点击下方卡片,关注“具身智能之心”公众号
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
>>
更多干货,欢迎加入国内首个具身智能全栈学习社区:(戳我),这里包含所有你想要的。
过去一年,VLA、Diffusion Policy 和大规模遥操作数据,把机器人的初始操作能力推到了一个相当高的水平。
但这些策略一旦走进工厂产线和非结构化场景,行业很快发现,能不能模仿已经不是最难的事,失败之后能不能继续变好,才是真正卡住落地的环节。
这篇文章想讲清楚一个判断:具身智能的下一场竞争,重点不在模型规模,而在真实世界里那条学习闭环转得快不快、稳不稳。
01
从会模仿到会自我变好
模仿学习能让机器人做对很多事。VLA 把语言、视觉和动作放进同一个模型,Diffusion Policy 让多模态动作分布变得可学,大规模遥操作提供了海量专家轨迹。麻烦在于,离线数据只能覆盖过去出现过的状态。
拿插内存条这种活儿来说,演示里全是对得整整齐齐的样片,真到了线上,金手指偏了一点、卡扣多出一点阻力,这些细节演示里没出现过,策略就僵在那儿,既插不进去,也不知道退回来重试。真实世界里的连续接触、装配偏差、动态遮挡,还有长时序任务里一点点累积的失败,大多落在演示分布之外。这种做错之后把自己救回来的能力,离线数据给不了,只能靠真机交互和在线学习补上。
NVIDIA 最近的 ENPIRE 是一个很有代表性的信号。它真正的价值不在于又刷新了哪个任务的成功率,而在于把真实机器人学习整理成一个可以被 agent 驱动、不断自我改进的闭环:场景自动复位,机器人执行策略,系统自动验证结果,coding agent 再根据日志、视频和失败案例去改训练代码、调算法、提假设,回到真机上验证哪条改动真正有效。reset、execute、verify、refine 反复跑,真实世界里的策略改进,就有了一套能自己转起来的范式。
ENPIRE 让人看到的是一个更大的趋势:真实世界里的机器人学习,正在变成一个由 agent 驱动、能自我改进的闭环。把同样的视角挪到 human-in-the-loop RL(HiL-RL)上,会发现一个还没怎么被这股力量触及的环节,就是人本身仍然坐在回路里。
在 HiL-RL 中,一个人要不停判断机器人这一下值不值得学,以及它卡住的时候该怎么把它拽回来,这两件事至今主要靠人。于是一个自然的问题是:HiL 这个回路本身,能不能也朝更自驱、更 agentic 的方向走一步,自己挑该学的数据,自己决定何时出手。拆开来,就是两个问题。
第一,哪些真实交互的数据值得学。机器人真去试、真去失败拿到的数据,并不天然有价值。重复的、走捷径的、信息量极低的样本,可能拖慢学习,甚至让策略提前塌缩。
第二,策略在线上跑偏的时候,系统怎么自己把它拉回来。真机 RL 不能永远靠人接管,它得能自己看出正在做无用功,并主动回到更有希望的状态。
近日,南洋理工大学 PINE Lab 围绕真实机器人强化学习这条主线,连续公开了两项工作:E2HiL (RA-L 26),回答的是“哪些真实交互数据值得学”;UniIntervene,回答的是“策略跑偏时系统如何自己判断、自己恢复”。 这两项工作本质上都在推动同一件事:把 HiL-RL 从“人一直盯着训练”,往“系统自己挑数据、自己纠偏”的方向推一步。
02
E2HiL (RA-L 26):哪些真实数据值得学
论文链接:https://ieeexplore.ieee.org/abstract/document/11520247
项目主页:https://e2hil.github.io/
代码:https://github.com/E2HiL/E2HiL-project-a1x
在 human-in-the-loop RL(HiL-RL)里,人类介入的数据通常被当成最金贵的资源。像 HIL-SERL 这类方法,会把人接管时的纠正动作一股脑塞进 replay buffer,因为它们是专家手把手喂出来的,质量看着就比策略自己瞎试的高。E2HiL 想说的是另一件事:一个介入样本值不值得学,关键不在它对不对,而在它对策略探索结构的影响有多大。
这里的探索结构,用 policy entropy 来刻画,可以理解成策略还保留了多少继续尝试别的动作的余地。熵掉得太快,就是 entropy collapse:策略过早认定某条局部路径是答案,再也不去试别的,看着像收敛,其实是把自己锁死在次优解里。问题是,怎么提前知道哪个样本会把熵压垮。
E2HiL 给了一个能逐样本计算的答案。它推导出一个影响函数,把单个样本对策略熵的改变量,近似成一个协方差:

