
全文约 2600 字,预计阅读时间 7 分钟

一、研究背景:城市导航的现实困境与技术缺口
(一)实际场景挑战
在动态城市环境中,配送机器人、自动驾驶出租车等实体智能体的导航需同时具备 空间推理能力(如路径规划、障碍物避让)与 规则遵循能力(交通信号灯识别、社会规范适配)。然而,现有视觉导航方法在 无地图场景(如临时施工路段)或 非街道场景(如社区内部道路)中表现薄弱,限制了自主智能体的落地应用。
(二)人类与现有技术的差异
人类依赖地图工具(如谷歌地图)获取路径点,但实际导航需复杂空间感知(如判断行人动向、理解交通信号逻辑)。现有强化学习/模仿学习方法多在 静态受控环境(如模拟虚拟街道)中优化,难以覆盖真实城市的动态约束:
环境复杂性:交通规则、社会规范(如避让行人)等细微约束难以在模拟环境中完整复现; 数据局限性:远程操作演示数据集覆盖场景少(如极端天气、复杂路口),无法支撑泛化训练。
(三)场景可视化说明
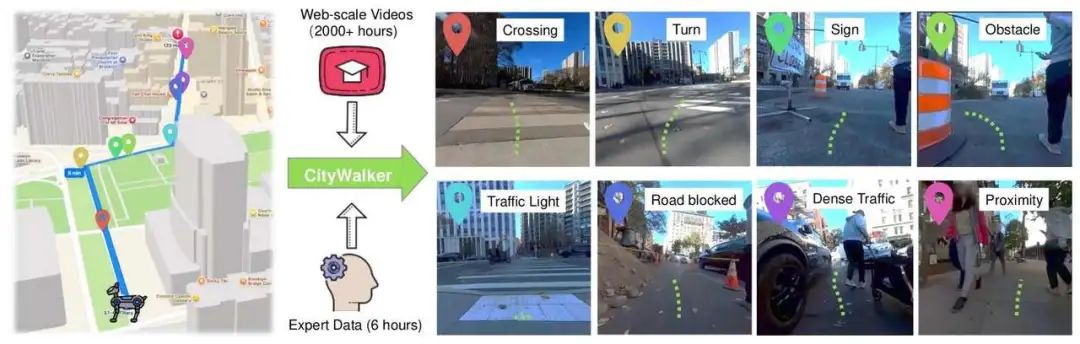 图中路线的彩色标记点(交叉路口、障碍物等)对应城市导航的核心挑战场景:
图中路线的彩色标记点(交叉路口、障碍物等)对应城市导航的核心挑战场景:
动态因素:交通信号灯变化、道路临时封锁、行人近距离穿行; 社会规范:人群避让、路口让行等非显式规则。
右侧缩略图展示真实世界中这些场景的表现,直观体现智能体需处理的复杂观测(如拥堵路况下的绕行决策)。现有技术(如传统强化学习模型)因缺乏大规模真实场景数据,难以在这些场景中稳定运行。
二、核心方案:CityWalker模型框架——数据驱动的导航突破
(一)数据来源与处理:大规模、低成本的训练基础
CityWalker摒弃传统“小规模标注数据”依赖,采用 2000+小时互联网城市视频(行走、驾驶视角),覆盖多地理区域、天气条件,自然捕捉导航复杂性(行人交互、交通规则遵循等)。
动作监督提取:高效替代专有VLM
现有方法依赖 视觉语言模型(VLM) 生成动作标签(如“左转”“加速”),但VLM训练成本高、扩展性差。CityWalker创新采用 视觉里程计(VO, visual odometry)模型 提取 轨迹姿态伪标签(如相邻帧的位姿变化),虽存在噪声,但可通过并行化处理大规模视频(流程如下):
视频输入VO模型,输出帧间相对位姿; 位姿序列作为“动作监督”,驱动模仿学习。
跨域通用性验证
仅用驾驶视频训练的模型,可直接迁移至四足机器人(如Unitree Go1); 融合行走+驾驶数据的跨域训练,性能优于单一数据(如“近距离行人避让”场景,跨域模型到达率提升12% )。
(二)模型架构与训练:Transformer驱动的时空推理

