点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
星球内有20多门3D视觉系统课程、200+场顶会直播、顶会论文最新解读、3D视觉算法源码、项目承接、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎加入!

模拟提供了一种可扩展且低成本的方式,用于丰富VLA的训练,减少对昂贵的真实机器人演示依赖。然而,大多数模拟-真实联合训练方法都依赖于监督式微调(SFT),这种方法将模拟视为静态的演示来源,并未利用大规模的闭环交互。因此,实际应用中的收益和泛化能力往往受到限制。近日,清华大学于超团队提出了一种基于强化学习(RL)的模拟-真实联合训练(RL-Co)框架,该框架在保留实际应用能力的同时,充分利用了交互式模拟。
方法遵循通用的两阶段设计:首先,使用真实和模拟演示的混合数据,通过SFT对策略进行预热启动;然后,在模拟环境中通过强化学习对其进行微调,同时针对真实世界数据添加辅助监督损失,以锚定策略并减轻灾难性遗忘问题。
实验使用两种具有代表性的VLA架构(OpenVLA和 )在四个真实桌面操作任务上验证了该框架,观察到与仅基于真实数据的微调以及基于SFT的联合训练相比,提出的方法均取得了持续改进,其中OpenVLA在真实世界中的成功率提升了24%,提升了20%。除了更高的成功率外,RL联合训练还展现出了对未见任务变体的更强泛化能力,并显著提高了真实世界的数据利用效率,为利用模拟来增强真实机器人部署提供了一条实用且可扩展的途径。

论文标题:Beyond Imitation: Reinforcement Learning-Based Sim-Real Co-Training for VLA Models
关键词:VLA(视觉-语言-动作)/后训练/仿真-真机协同训练/强化学习/真机成功率/数据效率
Arxiv: https://arxiv.org/abs/2602.12628
Codes: https://github.com/RLinf/RLinf
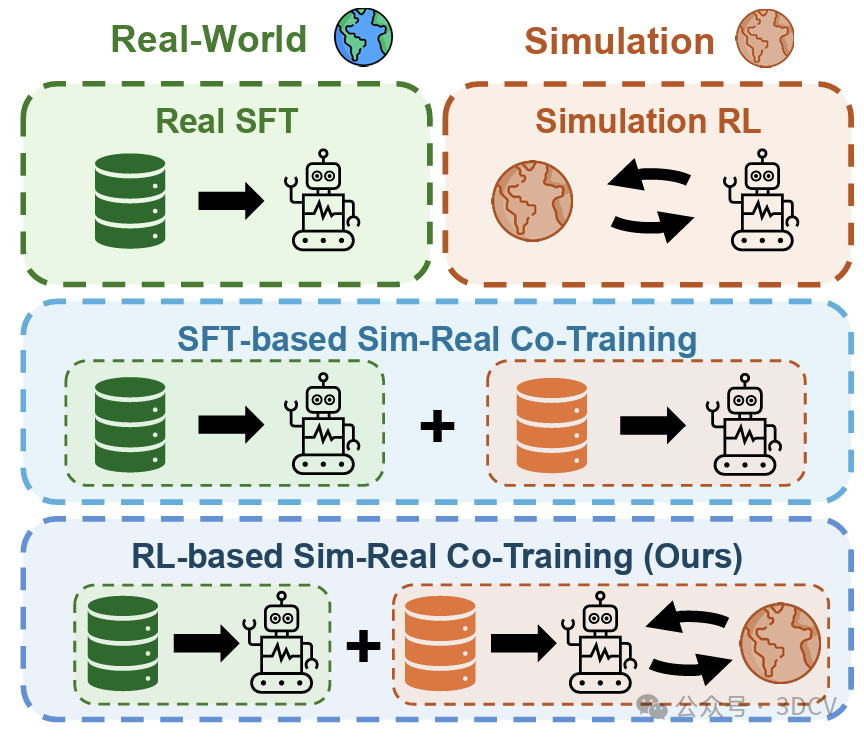
RL-Co的核心优势
