2026年,AI服务器市场的真实业态和前两年已发生明显变化。过去两年,行业核心竞争基本围绕高端GPU货源展开,市场增长高度依赖头部科技企业的大模型训练集群集中采购。
但现在,随着各类AI应用真正落地商用,HBM与先进封装的产能约束、液冷算力基建的硬性门槛、推理场景的规模化爆发,改写了行业竞争规则,赛道从单一的算力指标角逐,转向综合落地能力比拼。由此,AI服务器来到了赛程的下半场。
算力供应链承压
芯片、存储与封装的多重挑战
这种综合落地能力的比拼,首先便体现在上游核心零部件的供给约束上。
当前HBM全球市场由三星、SK海力士、美光三家主导,各家技术路线差异显著。SK海力士市场份额最高,作为英伟达Vera Rubin平台核心供应商,依托长期供货协议锁定大量HBM4产能;三星在实现HBM4量产基础上,提前发布HBM5原型,并搭配自研散热方案提升稳定性;美光主打低功耗HBM产品,重点适配中端算力与车载AI场景。三大存储厂商均将中长期产能通过长单锁定至头部芯片厂与云厂商,供需偏紧持续推高硬件成本,考验中游整机厂商的成本控制能力,并对高端算力硬件的交付周期提出更高要求。

先进封装产能紧张,进一步放大行业供给压力。当前高端AI芯片普遍采用2.5D、3D堆叠工艺,台积电CoWoS封装产能长期供不应求,仅英伟达就占据绝大部分产能。尽管台积电持续扩产现有产线,并布局CoPoS、SoIC、CPO等前沿技术,但新产能、新工艺落地周期较长,短期难以填补市场缺口。与此同时,英特尔EMIB、Foveros先进封装良率稳步提升,三星发力芯片+存储一体化封装,日月光、安靠等封测大厂持续加码资本开支、新建产线,全力适配高端算力产能需求。
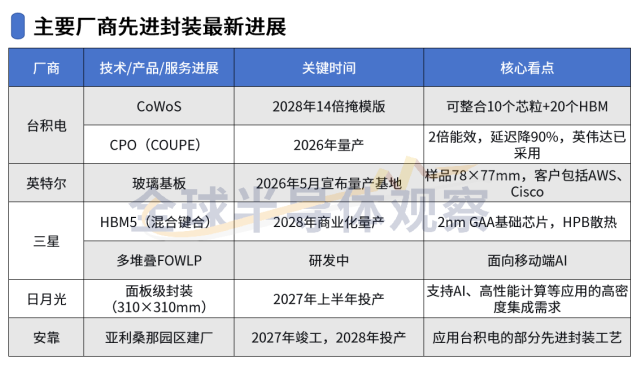
受制于上游产能约束,全球芯片厂商研发思路更趋务实,研发重心向量产落地、机房适配、业务实际需求倾斜。先进制程赛道参与者持续扩容,台积电2nm产能稳步爬坡,同步推进1.4nm、1nm前沿技术研发;英特尔18A制程良率超预期,进度领先市场;三星2nm GAA工艺逐步成熟,美国新建晶圆厂即将投产;日本Rapidus依托政府资金攻坚2nm技术。