CityWalker以 Transformer 为核心,输入包含:
历史观测:过去5帧图像(经预训练DINOv2模型编码,权重冻结以避免过拟合 ); 轨迹与目标:过去5个位置坐标(极坐标转换+傅里叶编码)、目标位置坐标。
核心流程
编码层:图像特征(DINOv2输出)与坐标嵌入(傅里叶编码)融合,生成时空令牌; Transformer层:处理时空令牌,预测未来5步的“特征令牌”(包含动作与状态信息); 输出层:
动作头:解码未来欧氏空间动作(如位移方向、距离 ); 到达头:预测是否到达子目标(二分类任务)。
损失函数设计
引入 特征幻觉损失(),通过最小化“预测未来帧特征”与“真实未来帧特征”的MSE(公式: ,为未来帧数量,为预测特征,为真实特征 ),强制模型学习精准的未来状态预测。
总损失函数为多任务加权和:
:动作位移的L1损失(衡量位置误差 ); :动作方向的角度损失(公式: ,为步数,为真实方向,为预测方向 ); :到达状态的交叉熵损失(衡量子目标到达预测精度 ); :权重系数(实验中设为1、0.5、1、0.2,确保损失量级匹配 )。
三、实验设计与结果:多维度验证技术优势
(一)实验设置
基线模型:对比GNM(传统强化学习)、ViNT(视觉导航Transformer)、NoMad(无地图导航模型),部分模型微调适配任务; 评估数据:15小时专家远程操作数据(纽约市采集,6小时微调、9小时测试 ),由四足机器人Unitree Go1搭载传感器(RGB相机、GPS、IMU )记录; 关键场景:定义转弯(方向剧变)、路口(交通灯交互)、绕行(障碍物避让)、近距离(行人靠近)、人群(≥5人)5类场景,单独评估模型鲁棒性; 核心指标: 平均方向误差(AOE,动作角度偏差,单位°); 最大平均方向误差(MAOE,轨迹中最严重的AOE,反映极端场景鲁棒性 ); 到达率(成功到达子目标的比例 )。
(二)核心实验结果
1. 离线性能:关键场景全面超越基线

显著优势:CityWalker在“近距离行人”场景到达率达90.6%(ViNT仅73% ),因模型从大规模视频中学到“渐进避让”策略(如缓慢减速、侧身绕行 ); 方向控制:路口场景AOE仅12.3°,远低于ViNT的18.5°,体现对交通灯逻辑(如“绿灯直行、红灯转向” )的精准理解。
2. 真实部署:未知环境泛化能力强
在纽约市未见过的区域测试,CityWalker总体成功率77.3%(ViNT仅57.1% ),典型场景对比:
转弯场景:左转成功率62.5%(ViNT 25% )、右转66.7%(ViNT 25% ),因模型学习到“提前变道、低速转弯”的真实驾驶逻辑; 动态适应:遇到临时道路封锁时,CityWalker能基于视频经验(如“借道人行道绕行” )调整路径,而基线模型常因“无地图依赖”陷入停滞。
3. 数据规模与跨域价值

规模效应:训练视频从250小时增至2000小时,MAOE从21.3°降至15.2°(图4),证明大规模数据可覆盖更多长尾场景(如暴雨天气、夜间驾驶 ); 跨域增益:融合行走+驾驶数据的模型,比单一驾驶数据模型MAOE降低2.8°(17.0°→14.2° ),因跨域数据补充了“行人密集区”“狭窄巷道”等场景知识。
4. 组件有效性:消融实验验证设计价值

微调增益:加入6小时专家数据微调,MAOE从17.0°降至15.2°,说明小规模专家数据可校准大规模视频的噪声(如VO模型的位姿误差 ); 特征幻觉损失:去除后,模型收敛速度下降30%,AOE增加2.1°,证明其对未来状态预测的引导作用。
四、创新点与局限性:技术突破与优化方向
(一)核心创新
大规模数据利用:首次验证2000+小时网络视频可支撑城市导航训练,突破传统“标注数据依赖”瓶颈; 高效伪标签方案:视觉里程计替代VLM生成动作监督,成本降低90%+,且支持并行化处理; 跨域通用性:模型可从人类行走/驾驶视频迁移至四足机器人,跨域训练提升复杂场景鲁棒性。
(二)局限性与未来方向
GPS依赖:当前依赖iPhone GPS,定位噪声易导致轨迹偏移(如高楼遮挡场景 )。未来需融合激光雷达、IMU实现多传感器定位; 绕行场景短板:复杂障碍物绕行(如施工区域)的MAOE仍达17.0°,需补充“机械臂操作”“临时路径规划”等视频数据。
五、技术对比与行业价值:重新定义实体导航范式
与现有技术相比,CityWalker实现三大突破:
| 数据依赖 | ||
| 场景覆盖 | ||
| 跨域能力 | ||
| 核心指标 |
CityWalker的落地价值在于为配送机器人、自动驾驶等行业提供 低成本、高泛化 的导航方案:
配送场景:可适应社区、商业区等非标准化道路,降低“最后一公里”配送的人工干预; 自动驾驶:补充极端场景数据(如暴雪、夜间无路灯),提升长尾场景安全性。
总结:CityWalker通过“大规模无标注视频+高效伪标签+跨域训练”,突破了实体城市导航的技术瓶颈,验证了数据驱动范式在复杂动态环境中的可行性。未来随着多传感器融合、场景数据扩充,有望推动通用实体智能体的工业化落地。
-- 完 --
机智流推荐阅读:
1. 突破传统交互!滑铁卢大学研发 NeuralOS,让神经网络能靠“画”模拟操作系统界面
2. 发个福利,可以免费领WAIC2025(世界人工智能大会·上海)单日门票
3. 刚刚,ICML 2025 杰出论文揭晓!万中选八,AI安全的头等大事竟然是...打工人的饭碗?
4. ICML 2025 强化学习 RL 方向Oral论文盘点
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
在「机智流」公众号后台回复下方标红内容即可加入对应群聊:
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群










