点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!
“学习总是胜过归纳偏置。”——乔纳森·T·巴伦,《辐射场与生成媒体的未来》
0. 论文信息
标题::Scalable Permutation-Equivariant Visual Geometry Learning
作者:Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, Tong He
机构: Shanghai AI Lab、ZJU、SII
原文链接:https://arxiv.org/pdf/2507.13347
代码链接:https://github.com/yyfz/Pi3
1. 导读
我们提出π³,这是一种前馈神经网络,为视觉几何重建提供了一种新方法,打破了传统固定参考视图的依赖。先前的方法通常将重建结果锚定在指定的视点上,这种归纳偏置在参考视点不佳时会导致不稳定和失败。相比之下,π³采用了一种完全置换等变架构,无需任何参考坐标系即可预测仿射不变的相机位姿和尺度不变局部点图。这种设计使我们的模型对输入顺序具有内在的鲁棒性,并且具有高度的可扩展性。这些优势使我们的简单且无偏置的方法在相机位姿估计、单目/视频深度估计和稠密点图重建等广泛任务上取得了最先进的性能。代码和模型已公开可用。
2. 效果展示
π³以一种前馈的方式有效地重建了开放域中的多种图像,这些图像涵盖了室内、室外和俯视等多种场景,以及包含动态和静态内容的图像。

