点击下方卡片,关注“具身智能之心”公众号
作者丨Juncheng Ma 等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
>>
更多干货,欢迎加入国内首个具身智能全栈学习社区:(戳我),这里包含所有你想要的。
具身基础模型发展的一条主线,是将语言模型和视觉模型已经验证过的 scaling 逻辑搬到机器人上。但问题也同样明确:语言和视觉可以直接利用互联网数据,机器人预训练却长期依赖遥操作真实机器人轨迹。后者当然有一个天然优势:动作监督精确,观测和执行空间与部署形态直接对齐。可一旦进入预训练阶段,这种优势并不足以自动转化为更强的泛化,因为它同时伴随着高采集成本、低数据供给和受限的环境覆盖。
围绕这个问题,过去的工作大致沿着三条路线推进。
第一条路线,是继续把真实机器人数据做大。Open X-Embodiment、RT-1/RT-2、DROID、pi0、GR00T、AgiBot World 这类工作都在沿着这个方向扩展数据规模、任务种类和 embodiment 数量。
这条路线的长处在于动作空间对齐得很好,短板也很清楚:数据采集受机器人平台、操作员、场地和预算约束,背景、物体和交互模式都很容易趋于同质化。
第二条路线,是把第一视角人类视频作为具身学习的预训练来源。EgoMimic、EgoScale、Being-H0、HumanEgo 等工作已经说明,人类第一视角数据即便没有原生机器人动作,也能通过手部重定向、跨 embodiment 蒸馏或下游策略学习提供有价值的先验。不过这条路线此前更多是在证明“可用”,还没有把它和真实机器人预训练放到同一把尺子下做同规模正面对比。
第三条路线,是在架构层面区分 VLA 和 WAM。前者把动作头接到视觉语言骨干上,后者联合建模未来状态与动作,把视频预测作为更密集的训练信号。这篇论文选用的是 WAM 路线,原因并不复杂:作者想尽量固定模型形态,把变量压缩到预训练数据这一点上。
如果预训练阶段最稀缺的不是动作对齐,而是开放世界覆盖,那么第一视角人类视频未必只是机器人数据不足时的替代品,它可能本来就是更好的预训练数据来源。
为了验证这个判断,近日一篇名为HumanScale的工作做了一组实验:同样的模型、同样的预训练时长、同样的后训练数据、同样的验证协议,只替换预训练数据源,最后直接比较哪一种先验更能转移到真实机器人任务上。
论文标题:HumanScale: Egocentric Human Video Can Outperform Real-Robot Data for Embodied Pretraining
论文链接:https://arxiv.org/abs/2606.20521
代码:https://github.com/DAGroup-PKU/HumanNet/

01.
预训练阶段更需要 coverage,后训练阶段才主要修正 embodiment alignment
预训练和后训练到底需要什么数据?HumanScale认为,预训练关注的是 coverage,也就是场景、物体、交互方式和行为分布够不够广;后训练关注的是 alignment,也就是观测、动作和目标 embodiment 是否对齐。顺着这个划分再回看真实机器人数据和第一视角人类视频,两者的角色其实并不相同。
第一,accessible scale 有量级差。HumanScale给出的判断是,公开真实机器人数据即便把多个数据集聚合起来,总量也大约只有 小时;而 HumanNet 这类第一视角人类视频语料本身就有一百万小时,其中超过 80 万小时是第一视角数据。论文实际只从中抽取了 5000 小时做预训练子集,这个规模本身就已经超过大多数开源遥操作数据集。
第二,采集成本和扩张逻辑完全不同。真实机器人数据需要机器人本体、遥操作设备、人工操作员、布置好的环境以及维护成本。HumanScale举的例子是,即便是较低成本的 ALOHA 平台,单个站点也要约 2 万美元。第一视角视频的新增一小时则便宜得多,因为它可以来自现成头戴设备,也可以来自网页抓取。真正昂贵的部分转移到了过滤、去重、隐私审查和伪动作标注上,但这些更接近一次性的自动化计算成本。
第三,数据的“边际新信息量”差别很大。HumanScale没有只比较总时长,而是从两边的 5000 小时池子里各自随机抽取约 2 小时样本,比较运动质量、空间覆盖、跨 session 方差、交互词汇和视觉场景覆盖。结论很一致:第一视角人类视频更平滑、idle time 更少,活动范围更广,跨示例位置变化更大,verb-object 交互长尾更明显,视觉场景也远比实验室内采集的机器人轨迹丰富。

第四,真实机器人数据的局限不是偶然现象,而是结构性结果。固定工作台、有限物体集、脚本化任务和实验室背景会自然压缩数据分布。作者在这里的判断很明确:如果预训练阶段想学习的是可迁移世界表示,那么“更像部署机器人”并不足以弥补“看过的世界太窄”。
这个结论也解释了为什么HumanScale没有把机器人数据一概否定。反而给出了一种很清楚的分工:第一视角人类视频负责在预训练中提供开放世界覆盖,少量真实机器人数据负责在后训练阶段补上动作空间与 embodiment 对齐。HumanScale真正要验证的经验问题因此变成了:当预训练时长相同,前者的多样性优势能否压过后者的运动学对齐优势。
02.
