点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
星球内有20多门3D视觉系统课程、3DGS独家系列视频教程、顶会论文最新解读、海量3D视觉行业源码、项目承接、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎加入!
论文信息
标题:LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding
作者:Shihao Wang1、Shilong Liu、Yuanguo Kuang、Xinyu Wei、Yangzhou Liu、Zhiqi Li, Yunze Man、Guo Chen、Andrew Tao、Guilin Liu、Jan Kautz、Lei Zhang、Zhiding Yu
机构:The Hong Kong Polytechnic University、Princeton University、 Nanjing University、University of Illinois Urbana-Champaign
原文链接:https://research.nvidia.com/labs/lpr/locate-anything/LocateAnything.pdf
代码链接:https://github.com/NVlabs/Eagle/tree/main/Embodied
导读
视觉-语言模型(Vision-language models, VLMs)通常将视觉定位和检测问题形式化为坐标标记生成任务,即将每个二维边界框序列化为多个一维标记,这些标记的学习和解码在很大程度上是相互独立的。这种逐标记解码方式与边界框几何结构的耦合特性不匹配,并且由于严格的顺序生成,造成了实际推理中的瓶颈。我们提出了 LocateAnything,一个基于并行框解码(Parallel Box Decoding, PBD)的统一生成式定位与检测框架。通过将边界框和点等几何元素作为原子单元一步解码,LocateAnything 保持了框内几何一致性,并释放了显著的并行能力。我们发现 PBD 同时提高了解码吞吐量和定位精度。我们进一步开发了一个可扩展的数据引擎,并精心构建了 LocateAnything-Data,一个包含超过 1.38 亿训练样本的大规模数据集,大幅增加了高精度定位所需的数据多样性。大量评估表明,LocateAnything 推进了速度-精度的前沿,在多个基准测试中实现了显著更高的解码吞吐量,同时提升了高 IoU 定位质量。这些结果凸显了并行框解码与大规模训练数据在实现高效、精准的统一视觉定位与检测方面的互补优势。
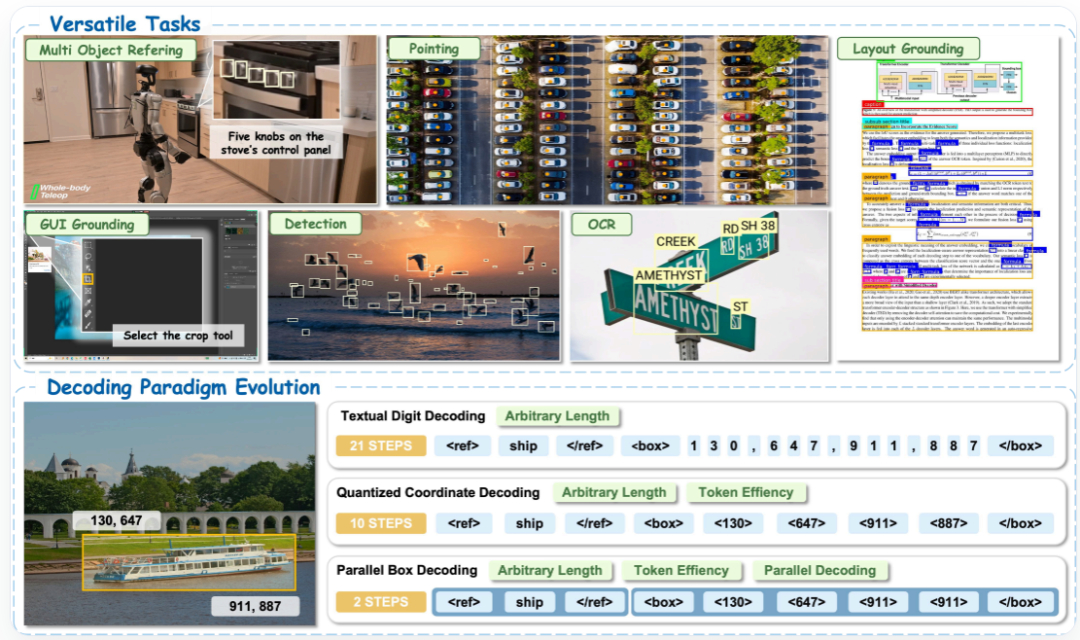
效果展示
LocateAnything能够在统一的视觉语言模型下完成多种定位任务,包括文档理解、用户界面元素定位、密集物体检测以及光学字符识别等功能。

