从2025年价值200亿美元的震撼收购,到2026年GTC大会上黄仁勋揭晓谜底,英伟达正通过将 Groq 的 LPU(语言处理器单元)整合进其最新的 Vera Rubin 平台,设计完全不同架构的芯片。
GPU和 Groq 的 LPU(Language Processing Unit)之间,关于“吞吐量”与“延迟”的考虑,这是一个新的答案。
Part 1

英伟达的 GPU 帝国是建立在高吞吐量(High Throughput)之上的。凭借数以千计的 ALU 单元,GPU 极其擅长在大规模并行任务中“大力出飞砖”,整个AI的突破是依靠GPU构建起来的,但这种架构设计有一个天生的短板:高延迟。

在 2025 年之前的 AI 世界,这并不是大问题。
但在 2026 年的智能体(Agentic AI)时代,情况变了:
◎ 人类与机器的交互要求令牌(Token)生成速度达到每秒数百个,才能产生丝滑的即时感。
◎ 智能体之间的通信需要极低的响应延迟。如果两个 AI 在协作时互相等待对方“转圈圈”,整个系统的效率会呈指数级下降。
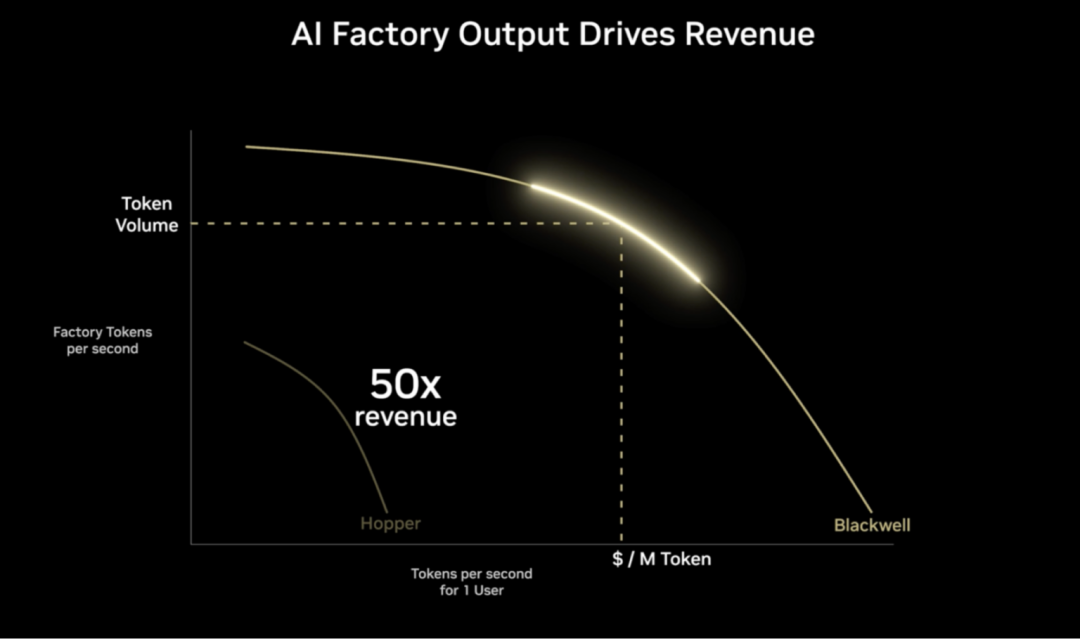
GPU 为了维持高吞吐,需要通过复杂的调度和缓存机制来掩盖延迟,这在处理单用户、串行化的解码(Decoding)阶段时显得力不从心。
简单来说,GPU 擅长一次性处理一吨货物(预填充阶段),而 LPU 则擅长以光速快递一个个小包裹(生成阶段)。英伟达单纯靠优化 GPU 架构已经无法在延迟曲线上取得质的突破。于是选择了 Groq。
LPU 这种“反其道而行之”的设计,牺牲吞吐量、通过海量片上 SRAM 实现极致延迟,来补齐了英伟达高端机架的最后一块短板。