读法是这样:一个样本对熵的拉力,等于它的对数动作概率,和它那个概率加权过的软优势之间的协方差。直觉上,一个动作如果本来概率就高、软优势又大,用它更新就会把熵狠狠往下压,这正是最容易诱发早熟收敛的那类样本;反过来,低概率却高优势的动作会把熵推高,鼓励探索。这个量在训练里以 stop-gradient 的方式算出来,只当一个打分用,不回传梯度。
真正有意思的发现在这一步之后。E2HiL 统计了不同来源样本的协方差幅度,结果是:人类介入样本几乎全部落在高协方差那一头,它们的平均影响幅度比机器人自探索样本高出一个数量级还多。也就是说,让人类介入显得宝贵的那份果断和确定,恰恰也是让它最容易把熵压垮的东西。被当成救命稻草的样本,往往同时是最危险的样本。这一层,是只盯着对不对永远看不到的。
顺着这个发现,E2HiL 不再对所有样本一视同仁,而是按影响幅度做一道带上下界的筛选。它每个 batch 自适应地取影响幅度的分位区间当上下界(论文里用第 5 到第 90 百分位),只保留落在区间内、对熵影响适中的样本:

幅度过大、会让熵骤降的捷径样本,和幅度过小、几乎不动熵的噪声样本,都被指示函数置零,梯度直接抹掉。最后参与更新的,是这样一个只算熵一致样本的 actor 目标:

这套筛选带来的差别,在一个把方块随机摆在两个位置的任务里看得很清楚。HIL-SERL 学会第一个位置之后,熵很快塌掉,策略认定这就是全部答案,再没去碰第二个位置。E2HiL 把那些会引发熵骤降的捷径样本剪掉,熵降得更平缓,学会第一个位置之后还留着足够的探索余地,于是在两万步左右发现了第二个位置,三万多步把它也学会。同一个任务,区别只在于有没有让熵在错误的时机塌掉。
跨 10 个真实操作任务、多种本体和学习框架,E2HiL 把成功率提升了 24.9%,同时把人工介入减少了 9.3%。介入更少、效果反而更好,说明瓶颈从来不在用了多少人类数据,而在有没有把那批真正推动策略、又不至于压垮探索的样本挑出来。
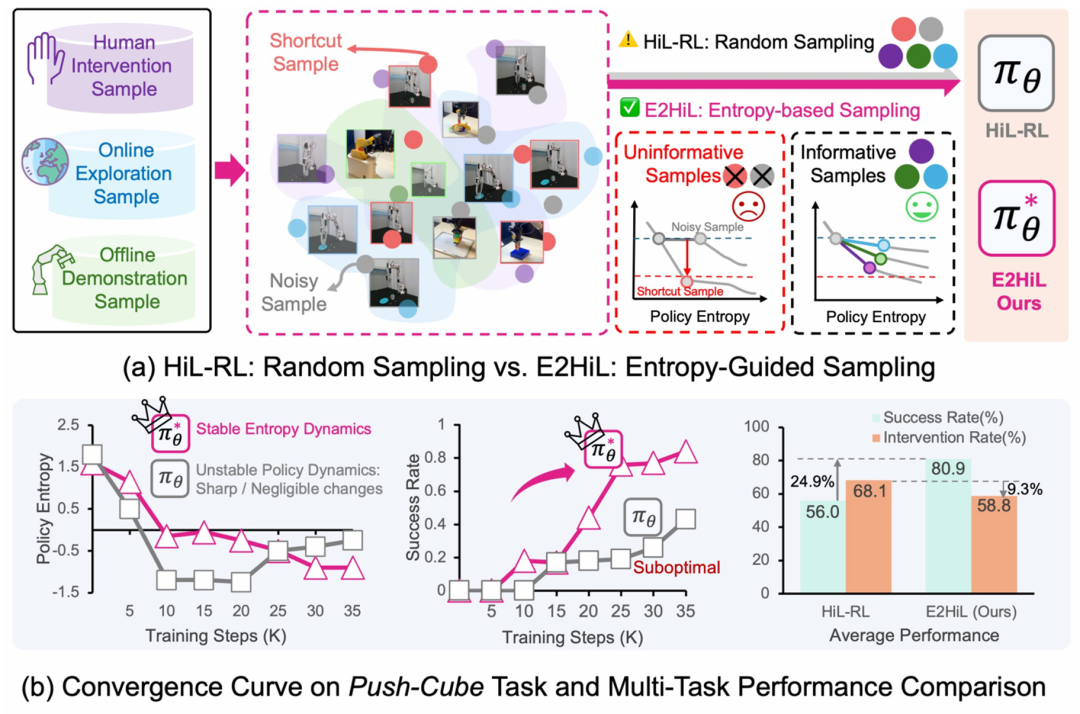
相比随机均匀采样,E2HiL 用影响函数识别每个样本对策略熵的作用,剪掉会引发早熟收敛的捷径样本和几乎没价值的噪声样本,换来更稳的熵下降和更少的人力。