并行边界框解码法与量化坐标解码法的比较。并行边界框解码法能够在单次处理过程中单独预测每个边界框的信息,从而显著提升解码效率。

上图:LocateAnything能够在统一的视觉语言模型下处理多种定位任务。下图:文本数字解码与量化坐标解码能够依次预测出各个坐标值。而并行框解码则能在单次计算过程中预测出每个几何单元的坐标信息。
引言
视觉-语言模型因其相比传统专用模型具有更广泛的知识和更强的指令跟随能力,正越来越多地被用作交互式和具身系统的通用骨干。为了在现实世界中行动,VLM 必须紧密地扎根于感知——尤其需要根据自然语言意图,以高质量和低延迟的方式定位与任务相关的实体(例如物体、UI 元素、区域),这要求模型具备强大的视觉-语言定位能力。
VLM 中的目标检测和定位通常被形式化为生成问题。在下一标记预测(NTP)范式下,VLM 可以通过输出空间坐标的标记序列来回答开放式查询。如图 1 底部所示,现有方法通常将坐标表示为文本数字或量化标记。尽管表示方式不同,这些表示都将二维几何物体序列化为一维流,迫使推理时逐标记生成。这种标记级的顺序解码成为实际瓶颈(更高的延迟和更低的吞吐量),并且未能充分利用坐标之间的强结构化相关性。

多标记预测(MTP)提供了一种自然的减少解码步骤的方法,即并行预测多个标记。在语言建模中,MTP 通常通过随机选择序列中的位置并训练模型并行预测后续跨度,或者掩盖序列中的部分标记并训练模型重建原始文本来实现。然而,这些方法在很大程度上是与结构无关的:它们将输入视为通用标记流,主要捕捉由共现驱动的相关性。从随机子集中推断缺失标记要求模型表示复杂且不规律的条件分布。对于边界框这种紧密耦合的单元,这种监督与训练目标并不匹配,因为模型可能会学习生成跨越边界框边界甚至物体类别的标记组合,如图 2 所示。因此,模型必须拟合许多不可靠的模式,引入虚假相关性,牺牲结构化解码,并放大错误传播,从而共同降低准确性、可靠性和解码速度。
为了协调高吞吐量解码与可靠的定位,我们提出了 LocateAnything,一个基于并行框解码(PBD)的、用于基于 VLM 的视觉检测与定位的统一框架。我们的核心思想是将 MTP 块与结构化单元对齐:在训练期间,LocateAnything 将每个边界框(或点)视为一个原子单元,并学习在一个并行步骤中预测完整的坐标集。这种与框对齐的训练目标避免了坐标标记的任意分块。因此,我们的策略提高了模型的定位性能,同时释放了并行解码的速度优势。
借助所提出的 PBD,我们研究了多种结构化的边界框解码策略,以平衡吞吐量和准确性。我们的观察启发了一个灵活的推理设计,通过提供三种按需模式来满足不同的延迟-鲁棒性需求:(i)快速模式(MTP)并行预测完整的边界框以获得最大吞吐量,适用于延迟和计算受限的环境,如端侧机器人和具身智能体。(ii)慢速模式(NTP)自回归地解码坐标标记以获得最大稳定性,适用于高精度标注、最终数据集的整理以及面向准确性的离线评估。(iii)混合模式默认使用快速模式,当并行输出不可靠时(例如由于格式或一致性违反)回退到慢速模式;该模式适用于需要同时兼顾速度和准确性的生产流水线。总体而言,混合模式保留了并行解码的大部分速度优势,同时保持了鲁棒的输出。

主要贡献
我们的主要贡献总结如下:
• 我们提出了 LocateAnything,首次探索通过并行框解码将多标记预测应用于基于 VLM 的检测/定位,通过框对齐解码提高吞吐量和准确性。
• 我们提出了一种混合解码策略,能够检测不可靠的并行块,并仅对有问题的块进行局部的 NTP 重解码,从而在保留大部分速度提升的同时减少最坏情况下的失败。
• 包括布局定位、长尾检测和 GUI 定位在内的大量评估表明,LocateAnything 推进了速度-精度的前沿,大幅超越现有最佳模型,在提升定位质量的同时实现了高达 2.5 倍的解码吞吐量提升。
方法
如图 3 所示,LocateAnything 建立在预训练于大规模图文语料的原生分辨率 VLM 之上。其架构包括一个 Moon-ViT 视觉编码器和一个 Qwen2.5 语言解码器,两者通过 MLP 投影器连接。给定输入图像,视觉编码器以原生分辨率提取视觉标记,保留了高精度定位所必需的细粒度空间细节。这些标记随后被输入语言模型,后者直接将其转换为一系列与框对齐的块级预测。

实验结果
高质量多目标检测。我们的模型在常见和复杂的密集目标检测场景中都表现出鲁棒的泛化能力。在表 1 报告的一般检测基准上,尽管模型大小相同,LocateAnything 相比 Rex-Omni 在 LVIS 上平均 F1 提升了 3.8%,在 COCO 上提升了 1.8%。关键的是,模型有效地学习了广义的空间分布,将其检测能力迁移到未见过的、高度密集的物体类型上。表 2 中的密集检测基准证明了这一点:在 VisDrone 上达到 39.9 的平均 F1,显著优于 Rex-Omni 的 35.8;类似地,在 Dense200 上达到 58.7 的竞争性平均 F1,展示了在高度重叠环境中优越的边界描绘和实例分离能力。