把两种数据源放到同一把尺子下
从方法上看,HumanScale 更像一套严格的 controlled study,而不是一篇依靠新训练目标取胜的模型论文。作者使用同一个自回归 world-action model,骨干是 Mixture-of-Transformers 架构。video expert 从 Wan 2.2 初始化,action expert 通过插值得到初始化。这个模型同时建模未来视频观测和后续动作,目的是让视频动力学预测为动作学习提供更密集的监督。
这里有一个很重要的边界需要说明。本工作并没有展开 WAM 内部训练损失的完整公式,论文的技术重点也不在提出新的 flow matching 目标或新的动作头设计。因此这篇解读里没有必要硬把不存在的公式补出来。HumanScale真正想控制的是实验变量,而不是强调某个新 loss 带来的收益。
整个对比设计分成三个阶段。
第一阶段是预训练数据。HumanScale构造了两个时长完全匹配的 5000 小时预训练集。第一视角数据来自 HumanNet 的第一视角部分,借助手部姿态重定向,估计每个片段的末端执行器位姿和夹爪状态,作为伪动作标签。真实机器人数据则来自多个数据集聚合得到的多 embodiment 轨迹,带有精确的末端位姿与夹爪动作监督。
第二阶段是后训练数据。从 AgiBot World 中挑选了 15 个操作任务,每个任务 100 条专家演示,一共 1500 条轨迹。这个阶段的数据与两边预训练集都不重合,用来把预训练得到的先验适配到目标机器人任务上。
第三阶段是评测协议。使用 held-out 的 Stage-2 机器人数据验证 action loss,并切出 Seen 和 Unseen 两组评测。Seen 是 15 个后训练任务中的保留轨迹,主要测任务内鲁棒性;Unseen 则是 25 个未在后训练中出现过的任务,作为主要的 OOD 泛化评测。
这套设计的价值在于,它把最容易混淆的几个因素尽量剥离开了。模型架构固定,后训练数据固定,验证协议固定,预训练总时长固定。这样一来,最后看到的差异更有资格被解释为“预训练数据源本身的差异”。
还有一个容易被忽视的细节。HumanScale特意让真实机器人预训练任务与后训练任务、Unseen 评测任务保持互斥,并且随着真实机器人数据规模扩大也维持这种隔离。这个控制很关键,因为它避免了“机器人数据做大以后恰好更接近测试题”这种泄漏式收益。
03.