一句话:用 监督微调(SFT)先把路铺好,再用仿真里的强化学习(RL)把能力练扎实,同时用少量真机数据“拉住”别跑偏——把仿真的“可交互”优势真正用起来。 真机性能飞跃(SFT co-training → RL-Co): OpenVLA:成功率 40.0% → 64.0%(+24.0%) :成功率 45.9% → 66.2%(+20.3%) 泛化更稳:在未见物体/未见初始状态下, 的掉点显著更小。 更省真机数据:Open Drawer 上,RL-Co(20 条真机) 的效果能对标/不弱于 基线(200 条真机)。 低成本仿真路线,不追求高成本的“细粒度孪生”:用 ManiSkill 构建任务对应环境,只抓住关键几何与相机视角,不去 1:1 还原材质、光照等低层视觉细节。
01. 背景:在“高成本重建”与“海量真机”之外,寻找第三条路
当前,具身智能正处于一场激烈的“数据与路线之争”中。
为了解决 VLA 模型在真机上“不敢动、学得慢、泛化难”的痛点,行业内主要分化出了两条截然不同的技术路线:
一条是“重构建”的极致仿真路线:近期,基于 3D 高斯泼溅(3DGS)等技术的高保真数字孪生备受关注。这条路线主张通过扫描真实场景、构建像素级对齐的“赛博空间”,让机器人在完美的仿真中“疯狂试错”。这种方法效果虽好,但对环境建模的精度要求极高,流程复杂,难以快速复用到每一个新场景。 另一条是“堆真机”的暴力美学路线:依赖大规模的真机遥操作数据采集。但这如同无底洞,边际成本极高,且单纯的模仿学习(BC)始终难以突破演示数据的分布边界。
那么,有没有一种更“轻量”、更“普适”的解法?
在上述“高举高打”的争论之外,另一支研究力量正在探索仿真-真机协同训练(Sim-Real Co-Training)的潜力。这条路线不追求 1:1 还原现实的极致画质,而是使用低成本的粗糙仿真,试图通过“混合双打”来解决问题。
然而,传统的协同训练往往走入了误区:它仅仅把仿真当成了“静态数据生成器”。
大多数工作只是把仿真轨迹混入真机数据中,继续做 SFT(监督微调)。这种做法虽然增加了数据量,却丢掉了仿真最核心的优势——可交互性。如果不利用 强化学习(RL)在仿真里进行闭环探索,模型就永远只能是对轨迹的拙劣模仿,一旦遇到分布偏移(Distribution Shift),依然会发生误差累积。
RL-Co 正是在这个背景下诞生的。也试图回答一个关键问题:
如果我们既不想花大价钱搞“全拟真数字孪生”,又不想做“真机数据苦力”,能不能把 Sim-Real Co-Training 的范式升级一下?
RL-Co 给出的答案是:用 Sim 里的 RL 练“内功”(交互能力),用 Real 里的 SFT 练“招式”(规范动作)。 通过这种范式证明了:并不需要昂贵的“完美孪生”,只要把低成本仿真里的交互用对,一样能实现真机性能的飞跃。
02. RL-Co 是什么?两阶段把“交互”和“真机能力”同时抓住
RL-Co 的核心很简单:先用 SFT 把策略“扶上马”(初始化),再用仿真里的 RL 让它“跑得更稳”(交互优化),同时用少量真机数据做正则,让它别在训练过程中把真机能力忘了。
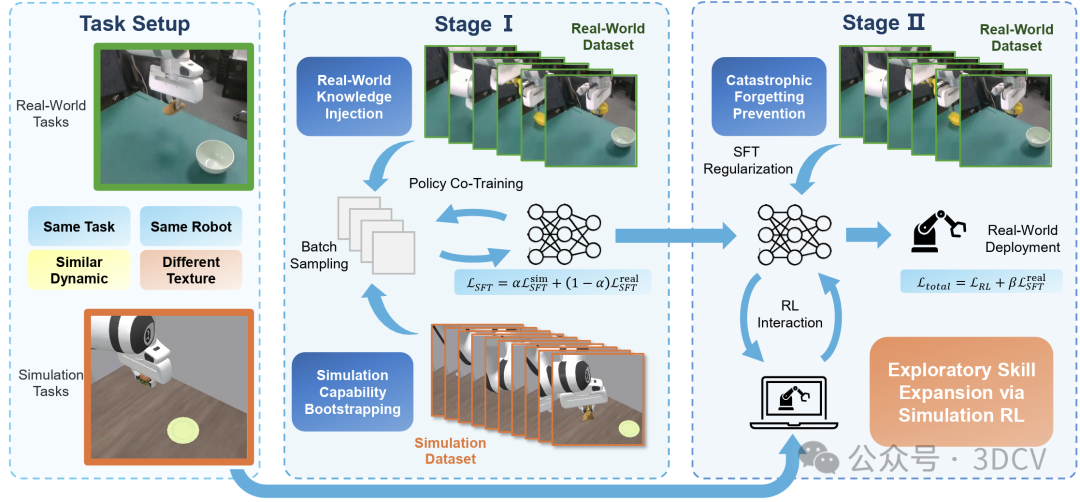
设计 1:Stage I 用“仿真 + 真机”做 SFT 初始化
从预训练的 VLA 模型起步,混合真机演示 和 仿真演示 进行监督微调。
这一步不求完美,但求“上道”:先把任务相关的真机知识快速灌进去,同时也让策略在仿真里达到“至少能做成一点”的水平,给后续 RL 一个靠谱的起点。
设计 2:Stage II 在仿真里做 RL,同时用真机 SFT 正则“拉住”分布
之后在仿真 RL 的优化目标里,加入一项真机 SFT 的正则项:
:靠仿真闭环交互最大化任务回报,把执行能力和鲁棒性练出来 :用少量真机轨迹做“锚点”,缓解 RL 过程中对真机能力的遗忘
03. 实验:四个真机任务 + 对应轻量仿真
在 4 个桌面真机任务上验证 RL-Co,并用 ManiSkill 搭建一一对应的仿真环境。值得注意的是,仿真侧重点是交互完整与相机/布局对齐,而不是追求逼真渲染。
03.1 任务(真机)
Pick and Place:抓取物体并放入目标容器 Push Cube via Instruction:按语言指令推动指定颜色方块 Open Drawer:打开抽屉(接触丰富) Close Drawer:关闭抽屉
03.2 数据(真机 + 仿真)
真机演示():SpaceMouse 遥操作采集;每个任务 20–50 条成功轨迹 仿真演示():MimicGen 扩增;先把真机轨迹在仿真里 replay 当 seed,再剪掉长段无效自由空间运动;每个任务生成 1000 条成功轨迹

04. 结果:真机更强、分布外更稳、训练更不挑参数
结果一:真机成功率提升(OpenVLA 与 都受益)

