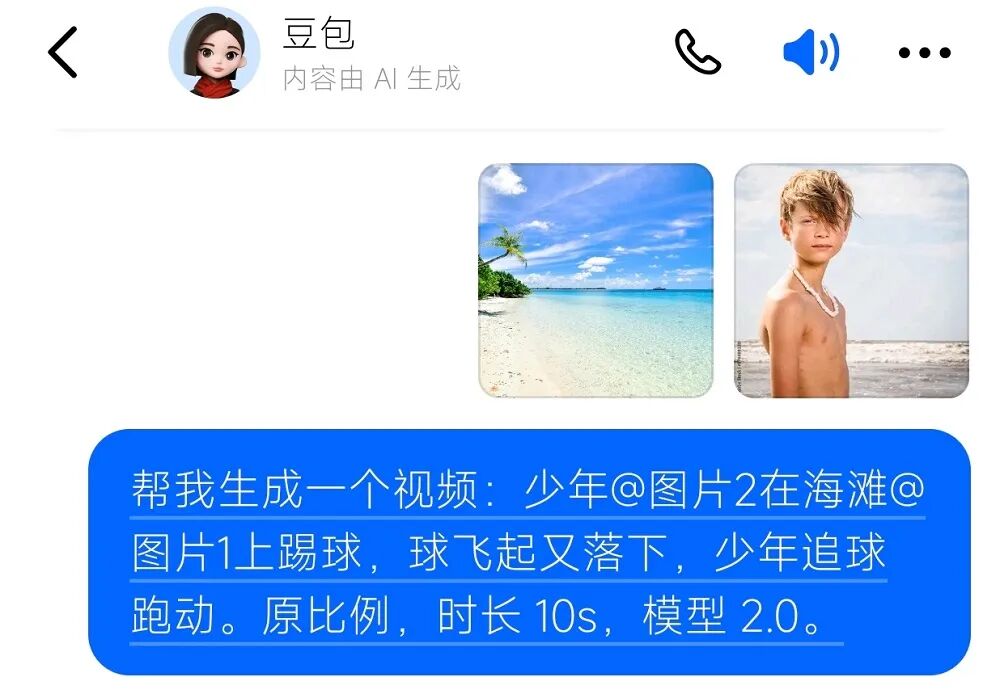

整体体验下来,Seedance 2.0的表现确实有明显提升。无论是长文本指令的理解与还原、复杂音画同步场景的精准匹配,还是超现实画面的稳定生成,它都展现出了明显强于以往模型的综合能力。
当然,它仍存在一些可以改进的地方,其中物理细节还有明显的优化空间。但在动作连贯性、人物一致性与镜头语言执行力上,Seedance 2.0已经开始接近成为可商用的创作工具。
随着Seedance 2.0开始进入豆包这样的大众产品,普通用户也开始能低成本、高频率地尝试视频创作。未来,视频的生产方式、创作门槛乃至内容形态,都可能被重新定义。