在 Vera Rubin 架构中,LPU(语言处理器单元)的引入本质上是对 AI 推理流程的一次“硬件级拆解”,通过极端本地化内存(采用 500MB 片上 SRAM 替代 HBM,实现 150TB/s 的恐怖带宽)彻底消除了访存等待,并利用确定性执行(将动态调度转为编译期静态调度)抹平了计算延迟的不确定性。
在实际运行中,英伟达将算力密集的 Prefill 任务留给 GPU,而将延迟敏感的串行 Decode 任务交给 LPU,精准的异构分工,可以AI 推理正式告别了通用芯片的“大锅饭”时代,跨入了极致响应的专业化阶段。


针对“解码阶段”的专用优化,推理分为两步: Prefill(并行,算力密集) 和 Decode(串行,延迟敏感) ,LPU专注第二步快速token生成和最小化每一步延迟 ,LPU就不是通用目的的AI芯片,在Agent时代是“token生成机器”。

Part 2
收购 Groq 之后,英伟达最迅速的动作就是NVIDIA Groq 3 LPX 机架。
推出了这不再是实验室里的原型机,而是作为 Vera Rubin NVL72 系统的一个“暴力插件”存在的。

内存带宽的降维打击
LPX 机架的核心是 LP30 芯片,它最恐怖的地方在于配备了 500MB 的片上 SRAM。虽然容量看起来不大,但其内存带宽高达 150 TB/s。
作为对比,传统的 HBM 显存虽然已经很快,但在 SRAM 这种“计算单元隔壁的仓库”面前,依然显得慢如蜗牛。这意味着 LPU 在执行前馈网络(FFN)等任务时,数据读取几乎没有等待时间。
确定性调度的艺术
与传统处理器依赖硬件动态调度不同,Groq 采用了静态指令调度。编译器在代码生成阶段就已经排好了所有执行时序。
这种“编排好的交响乐”模式,消除了指令冲突和数据等待的不确定性,使得推理过程像精密时钟一样准时。
异构协同的“解码专家”

在 Vera Rubin 机架中,英伟达实施了精细的分工:
◎ Rubin GPU:负责计算密集型的“预填充”和解码中的“注意力机制”。
◎ Groq LPU:负责对延迟极度敏感的“前馈网络”执行。
这种“加速器之上的加速器”方案,让系统在同等速率下的吞吐量提升了 35 倍以上。
Part 3

英伟达对 Groq 的整合绝非一次性买卖,从 GTC 公布的路线图看,LPU 已经正式进入了英伟达的核心产品序列:
◎ 2027 年(LP35):重点在于支持 NVFP4 数据格式。这是英伟达主推的低精度推理标准,能显著缓解 SRAM 的容量压力,让更小的存储空间跑出更强的性能。
◎ 2028 年(LP40):这一代将彻底“归化”。它将放弃 Groq 原有的互联技术,全面接入英伟达的 NVLink 生态。这意味着 LPU 与 GPU 之间将实现真正意义上的原生高速互联,甚至可能出现 GPU+LPU 封装在一起的超级芯片。
有趣的是,随着 LPU 的上位,此前英伟达内部规划的 Rubin CPX(原定用于加速解码的 GDDR7 版本 GPU)已经基本宣告退场。这标志着英伟达彻底放弃了“用 GPU 解决一切”的执念,转向了更加激进的异构计算路线。
正如之前在分析恩智浦和英伟达合作时提到的,机器人和智能体需要的不仅是“聪明”,更是“实时”与“可靠”。
英伟达通过吸收 Groq 的 LPU 技术,正在把 AI 推理从一种“概率性的信息处理”转变为一种“确定性的物理响应”。未来的高端 AI 集群将不再是清一色的 GPU,而是一个由 GPU 负责“思考”、LPU 负责“反应”的复杂有机体。










