最近几天,一个 3B 的小模型在 X 上火了,因为在一些难度可验证的推理任务上(比如编程),它进入了 Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5 等前沿模型的性能区间,而它的体积远小于这些模型。

这个模型名叫 VibeThinker-3B,是一个拥有 30 亿参数的密集推理模型,旨在探索在严格的小模型规模下,可验证推理能力能被推进到何种程度。
模型发布后,很多人都被它的成绩惊艳到了,表示要上手一试。


值得注意的是,它还是一个国产模型,来自新浪微博团队。

技术报告显示,该模型专为具有可靠验证信号的任务而设计,包括数学推理、竞技编程、STEM 推理以及带有明确约束的指令执行。
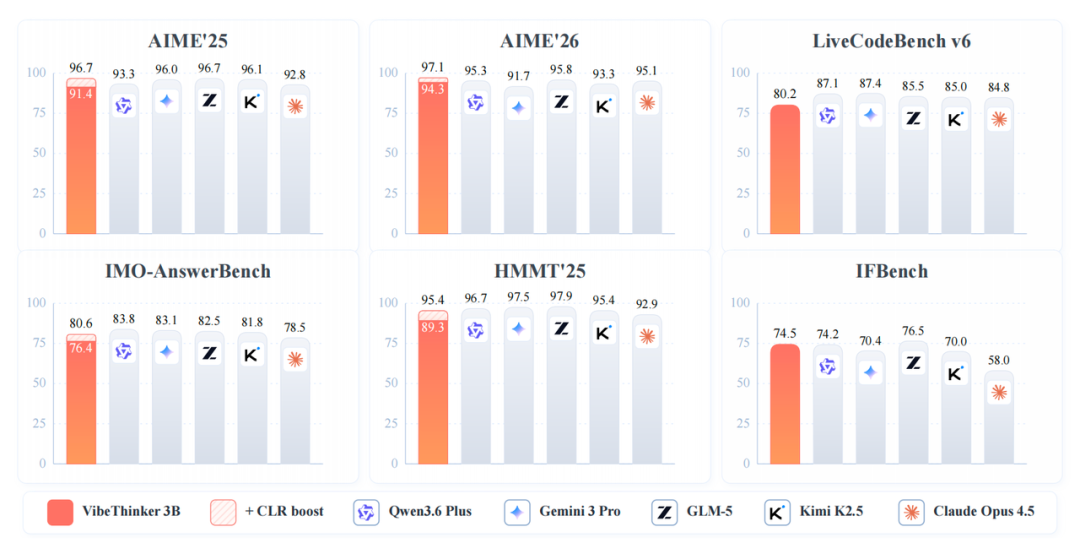
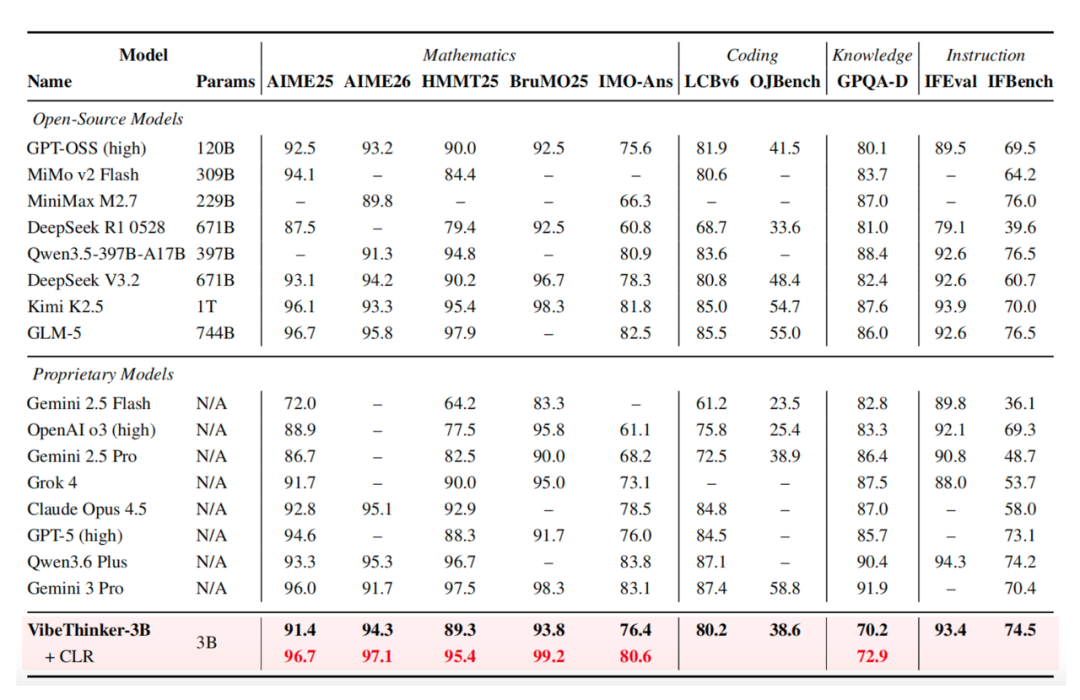
因此,它在各项基准测试中均表现出色 。其在 AIME26 测试中获得 94.3 分 ,在 HMMT25 测试中获得 89.3 分 ,在 LiveCodeBench v6 测试中获得 80.2 分(Pass@1),并且在 2026 年 4 月 25 日至 5 月 31 日期间 LeetCode 最新未公开的周赛和双周赛中取得了 96.1% 的通过率。
这个模型是怎么训练的?技术报告揭示了一些细节。
首先,它基于 Qwen2.5-Coder-3B 构建,并采用升级版 Spectrum-to-Signal 流程进行后训练。该流程在监督微调(SFT)中加强了数据合成、质量过滤和课程学习,将 MGPO 风格的强化学习扩展到多个可验证领域,保留了完整的长上下文推理轨迹,并通过离线自蒸馏和指令强化学习(Instruct RL)来巩固各项能力。