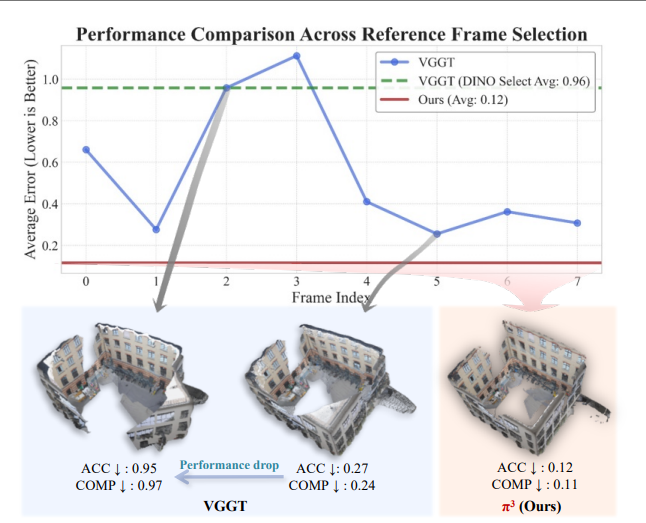
不同参考框架之间的性能比较。虽然以前的方法,即使与DINO为基础的选择,显示不一致的结果,π3一贯提供卓越和稳定的性能,证明了其鲁棒性。
3. 引言
视觉几何重建是计算机视觉领域长期存在的一个基础性问题,在增强现实、机器人技术和自主导航等应用中具有巨大潜力。
虽然传统方法使用迭代优化技术(如光束平差法(Bundle Adjustment,BA))来解决这一挑战,但最近前馈神经网络在该领域取得了显著进展。像DUSt3R及其后续模型这样的端到端模型已经展示了深度学习从图像对、视频或多视图集合中重建几何图形的强大能力。
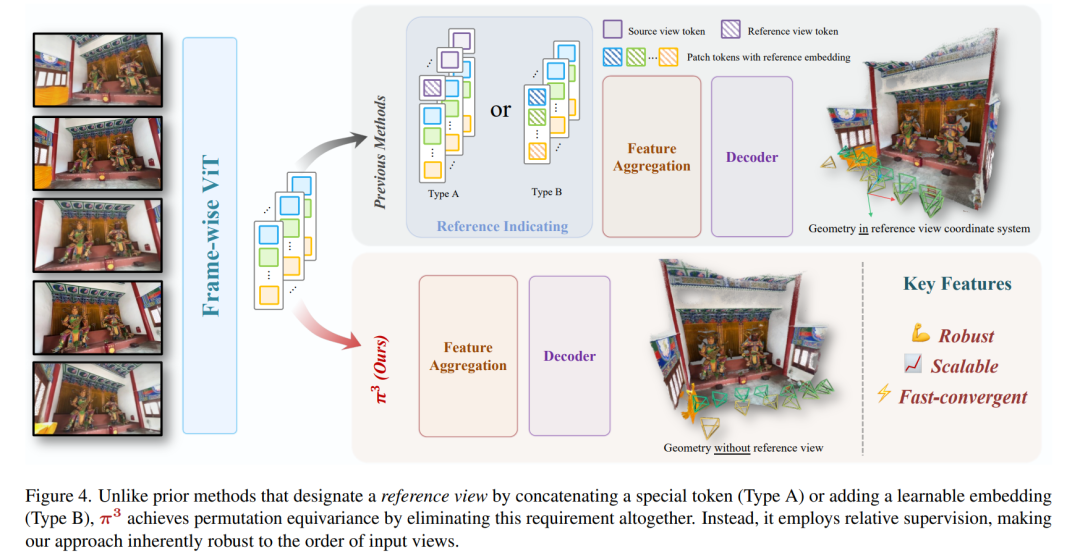
尽管取得了这些进展,但经典方法和现代方法都存在一个关键局限性:依赖选择单个固定参考视图。所选视图的相机坐标系被视为全局参考坐标系,这种做法源自传统的运动恢复结构(Structure-from-Motion,SfM)或多视图立体(Multi-view Stereo,MVS)。我们认为,这种设计选择引入了一种不必要的归纳偏置,从根本上限制了前馈神经网络的性能和鲁棒性。正如我们通过实证所证明的,对任意参考视图的依赖使得包括最先进(SOTA)的VGGT在内的现有方法对初始视图选择高度敏感。选择不当会导致重建质量急剧下降,阻碍了鲁棒且可扩展系统的开发。
为了克服这一局限性,我们提出了π³,这是一种鲁棒、可扩展且完全置换等变的方法,消除了视觉几何学习中基于参考视图的偏置。π³接受各种输入,包括来自静态或动态场景的单张图像、视频序列或无序图像集,而无需指定参考视图。相反,我们的模型为每个帧预测一个仿射不变的相机位姿和一个尺度不变局部点图,所有这些都相对于该帧自身的相机坐标系。通过避免使用像帧索引位置嵌入这样依赖于顺序的组件,并采用一种在视图级和全局自注意力之间交替的变换器架构,π³实现了真正的置换等变性。这保证了视觉输入与重建几何图形之间的一致的一对一映射,使模型对输入顺序具有内在的鲁棒性,并且不受参考视图选择问题的影响。推荐课程:机械臂6D位姿估计抓取从入门到精通。
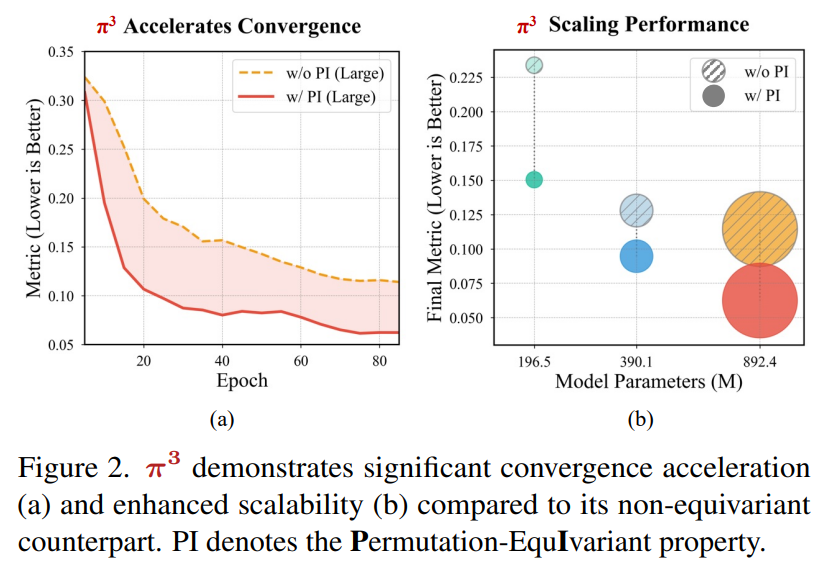
我们的设计带来了显著的优势。首先,它展示了卓越的可扩展性,随着模型规模的增加,性能持续提升(图2和图9)。其次,它实现了显著更快的训练收敛速度(图2和图9)。最后,我们的模型更加鲁棒;与先前的方法相比,当参考帧改变时,它的性能下降最小,标准差较低。

