作者丨张进

7月1日,Jelani Nelson在X上发了一条推文。
没有长篇大论,没有感性的告别辞,只有一句简短的声明:他将暂离加州大学伯克利分校,加入Anthropic。随即引发了大量关注。
Nelson不是普通教授,他是伯克利EECS(电子工程与计算机科学系)的系主任,手握计算机科学领域最难拿到的终身教职之一,在学术界待了十五年,从MIT博士一路走到全美顶尖CS系的一把手。
YC总裁Garry Tan看完消息只说了一句:Anthropic现在吸人可太猛了。
但如果你把视线从Nelson一个人身上挪开,往后退两步看全局,会发现一个更值得讲的故事:过去两周,Anthropic完成了一次教科书级的人才虹吸:诺贝尔化学奖得主John Jumper从Google DeepMind跳了过来,DeepMind两位高级研究员Jonas Adler和Alexander Pritzel同期加入,Jelani Nelson紧随其后。
两周之内,一位诺奖得主、两位DeepMind核心研究员、一位在任系主任,全部涌向同一家公司。
这不是“又一位教授加入Anthropic”的故事。这是Anthropic正在重塑AI行业人才格局的截面——它不只是在抢人,它在搭一种过去从未存在过的研究班子。
Nelson是谁:
把算法课讲出2100万播放量的人
很多人认识Nelson,是从哈佛YouTube频道那节《Advanced Algorithms》课开始的。
九十分钟,黑板手书,一路猛推公式。没有花哨的幻灯片,没有段子,只有粉笔和数学。这条视频至今播放量超过2100 万,以算法公开课来论,几乎是独一档的存在。
1984年出生的Nelson,走的是一条非常“古典”的理论计算机科学路线。他在MIT一口气读完了本科、硕士和博士,本科同时拿计算机科学和数学两个学位。博士阶段,他开始死磕一个看起来很抽象的问题:当数据量大到存不下、只能扫一遍、还在不断变化的时候,怎么用最小的内存保留足够多的信息?
他的博士论文《Sketching and Streaming High-Dimensional Vectors》拿了MIT的杰出博士论文奖。这个方向——流式算法(Streaming Algorithms)和降维(Dimensionality Reduction)——后来贯穿了他整个学术生涯。
博士毕业后,Nelson在伯克利、普林斯顿和普林斯顿高等研究院做博士后。2013年加入哈佛,2019年跳到伯克利EECS,2024年7月出任计算机科学分部主任,2025年7月升任系主任。从助理教授到系主任,用了十二年。
他的学术贡献集中在三个方向:流式算法、降维理论、随机算法。其中最具标志性的是两件事:
第一,他和Kasper Green Larsen合作,证明了Johnson-Lindenstrauss引理的最优性。简单说,这个引理是高维数据降维的数学基石,Nelson的工作确立了它的理论下界:没有任何算法能比这个极限做得更好。
第二,他和Daniel Kane、David Woodruff合作,给出了count-distinct问题(在数据流中数有多少个不同元素)的渐近最优算法,用O(ε² + log d)的空间就能搞定。
这些成果看起来离AI很远,但实际上——这正是Anthropic要他的原因。
流式算法和大模型,
为什么是同一件事?
表面上看,Nelson研究的是“怎么用极小内存处理海量数据流”,而大模型公司关心的是“怎么用有限算力训练和推理更大的模型”。两件事的数学结构高度同构。
举几个具体场景:
KV Cache压缩。 当上下文窗口拉到百万token级别时,一个8B参数模型的KV Cache就要吃掉超过137GB显存,远超单张80GB GPU的容量。哪些状态该留、哪些该丢、怎么压缩——这本质上就是一个流式算法问题。Nelson的流式算法下界理论,直接回答了“KV Cache压缩的数学极限在哪里”。
向量数据库与RAG。 检索增强生成依赖高维向量的近似最近邻搜索。Nelson证明的JL引理最优性,确立了嵌入向量可被压缩到的理论最小维度。工程上可以无限逼近这个下界,但数学上不可能突破它。
数据去重与频率估计。 大模型预训练要在海量数据里去重、估计分布、筛选高质量样本,这正是count-distinct和频率估计问题的直接应用。Nelson给出的最优空间界,为这些工程操作提供了“可证明的效率天花板”。
换句话说,Nelson的工作划定了算法效率的“绝对前沿”:在给定硬件约束下,模型能算什么、不能算什么,哪些优化还有空间、哪些已经到了数学极限——这些都是他的理论工具能回答的问题。
Anthropic发言人确认,Nelson加入的是预训练团队,该团队目前聚焦于Claude核心知识和能力的研究。一个搞理论计算机的数学家,去了最需要算力效率优化的AI前沿,逻辑上是说得通的。
两周人才地震:
Anthropic在搭什么班子?