VibeThinker-3B 整体训练流程

Spectrum-to-Signal 流程。
此外,VibeThinker-3B 还引入了 Claim-Level 可靠性评估(CLR),这是一种面向答案可验证推理的测试时 scaling 策略。CLR 进一步提升了数学基准测试的性能,将 AIME26 从 94.3 提高到 97.1,HMMT25 从 89.3 提高到 95.4,并将 BruMO25 提升至 99.2。
其具体训练流程如下:
基于课程的两阶段 SFT。第一阶段侧重于数学、编程、STEM 推理、一般对话和指令遵循等方面的广泛能力覆盖。第二阶段转向难度更高、视野更广阔的推理样本。多样性探索蒸馏用于保留多个有效的解决方案路径。
多领域推理强化学习。VibeThinker-3B 重用了 MGPO。强化学习依次应用于数学、编程和 STEM 推理任务。训练使用单个 64K 长上下文窗口来保留完整的长时域推理轨迹。
离线自蒸馏。从数学、编程和 STEM RL 检查点筛选和提炼高质量轨迹,最终形成统一的学生模型。学习潜力评分用于优先考虑那些正确但学生尚未很好地模仿的轨迹。
Instruct RL。最后阶段提高了面向用户的提示的可控性。对于格式敏感且开放式的教学数据,采用基于规则的验证器和基于评分标准的奖励模型。
在最近的一个帖子中,知名 AI 研究者和博主 Sebastian Raschka 系统总结了 VibeThinker-3B 技术报告中披露的要点,包括以下几条:

如果你对这些内容感兴趣,可以去详细翻阅他们的技术报告。目前,模型也是可以公开下载的。

报告标题:VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
报告链接:https://arxiv.org/pdf/2606.16140
HuggingFace 链接:https://huggingface.co/WeiboAI/VibeThinker-3B
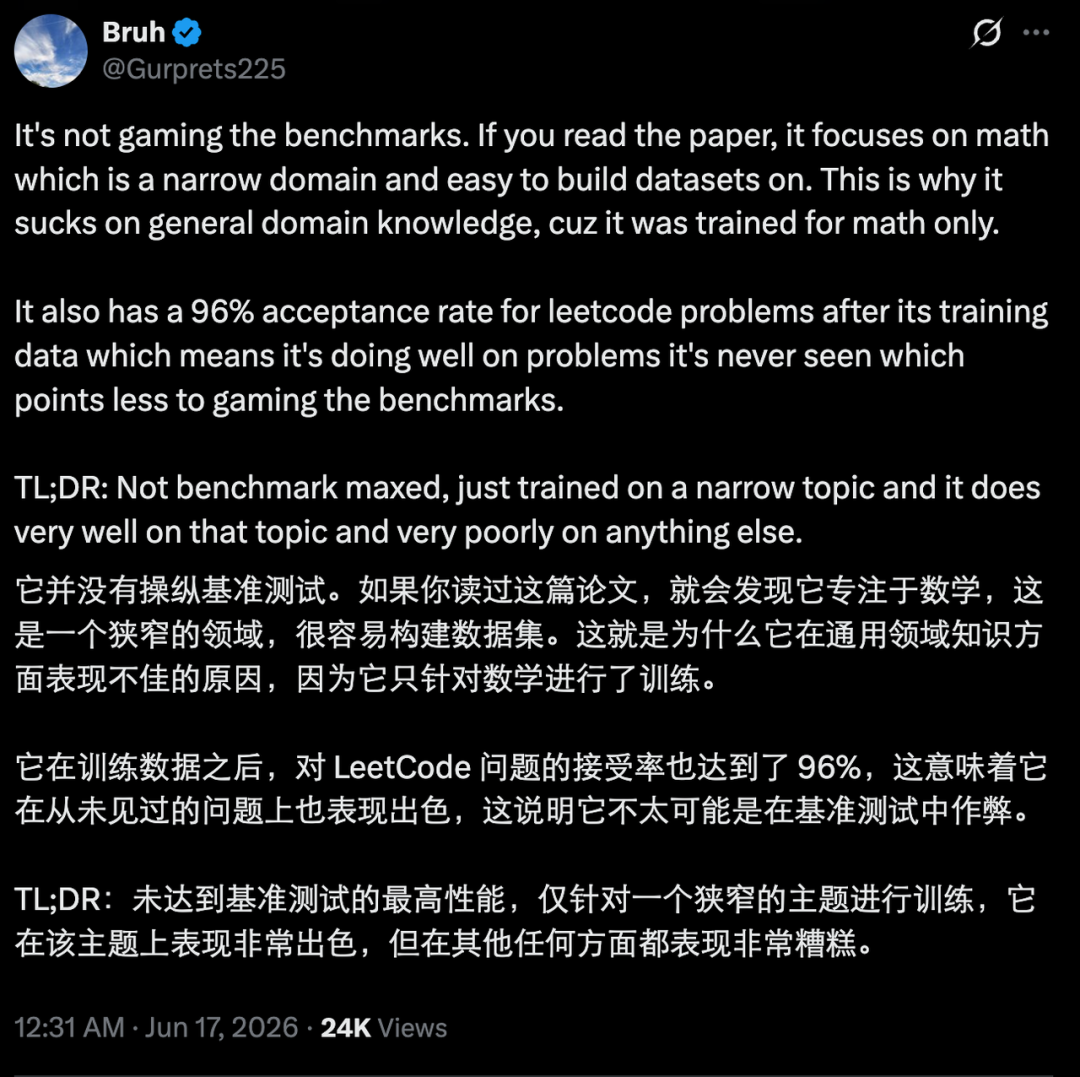
不过,该模型的适用范围是有明确限制的,因为它在需要通用知识的领域表现并不出色。

官方也明确指出了这一点,并提出「参数压缩覆盖假设」:不同的能力对模型参数的依赖方式截然不同。可验证推理更接近于一种高度可压缩、参数密集的能力,其核心在于多步骤推理、约束满足、自我纠错和答案验证。当任务空间结构足够清晰且反馈信号足够可靠时,紧凑型模型也可能具备接近前沿的推理能力。相比之下,开放领域知识、通用对话和长尾场景理解则更依赖于大规模参数来广泛覆盖事实、概念和世界知识。这一假设非常具有启发性。VentureBeat 在报道中写道:「它揭示了推理能力和事实知识之间存在部分解耦,并且前者可以比之前设想的更有效地压缩 —— 这一洞见对业界如何看待模型设计、部署成本以及高级人工智能功能的普及性都具有深远的影响。」

作者表示,他们的目标并非打造一个替代大规模模型的小模型,而是沿着特定能力维度,审视小模型的真实边界。借助 VibeThinker-3B,他们希望表明,小模型不应仅仅被视为降低部署成本的妥协方案。在具有清晰反馈与验证机制的能力领域中,小型语言模型正展现出一条颇具前景的研究路径,有望实现前沿水平的性能,并与传统的参数规模扩展范式形成根本性的互补关系。
目前,该模型在社区中还面临一些质疑。如果大家对这个模型感兴趣,不妨自己去亲自试一下。

参考链接:https://x.com/orcus108/status/2066876960073281582

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com