人类介入样本的协方差幅度显著高于自探索样本,集中在影响分布的高尾,正是它们最容易把策略熵压垮。
03
UniIntervene:让系统自己判断何时该出手
论文链接:https://arxiv.org/abs/2606.12372
项目主页:https://denghaoyuan123.github.io/UniIntervene-project/
E2HiL 把输入端的数据质量提了上来,但 online RL 回路里还有一段绕不过去:策略真的开始失败、停滞、反复做无效动作的时候,谁来踩刹车。现有的 HiL-RL 里,这个决定是外生的,由站在旁边的人来下,人决定什么时候介入,也由人给出纠正动作。UniIntervene 的核心想法,是把这个决定变成内生的,交给策略栈内部一个学出来的模块。形式上,它引入一个介入模块,输入当前的观测、指令和动作,一次性输出三样东西:

分别是继续当前动作的价值估计、一个介入分数、以及一段纠正动作。也就是说,要不要打断和打断之后怎么办,从一件人来拍板的事,变成了系统自己能算出来的事。这就是它 agentic 的地方:介入不再是外部事件,而是策略自己的一个内部决策。
这里有一个容易被忽略、却很关键的判断。过去想减少人力的工作大体分两路,一路盯着安全,避免不可逆的失败;一路盯着可复位,保证出事了能 reset 回去。但真机 RL 里最耗人的,其实既不是危险动作,也不是不能复位的状态,而是那些既安全、又能复位、却就是不往前走的回合。机器人没坏,场景也没乱,它只是卡在那儿空转。该问的不是这一步安不安全,而是这个回合还在不在涨价值。UniIntervene 整个设计,都是绕着这个问题转的。
要回答还在不在涨价值,先得有个靠谱的价值信号。真机操作里奖励稀疏,单看当前这一帧几乎说明不了一个动作的好坏。UniIntervene 换了个做法,不直接对当前观测估值,而是先预测当前动作会带来的未来后果。它把观测、指令、动作编码到一起,预测下一步的隐状态,并用一个冻结的 V-JEPA2 编码器给的真实未来表征来监督它:

再由一个 twin value head 在这个预测出来的未来表征上估值。这样拿到的是一个前瞻的进展信号,在稀疏奖励下比盯着当前帧稳得多。
有了价值信号,还不能一看到价值低就介入。真机操作里,接触、对齐、重抓这些环节本来就会短暂经过低价值状态,那不该触发介入。该看的不是某一时刻的高低,而是一段时间里的走势。UniIntervene 把它写成一个时序的价值-风险量:

拆开看,后半截是窗口内每一步的进展亏空,也就是价值的实际增量没达到期望速率 ε 的那部分,按时间折扣累加;前半截 是还差多少到终点。只有当价值在一段窗口里持续涨不动、亏空不断累积,才会变大;越接近完成,前面的系数越小,风险被自然压下去。所以它响应的是持续的停滞,而不是偶然一帧的下跌。论文里的可视化能看到,触发恰好发生在价值曲线的谷底(比如插内存条任务的第 13 步),而不是第一帧掉下去的地方,说明这个时序聚合确实分得清真停滞和路过的低点。
决定出手之后,下一个问题是恢复到哪里。从一个低价值状态直接生成纠正动作其实是欠定的:critic 只告诉你这个回合不行了,没告诉你该回到哪个好状态。UniIntervene 把恢复拆成去哪和怎么去两步,并把去哪接到经验上。它维护一份记忆 M,存的是过去的介入时刻、和它们在同一段轨迹里后来真正到达的高价值状态的配对,而且只收那些未来状态价值确实够高的条目。触发后,它在一个共享嵌入空间里拿当前情境去匹配记忆中语义相近的失败情境,检索出对应的高价值目标:
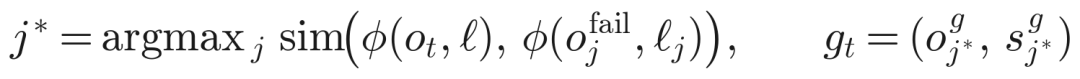
然后把这个目标交给一个 goal-conditioned recovery policy,由它生成一串可执行动作,把机器人带到目标附近,再把控制权还给主策略。记忆负责去哪,恢复策略负责怎么去,一个欠定的纠错问题就被转成了一个明确的够目标问题。
还回到插内存条那个例子。一开始价值低而平,策略一直对不准;UniIntervene 不急着动手,等停滞确实持续了才在谷底触发,从记忆里调出一个验证过的高价值目标,价值随后一路平滑爬升到成功,全程没有人接管,也没有第二次触发。把这套机制放到五个真实操作任务上(取放茄子、插管、插内存条、擦白板、叠毛巾),UniIntervene 在每个任务上都拿到最高成功率,平均成功率比最强的 HiL-SERL 基线高 8.6%,人工介入率从 34.3% 压到 14.6%,砍掉了 57%。介入的主体,正在从人换成系统自己。
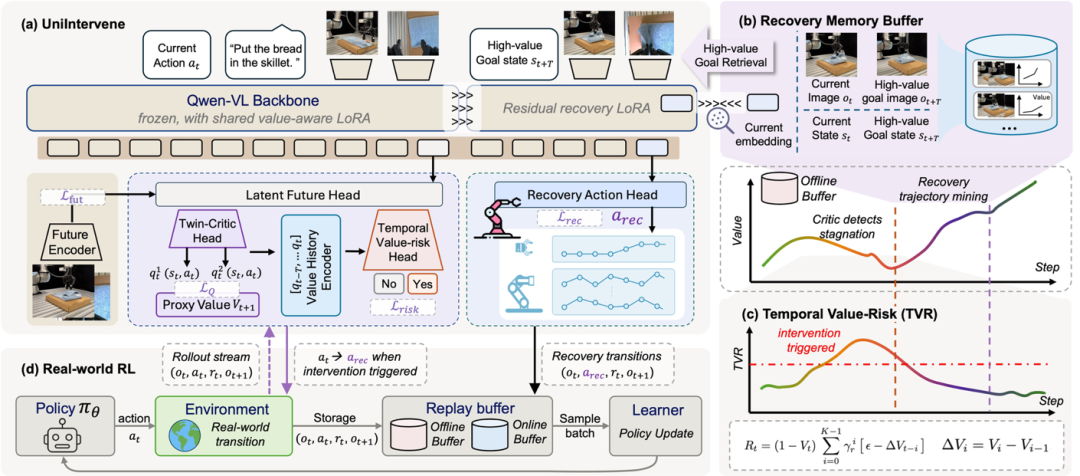
UniIntervene 用一个内生的介入模块统一了触发与恢复,价值-风险 critic 判断何时出手,记忆引导的目标条件策略决定恢复到哪里、并生成纠正动作。