第一视角人类视频出现了清晰 scaling,而真实机器人预训练在 unseen tasks 上更早饱和
这篇论文最核心的结果有两层。第一层是第一视角预训练本身是否成立 scaling。第二层是它和真实机器人预训练相比,到底谁更能带来泛化。
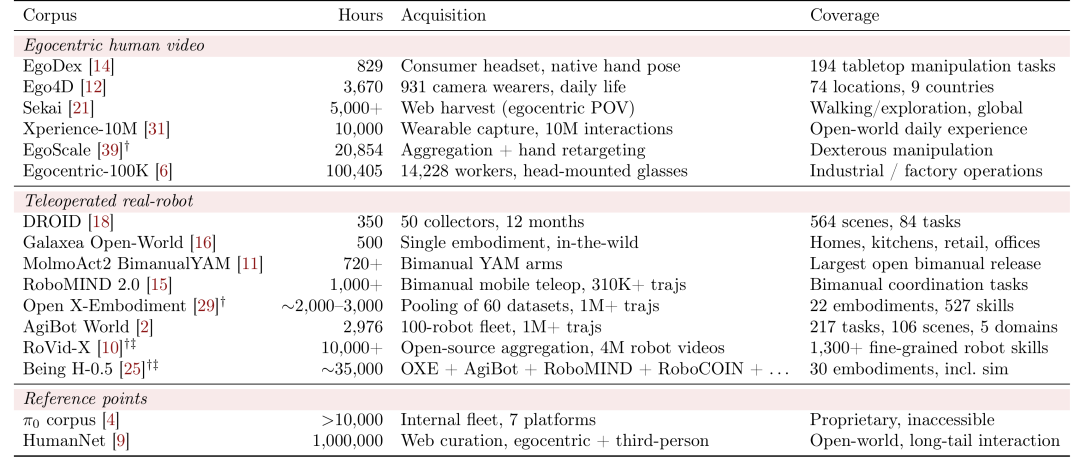
先看第一层。随着第一视角预训练数据从 100 小时增加到 5000 小时,最优后训练 action loss 在 Seen 和 Unseen 上都单调下降。Seen 从 0.0080 降到 0.0067,Unseen 从 0.0234 降到 0.0204。相对于没有 embodied pretraining 的 Wan 2.2 基线,降幅分别是 35% 和 24%。作者进一步用一条对数线性规律去拟合这条曲线:
这里 表示后训练阶段能达到的最佳验证 action loss, 表示预训练数据小时数, 是拟合截距,代表数据规模很小时的损失基线, 是 scaling 斜率,对应每增加一倍左右数据时损失下降的幅度。式子里的 说明作者观察到的收益更接近“对数递减但仍持续改善”,而不是线性下降。Seen 的拟合 为 0.86,Unseen 的 为 0.94,说明这条经验规律在实验范围内是比较稳定的。更重要的是,直到 5000 小时这条曲线的斜率仍然显著为负,也就是还没有看到明显饱和。
再看第二层,也就是最关键的同规模正面对比。在 Seen 任务上,两类预训练其实差距不算夸张。5000 小时时,第一视角预训练的 loss 是 0.0067,真实机器人预训练是 0.0071。前者更好,但两者都能帮助任务内泛化。
真正拉开差距的是 Unseen。5000 小时时,第一视角预训练的 loss 降到 0.0204,而真实机器人预训练仍停留在 0.0254 左右,差距接近 20%。作者对此的解释也相当直接:真实机器人数据的运动学对齐优势在 Seen 任务里有用,但当任务语义、交互物体和场景分布真正超出后训练范围时,开放世界覆盖不足的问题就会暴露出来。
这部分分析里还有两点值得单独拎出来。
第一点,是单位小时的信息密度差异。作者给出一个很具体的数字:在 100 小时设定下,第一视角数据大约包含 45000 条轨迹,而真实机器人数据只有约 8000 条。原因是遥操作包含大量 idle 段,机械臂运动也更慢。所以“同样 100 小时”在信息量上其实已经偏向保守地低估了第一视角视频的优势。
第二点,是机器人预训练的 flat curve 本身就很说明问题。HumanScale并没有让真实机器人预训练任务与评测任务重叠,因此它的提升空间只能来自真正的迁移能力。结果这条曲线在 Unseen 上基本不动,说明实验室内采集到的任务分布扩大到一定程度后,并不会自然变成开放世界泛化。

从相关工作的角度看,这个结果回答了一个之前一直没有被正面对齐的问题。过去的真实机器人 scaling 工作已经证明“更多机器人数据有帮助”,过去的第一视角预训练工作也已经证明“人类视频可以迁移到机器人”。
HumanScale 新增的那一步,是在相同模型和相同后训练协议下,直接验证“预训练阶段更广的数据覆盖是否比更强的运动学对齐更重要”。论文给出的答案是肯定的,而且优势主要体现在 OOD 泛化上。
04.