平均成功率(SR)提升: OpenVLA:Real-only 16.5 → SFT 协同 40.0 → RL-Co 64.0(相对 SFT 协同 +24.0) :Real-only 26.7 → SFT 协同 45.9 → RL-Co 66.2(相对 SFT 协同 +20.3) 分任务直观表现(SR): OpenVLA(RL-Co):Pick&Place 58.8,Push Cube 68.3,Open Drawer 35.0,Close Drawer 95.0 (RL-Co):Pick&Place 81.3,Open Drawer 65.0,Close Drawer 100.0(Push Cube 仍偏难)
结果二:分布外泛化更稳(未见物体/未见初始状态掉点更小)
在 Pick and Place() 上测试两类分布外:未见物体、未见初始状态。RL-Co 在两种情况下的性能下降幅度更小:

结果三:训练更稳(SFT 比例敏感,但 RL 阶段收益更稳定)
SFT 的混合比例 会显著影响协同训练的真机效果;而在完成 SFT 初始化后,RL-Co 在不同正则权重 下都能带来稳定收益,并把成功率拉到高于各类 SFT-only 设置的水平:

05. 数据效率:20 条真机 + RL-Co,对标 200 条真机基线
当真机专家数据扩展到 200 条,观察两类基线随真机数据量增长的效果,并与“固定 20 条真机”的 RL-Co 对照:
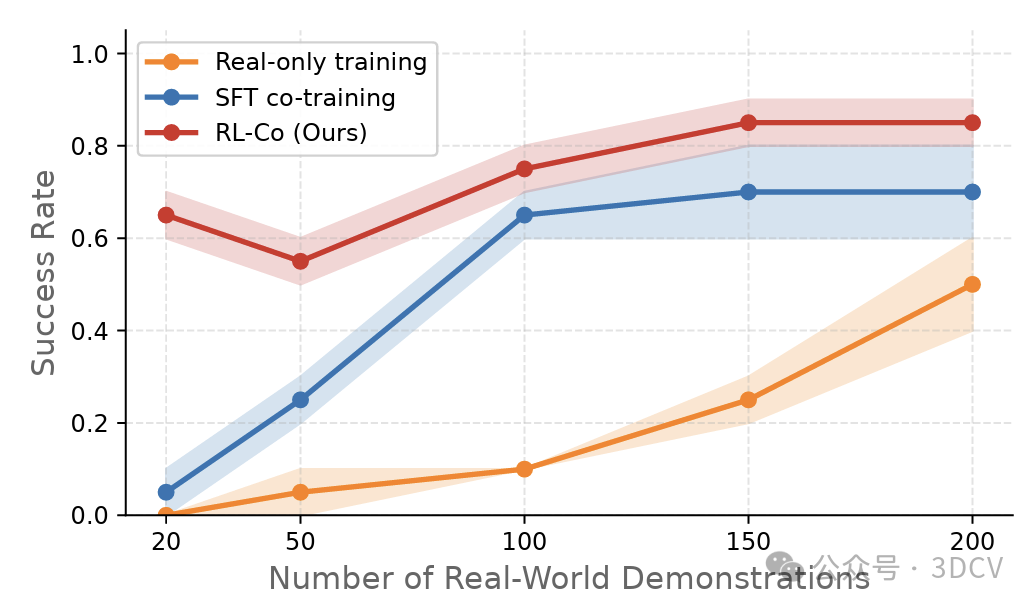
结论很直接:真机数据当然越多越好,但把仿真里的交互用对,往往更划算。
06. 消融:两阶段各自解决什么问题?
这里重点检查两件事:没有“初始化”,RL 还能不能练起来?以及 没有“真机锚点”,RL 会不会把真机能力练丢?
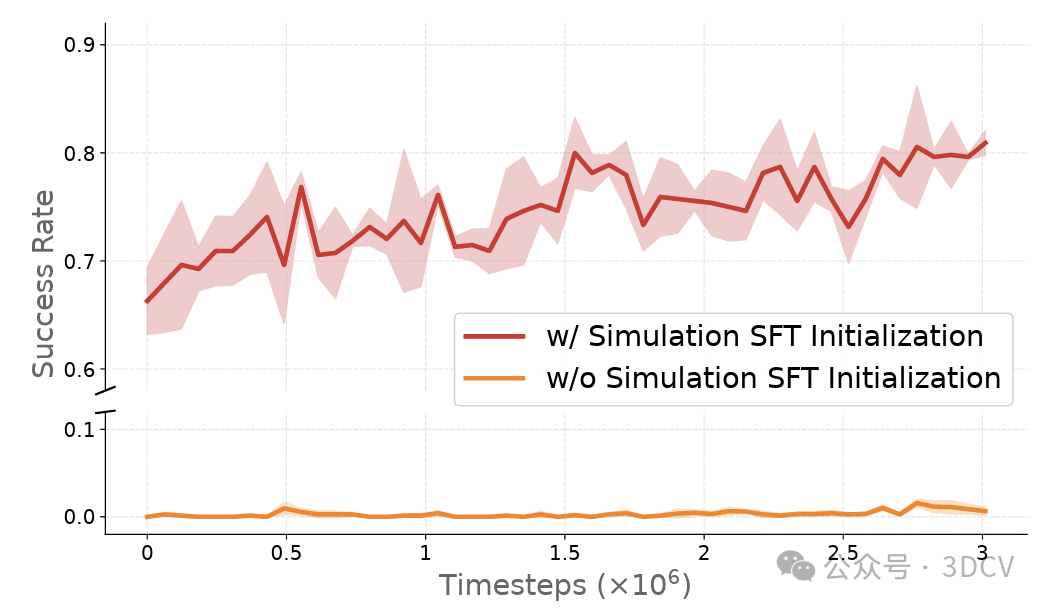
06.1 没有仿真 SFT 初始化:RL 很难有效推进
如果 Stage I 不用仿真数据做 SFT 初始化,直接从“只见过少量真机演示”的策略开始在仿真里做 RL,训练会变得非常慢:样本效率显著下降,长时间都难以学到有效行为(见图 8)。
06.2 没有真机 SFT 正则:仿真里越练越强,真机上反而会忘
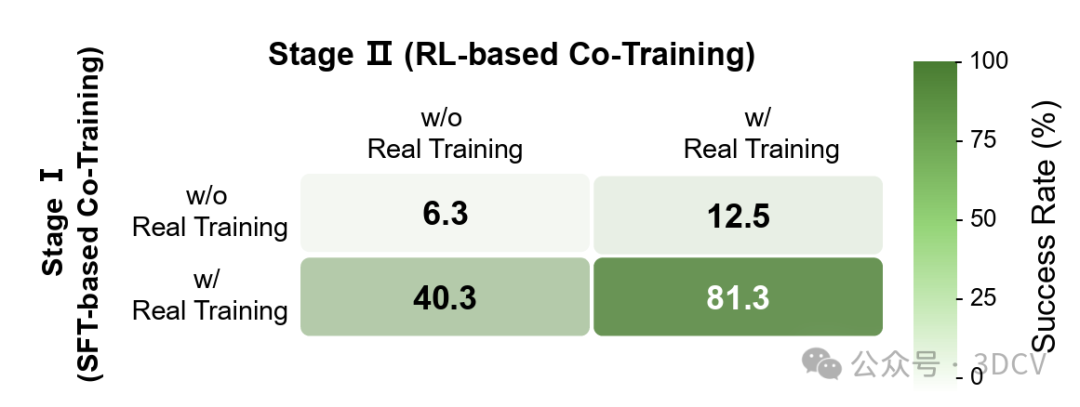