在持续低价值停滞处触发、检索高价值目标后价值单调回升至成功;整体上在提升成功率的同时把人工介入砍掉过半。
04
两条原则,一条路线
E2HiL 和 UniIntervene 落在 online RL 回路的两端。E2HiL 管输入端,用影响函数把每个样本对探索的作用算出来,只留下真正推动策略、又不压垮熵的那批;UniIntervene 管运行端,用一个内生的价值-风险模块,在策略空转时自己判断、自己恢复。一个让数据更值钱,一个让回路在跑偏时自己回正。两者合起来,真机 RL 就不只是一个优化器,而是一套带数据筛选、价值评估、风险判断、记忆检索和恢复策略的闭环系统。
把这条线放回 ENPIRE 指向的趋势会更清楚。ENPIRE 让真实机器人学习变成一个由 agent 驱动、能自我改进的闭环,E2HiL 和 UniIntervene 则是同一种思路在 human-in-the-loop 场景里的延伸,分别从样本效率和介入自主性两个角度,让回路自己挑数据、自己纠偏。它们着力的层面不同,却指向同一件事:真实世界里的学习,正在从靠人维护,慢慢走向自己驱动自己。
这里可以下一个判断。具身智能能不能落地,恐怕不会只取决于 VLA 模型做得多大。真正决定上限的,是机器人能不能在真实世界里,以可控的成本和风险,安全地一直变好下去。
05
结语
真机 RL 正在从一种训练算法,慢慢长成具身智能落地的底层引擎。当机器人能从真实失败里筛出有用的样本,能在空转时自己回正,并在物理世界里一轮一轮迭代策略,它对人的依赖就会一直往下走。
从 E2HiL 到 UniIntervene,变的不是某个方法的指标,而是真机 RL 的范式:从人在旁边帮着训,挪到系统自己改自己。模仿能让机器人上场,但能不能在真实世界里长期待下去,要看它会不会自己变好。
本文工作来自南洋理工大学 PINE Lab。PINE Lab,全称为 Perception and Embodied Intelligence Lab,由王子为助理教授领导,长期关注具身智能、机器人学习、世界模型、VLA 模型、触觉感知与真实机器人强化学习等方向,致力于构建能够在真实物理世界中感知、理解、交互并持续学习的智能机器人系统。
王子为博士现任南洋理工大学电子与电气工程学院助理教授,曾在卡内基梅隆大学机器人研究所从事博士后研究,并于清华大学获得博士与学士学位,其研究聚焦于面向机器人操作的基础模型与真实世界具身智能系统。

参考文献
Xiao W, Xie J, Zhang T, et al. ENPIRE: Agentic Robot PolicySelf-Improvement in the Real World[J]. arXiv preprint arXiv:2606.19980, 2026.
Deng H, Lin Y, Xue Y, et al. E2HiL: Entropy-Guided Sample Selectionfor Efficient Real-World Human-in-the-Loop Reinforcement Learning[J]. IEEE Robotics and Automation Letters, 2026.
Deng H, Gao Y, Lin Y, et al. UniIntervene: Agentic Intervention forEfficient Real-World Reinforcement Learning[J]. arXiv preprint arXiv:2606.12372, 2026.
推荐阅读 :