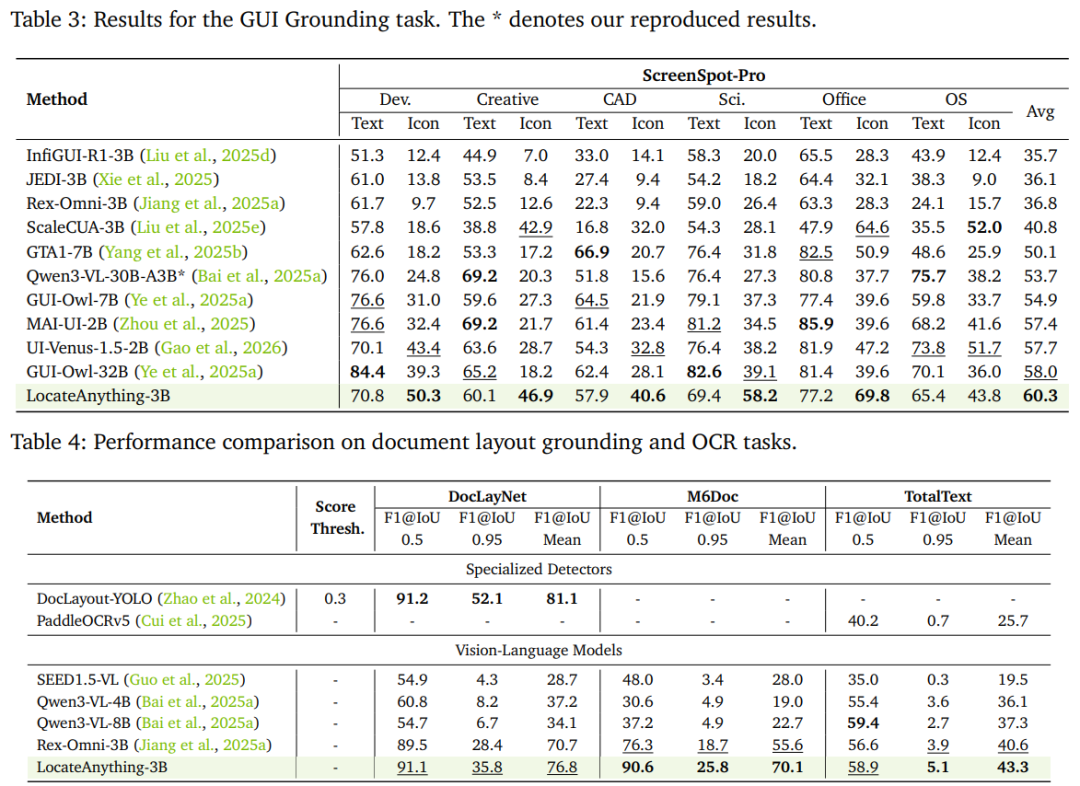
精确的开放世界定位能力。LocateAnything 在多个开放世界基准测试中展现出卓越的细粒度定位能力,包括用户界面定位、文档布局解析和指代表达式理解。如表 3 所示,在 ScreenSpot-Pro 上,它达到了 60.3 的平均 F1,超越了通用 VLM 如 Qwen3-VL-30B-A3B 以及专门针对 UI 任务的模型如 GUI-Owl-32B。此外,在表 4 详述的文档理解任务中,LocateAnything 在 DocLayNet 和 M6Doc 上分别达到 76.8 和 70.1 的平均 F1,显著优于 Rex-Omni,树立了新的标准。这种精确的空间推理扩展到了复杂的指代任务,如表 5 所示,模型能够无缝地将细腻的人类意图与视觉区域对齐,在 HumanRef 基准上达到 78.7 的平均 F1,并在 RefCOCOg 上与顶级模型保持高度竞争性。
卓越的解码速度。我们模型的一个关键优势是其显著减少的解码步骤。如表 1 所示,在默认的混合模式下,我们的模型达到 12.7 BPS,比基于文本的 Qwen3-VL(1.1 BPS)快 10 倍以上,比基于量化的 Rex-Omni(5.0 BPS)快 2.5 倍。
总结 & 局限性
我们提出了 LocateAnything,一个通过并行框解码重新定义 VLM 中视觉定位与检测的统一框架。通过将几何元素提升为原子单元而非一维流,LocateAnything 使训练监督与空间坐标固有的耦合特性对齐。借助海量的 1.38 亿图文训练查询和灵活的按需推理机制,LocateAnything 不仅在多种任务上达到了最先进的精度,而且相比竞争方法实现了高达 2.5 倍的加速。我们的方法为实时视觉感知提供了一条实用且可扩展的路径,为在延迟敏感的具身机器人和交互式智能体中部署通用 VLM 打开了大门。
局限性。目前,我们的模型主要使用监督微调进行训练。强化学习是重要的下一步,旨在进一步优化块级解码策略、减少回退频率,并促进在困难/密集/长尾案例中的有效探索,这可以同时提高鲁棒性和最坏情况下的解码速度。我们将此留待未来工作。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。
。




添加微信:cv3d001,备注:姓名+方向+单位,邀请入群。