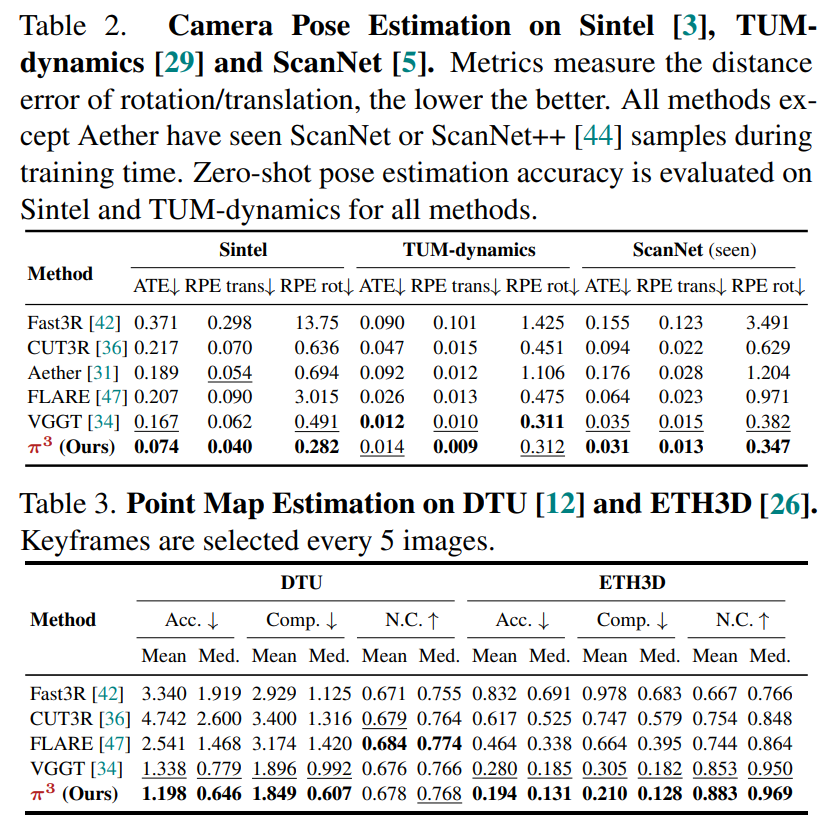
通过广泛的实验,π³在众多基准测试和任务上建立了新的最先进水平。例如,它在单目深度估计方面取得了与现有方法(如MoGe)相当的性能,并在视频深度估计和相机位姿估计方面优于VGGT。在Sintel基准测试中,π³将相机位姿估计的绝对轨迹误差(ATE)从VGGT的0.167降低到0.074,并将尺度对齐的视频深度绝对相对误差从0.299提高到0.233。此外,π³既轻量又快速,推理速度达到57.4 FPS,而DUSt3R为1.25 FPS,VGGT为43.2 FPS。它能够重建静态和动态场景的能力使其成为现实世界应用的鲁棒且最优的解决方案。

4. 主要贡献
本工作的贡献如下:
• 我们是第一个系统地识别并挑战视觉几何重建中对固定参考视图的依赖的研究,证明了这种常见的设计选择引入了一种有害的归纳偏置,限制了模型的鲁棒性和性能。
• 我们提出了π³,这是一种新颖的、完全置换等变的架构,消除了这种偏置。我们的模型以纯相对的、逐视图的方式预测仿射不变的相机位姿和尺度不变点图,完全消除了对全局坐标系的需求。
• 我们通过广泛的实验证明,π³在相机位姿估计、单目/视频深度估计和点图重建等广泛基准测试上建立了新的最先进水平,优于先前的领先方法。
• 我们表明,我们的方法不仅对输入视图顺序更加鲁棒,并且随着模型规模的扩大更具可扩展性,而且在训练期间收敛速度显著更快。
5. 方法
与先前通过拼接特殊标记(A型)或添加可学习嵌入(B型)来指定参考视图的方法不同,π³通过完全消除这一要求来实现置换等变性。相反,它采用相对监督,使我们的方法对输入视图的顺序具有内在的鲁棒性。
6. 实验结果

7. 总结
在这项工作中,我们引入了π3,它通过消除对固定参考视图的依赖为视觉几何重建提供了一种新的范式。通过利用完全排列等变结构,我们的模型对输入顺序具有固有的鲁棒性和高度可伸缩性。这种设计选择消除了在以前的方法中发现的一个关键的诱导偏差,使我们简单而强大的方法在广泛的任务上实现国家的最先进的性能,包括相机姿态估计,深度估计和密集重建。π3证明了无参考系统不仅可行,而且可以导致更稳定和多功能的3D视觉模型。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。
3D视觉硬件,官网:www.3dcver.com

3D视觉学习圈子
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001