海外三大芯片厂商产品布局均贴合落地需求:英伟达Vera Rubin平台兼顾训练与推理负载,重点优化HBM适配与液冷兼容,保障稳定量产;英特尔依托18A制程推出至强6+CPU与Crescent Island低功耗推理GPU,凭借EMIB封装控制成本,深耕高密度推理场景;AMD MI455X机柜方案主打性价比,依托安靠封装产能,精准覆盖中高端训练需求。
此外,为降低对外购高端GPU的依赖,谷歌、亚马逊等头部云厂商持续扩容自研ASIC算力集群,完善自主算力供给体系。路透社援引The Information消息,谷歌已向英特尔下达超300万颗TPU芯片的代工订单,预计2027年落地的TPU v8e将搭载英特尔EMIB封装技术;亚马逊持续扩大Inferentia、Trainium自研芯片部署规模,全面承接平台内部推理业务。
液冷,从“选择题”变成“必答题”
算力硬件功耗持续攀升,传统机房的风冷散热、低压供电架构,已无法承载新一代超高功率AI设备的运行负荷。散热与供电改造不再是可选的优化项,而是新建算力项目落地的重要前提,液冷正式成为AI数据中心的标配基建。
2026年4月供应链信息显示,谷歌大幅上调本年度自研TPU芯片出货目标至600万颗,其新一代高性能TPU单芯片功耗高达980W。针对超高热密度痛点,谷歌在2026年5月的Google Cloud Next'26大会上明确,全新AI超算全面采用定制化液冷架构,配套自研第四代CDU冷量分配单元,近千瓦级的芯片功耗,让液冷成为该类芯片量产落地的必备条件。
2026年3月GTC大会上,英伟达推出Vera Rubin全液冷算力平台,全系芯片与机架产品彻底取消风冷配置。该平台在研发阶段便以液冷为基础设计标准,机柜布局、管路走向均围绕散热需求定制,单台整机柜最高功耗可达200kW。刚落幕的COMPUTEX 2026展会上,仁宝、华擎等头部服务器厂商,集中展出基于Vera Rubin打造的机柜级AI基础设施。
全球头部算力项目已全面落地液冷架构,规模化商用案例持续落地。
海外方面,xAI于2026年1月官宣Colossus 2投入运行,成为全球首个吉瓦级AI训练集群。该集群以数十万片英伟达GB200 GPU为核心,采用Supermicro定制的芯片级直接液冷(D2C)方案,依托冷板液冷架构支撑超高密度算力持续稳定运行,满足超大模型训练的高负载需求。
中国企业的液冷技术出海与本土落地双线提速,政企、云厂商智算中心改造全面铺开。
优刻得与超云联合定制的R8428 I13浸没式液冷整机,已在乌兰察布智算中心规模化上架。该设备在4U空间内支持8张高性能GPU,可将机房PUE降至1.1以下,适配高密度AI需求。曙光数创承接的马来西亚61MW大型冷板液冷数据中心项目已于2026年一季度完工投产。
与此同时,鸿海、仁宝、华擎等大厂加速推出液冷整机柜方案:鸿海实现GB200/GB300 NVL72机柜量产,仁宝与华擎全面完成英伟达新一代Blackwell及Rubin平台的液冷适配,支撑超高功耗服务器的规模化部署。
算力需求激增
整机厂商订单爆发
全球算力基建投入迎来高峰期,海外亚马逊、微软、谷歌、Meta等头部科技企业2026年资本开支大幅增长,资金重点倾斜AI服务器采购、高速互连升级、算力机房改造等核心领域。
国内市场同步发力,字节、阿里、腾讯、百度等互联网大厂持续上调AI基础设施投资预算,全力适配大模型训练、产业AI赋能、云端智能交互等多元场景的算力增量需求,为整机厂商提供了充足且持续的订单支撑。
大规模资本开支落地,兑现为整机厂商的亮眼业绩与海量在手订单。
戴尔2027财年Q1业绩显示,AI优化服务器单季收入161亿美元,同比暴涨757%,当期新增AI订单244亿美元,在手积压订单高达513亿美元。同时,戴尔将全年AI服务器专项收入目标提升至600亿美元。

HPE深耕超算与主权级算力集群赛道,深度绑定英伟达,陆续拿下加拿大TELUS算力中心、新西兰2degrees、欧美多家政府科研机构的国家级AI超算项目。
国内整机厂商同样迎来高速增长,牢牢守住本土市场基本盘。
联想最新财报数据显示,公司AI服务器营收迎来高双位数增长,截至2026年一季度末,AI服务器订单储备超1400亿元,在手订单充足,产能持续满负荷运转。
华为于2026年3月正式推出并量产昇腾950PR处理器与Atlas 350 AI加速卡,标志着新一代代际推理算力进入规模商用,在互联网高并发等推理场景下性能优势突出。
浪潮则依托天池液冷基地等本土产能优势,持续为阿里、腾讯、字节等互联网大厂提供专属定制化整机解决方案。
当前行业技术竞争维度持续升级,头部厂商普遍通过液冷适配、高速互连技术构筑壁垒。针对新一代超高功耗算力设备,戴尔、联想、浪潮等企业迭代优化整机柜液冷方案,适配200kW高密机柜散热需求,有效降低机房PUE。
同时全面普及NVLink、PCIe 5.0、硅光高速互连技术,降低传输延迟、提升集群通信能力。软硬件一体化的定制交付能力,逐渐成为厂商拿下大额订单的核心竞争力。
结 语
综合来看,2026年AI服务器行业的竞争逻辑悄然改变。上游HBM、先进封装等零部件产能形成硬性约束,液冷成为算力基建标配,叠加市场需求从训练向推理倾斜,行业不再依靠单一硬件资源取胜。海内外厂商依托自身优势划分赛道,整体市场仍保持增长态势,后续发展将更多取决于供应链把控、产品适配能力与落地服务水平。
6.23(周二)
TSS2026
2026年6月23日,TrendForce集邦咨询将在深圳举办“TSS2026半导体产业高层论坛”。
届时,集邦咨询资深分研究经理龚明德将针对AI服务器产业现状与未来发展趋势发表精彩演讲,敬请期待。




最近微信改版
经常有读者朋友错过推送
星标🌟“全球半导体观察”
及时接收最新最热的推文