真实机器人执行结果说明,这种先验并没有停留在验证损失层面
这个工作补了一组真实机器人实验,用来回答另一个更严格的问题:这种来自第一视角人类视频的先验,到底有没有真正进入可执行策略,而不只是让验证曲线更好看。
实验平台是 AgiBot 双臂机器人,任务包括把杯子放到杯垫上、分拣水果蔬菜,以及盖章。每个任务都分成 in-distribution 和 out-of-distribution 两种设定,后者会换成后训练中没有见过的物体实例。这里的对比对象不是“第一视角预训练 vs 真实机器人预训练”,而是“第一视角预训练 vs 没有 embodied pretraining 的 Wan 2.2 基线”。这一点需要单独说清,否则很容易把摘要里的数字误解成另外一种比较。
第一视角预训练模型在真实机器人上的平均成功率达到 92.5% 的 in-distribution 和 90.0% 的 out-of-distribution,只下降了 2.5 个点。没有预训练的基线则是 40.0% 和 0.0%,在 OOD 条件下基本完全失效。


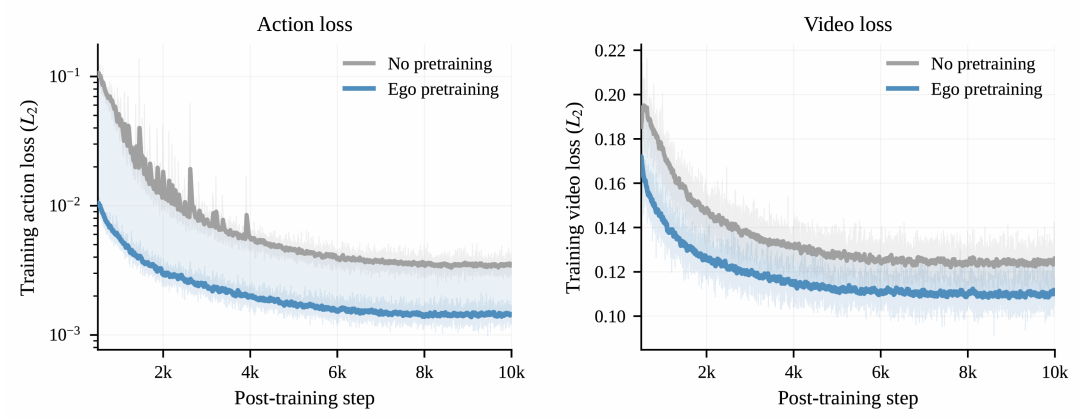
工作还给了一组训练过程证据来支撑这个现象。在水果蔬菜分拣任务上,带有第一视角预训练的模型从后训练一开始就处于更低损失区间,最终 action loss 大约比无预训练基线低 2.4 倍,视频 loss 也更低。这说明预训练带来的收益并不只是测试时“碰巧泛化”,而是从适配阶段开始就已经让策略更容易拟合目标任务。
当然,这组真实机器人实验也有它的边界。它没有把第一视角预训练和真实机器人预训练都部署到同一真实平台上做 head-to-head 执行对比,因此现实世界的执行结论主要支持“第一视角预训练优于无预训练基线”,而不是直接支持“它在真实部署上也必然优于机器人预训练”。这一层区分在阅读摘要时很容易被忽略。
写到最后&总结
HumanScale 聚焦到一个问题上:预训练阶段真正稀缺的到底是动作对齐,还是开放世界覆盖。
答案很鲜明。对于 embodied foundation model,尤其是以 WAM 为代表、希望先学世界表示再做机器人适配的路线,第一视角人类视频并不是次优替代,它很可能更合适用来进行预训练。
在笔者看来,这篇工作最亮眼的地方有两点。第一,它把“coverage 和 alignment 分工不同”这件事从经验判断推进到了定量对比上,而且结论相当干脆:真实机器人数据在 Seen 上还有竞争力,一旦进入 Unseen,第一视角预训练的优势就会迅速拉开。
第二,它提醒了一个很容易被忽视的事实:预训练阶段并不一定要执着于最精确的动作标签。只要后训练还能补上 embodiment alignment,更广泛的行为和场景分布可能反而更有价值。
这篇工作当然还有未完成的部分。作者自己也承认,目前真实机器人数据仍然有限,整套比较停在 5000 小时规模;此外,结论主要建立在 WAM 架构上,是否能原样迁移到 VLA 还需要后续验证。
推荐阅读 :











