一次DeepSeek时刻的冲击尚不足以让我们警醒,但愿我们无需经历第三次。
内森·兰伯特
2025年7月14日
今年早些时候发布的DeepSeek R1,并非一次性事件,而更像是人工智能发展轨迹中的恢弘序章。
上周,中国初创公司月之暗面发布了Kimi K2。这是一款采用宽松许可¹的开源模型,其性能足以和美国最前沿的模型正面竞争。
若您关心人工智能的地缘政治与技术的快速扩散,那么这标志着又一个DeepSeek时刻的到来。整个西方世界,即便是那些自认紧跟AI潮流的人,也必须彻底改变对未来的预期。

简而言之,Kimi K2向我们揭示了三个不争的事实:
打造了DeepSeek的HighFlyer,绝非中国境内唯一具备顶尖能力的AI实验室。 中国正持续迫近,甚至可以说已经抵达了模型性能的全球最前沿。 在开源模型的赛道上,西方世界正被越甩越远。
Kimi K2被定义为一种开源智能体模型,它采用稀疏专家混合架构²,总参数量高达1万亿,激活参数量为320亿。
这是一款无需长篇推理的模型,在编码和智能体任务上表现卓越,因此常被拿来与Claude 3.5 Sonnet相提并论。尽管它不生成冗长的思考过程,却依然经过了强化学习的深度锤炼。
在多项关键基准测试中,它都明显超越了DeepSeek V3,并同时发布了基座模型。毫无疑问,Kimi K2是当前开源领域无可争议的新王者,其优势清晰可见。
这些事实为我们洞见未来趋势提供了有力的线索:
想要通过技术手段限制谁能训练顶尖模型,是极其困难的。 OpenAI、谷歌、Meta等公司的名单只会越来越长,月之暗面已经加入了这个行列。
只要人才与算力足够集中,卓越的模型就必然会诞生。这在中国或欧洲这样的人才高地尤其如此,但绝不局限于这些地区。
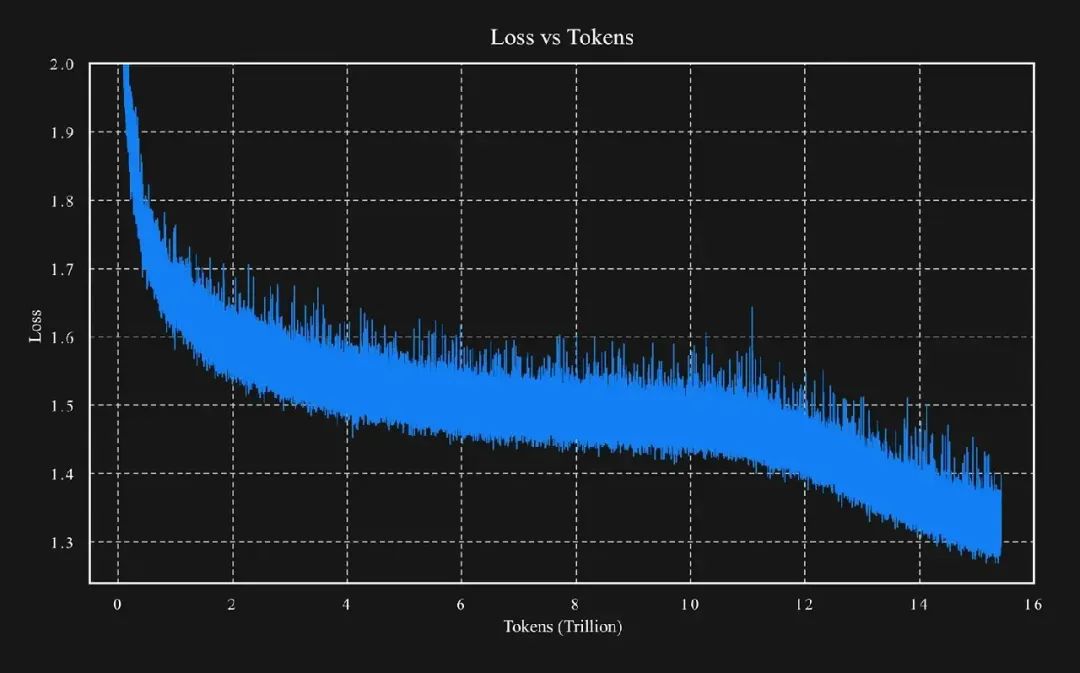
Kimi K2的训练数据量为15.5万亿token,其激活参数量与DeepSeek V3/R1极为相近。这说明,我们正目睹一个趋势:在算力没有显著增长的情况下,通过算法与效率的优化,更强大的模型正在被创造出来。
对中国公司而言,算力限制确实会拖慢其发展步伐,但这绝不是一个能决定其生死的开关。
西方顶尖实验室的开源模型,与它们中国对手之间的差距,不仅没有缩小,反而正在急剧扩大。
美国公司拿得出手的最佳开源模型或许是Llama-4-Maverick?而DeepSeek、月之暗面、阿里通义千问这三家中国组织,均已发布了用途更广、许可更宽松的、明显更优越的模型。
与此同时,推理密集型的新产品正不断涌现。相比于高利润的闭源API,开源模型提供的低成本、低利润托管方案,将使这些新产品极大受益。
Kimi K2所引发的DeepSeek时刻,其发酵速度注定比今年一月的DeepSeek R1要慢一些,因为它缺少两个关键的文化引爆点:
其一,DeepSeek R1首次向用户揭示了模型的推理链,这在技术圈外引发了现象级的关注和采纳。
其二,公众已经普遍认识到,一旦技术壁垒被攻克,训练顶尖AI模型的实际成本极其低廉。因此,当Kimi K2的技术报告公布相似的低成本数据时,市场的震撼感自然会减弱。
尽管如此,随着关于K2的讨论声量渐起,局势可能瞬息万变。我们已看到有人迅速将其API接入Claude的应用,并在各种主观体验和创造力测试中拔得头筹。
一个有趣的花絮足以说明其分量:在主流API路由平台OpenRouter上,Kimi K2的API调用量已经超越了上周大张旗鼓发布的Grok 4。
就在K2发布的当天晚些时候,OpenAI的CEO萨姆·奥特曼就其备受期待的开源模型发布了如下消息:
❝我们原计划下周发布开源权重模型。
但我们决定推迟。我们需要更多时间进行额外的安全测试,并审查高风险领域。目前尚不确定需要多久。
我们相信社区能用它创造伟大的事物,但权重一旦释出,便无法收回。这对我们是全新的挑战,必须谨慎对待。
很抱歉带来坏消息,我们正在全力以赴。
许多人认为,这是OpenAI为了避开Kimi K2发布锋芒和新一轮DeepSeek媒体热潮而采取的被动之举。
即便OpenAI内部有人向我澄清,称Kimi导致其模型延迟发布的传言不实,但这已经无关紧要。这,就是身处被动的真实写照。 当你落入守势,便会彻底失去对舆论走向的掌控力。
美国那些闭源AI实验室的领导者们,是时候重新思考他们在研发生态中所面临的长期博弈了。我们必须为欧美世界那些卓越的、开放的科学项目动员真正的资金支持。
否则,如果你还寄望于西方能成为AI研发的永恒基石,那么眼前所见的,就是失败的模样。
Kimi K2的出现表明,一次DeepSeek时刻的冲击,还远不足以驱动我们做出必要的改变。
但愿,我们无需等待第三次。
¹ 其修改版的MIT许可证在合规上虽不复杂,但附加的营销条款与纯粹的开源精神有所冲突。
² 其架构与DeepSeek非常相似。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!