如果 Stage II 去掉真机 SFT 正则,策略会出现明显的“真机能力遗忘”。在消融设置里,成功率从 81.38% 降到 40.25%(见图 9)。这说明:仿真交互能把策略推向更高回报,但如果没有真机数据把分布“拉住”,提升可能无法稳定转化为真机收益。
07. 总结:RL-Co 的关键信息、意义与下一步
回到开头的问题:我们希望更充分地利用仿真的优势(可交互、可规模化),同时让提升真实发生在真机上。 RL-Co 给出的答案是一个“更工程可落地”的组合范式:
方法上:两阶段流程——Stage I 用真机+仿真做 SFT 初始化;Stage II 在仿真里做 RL 交互优化,并用真机 SFT 正则把策略分布锚定住。 效果上:在 4 个桌面真机任务、两类代表性 VLA(OpenVLA 与 )上,RL-Co 带来一致的真机成功率提升;同时在分布外设置下掉点更小、训练对超参更不敏感;在 Open Drawer 上也体现了更好的真机数据效率(20 条真机即可对标更大规模真机数据的基线)。 机制上:仿真 RL 负责“把能力上限练出来”,真机正则负责“把能力留在真机分布里”;仿真 SFT 初始化则让后续 RL 变得可学、可收敛。
更重要的是,这个结果给出一个清晰信号:仿真不一定要走高成本的细粒度孪生路线。只要把“交互”这件事用好,并配合少量真机数据做锚定,轻量仿真也能稳定带来真机收益。
未来方向
更长序列、更复杂接触任务:在抽屉类任务之外,把 RL-Co 扩展到更长时序、更多阶段的真机操作,检验交互带来的累积优势。 更通用的协同训练配方:进一步减少对 等超参选择的依赖,让“初始化 + 交互 + 真机锚定”更自动、更稳健。 更广的场景与本体:在更多物体变化、视角变化、甚至不同机器人平台上验证,让“仿真交互 → 真机提升”的收益更可迁移、更可复用。
本文仅做学术分享,如有侵权,请联系删文。
。



添加微信:cv3d001,备注:姓名+方向+单位,邀请入群。










![2025年中国卫星通信终端设备行业政策、发展现状及趋势研判:行业向大众消费渗透提速,手机卫星直连引领布局重点[图]](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-11-11/69128afb54ba6.jpeg)