把Nelson的加盟放回时间线里,就会更清楚Anthropic在做什么。
过去两个月,Anthropic完成了一次结构性的人才布局:
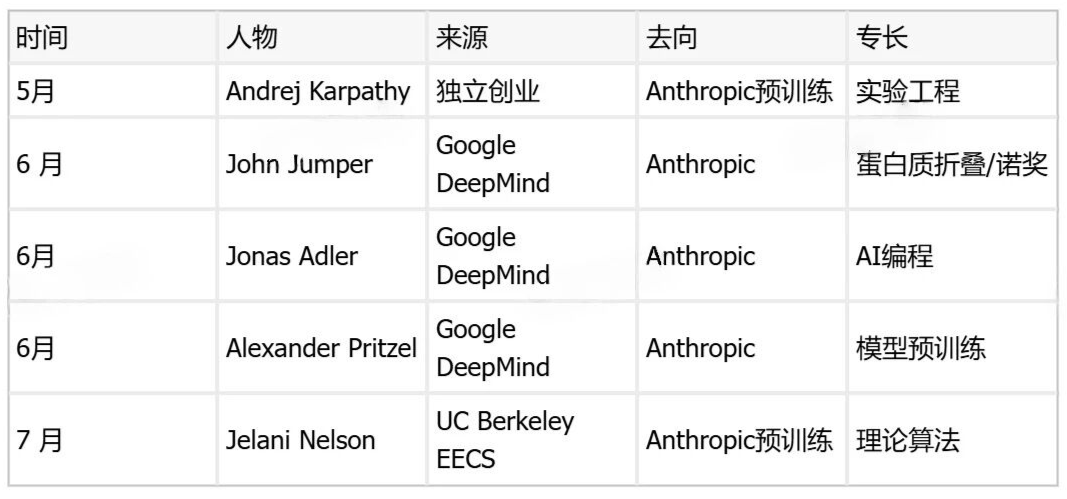
仔细看这个名单的结构:实验工程(Karpathy)+ 生物计算(Jumper)+ 编程AI(Adler)+ 预训练(Pritzel)+ 理论基础(Nelson)。
这不是在“抢人”,这是在“搭班子”。
过去几年AI公司的竞争逻辑是:谁能训练更大的模型,谁就赢。所以大家抢的是工程师和实验科学家。但Anthropic这波操作的信号很不一样——它在招募能证明什么可能、什么不可能的人。
Nelson的价值就在这里。当所有公司都在用经验主义的方式“撞墙”——试更大的batch size、试更长的上下文、试更多的数据——Nelson能做的事是:在花掉几百万美元算力之前,先用数学告诉你哪条路存在不可逾越的壁垒,哪条路还有理论空间。
这是从“工程竞争”向“理论竞争”的转向。Anthropic在赌:下一轮AI的突破,不取决于谁算力更多,而取决于谁先理解了模型的数学极限。
值得注意的是,Nelson去Anthropic的方式是“留职停薪”(Leave of Absence),不是辞职。他的伯克利教职还在,理论上随时可以回去。这种模式在美国学术界已经越来越常见——教授保留终身教职,同时去企业干几年,两头都不耽误。
但对大学来说,这把双刃剑的另一面是:教授人虽然还在编制里,但研究生可能跟着转向工业项目,研究方向可能在学术约束下无法延续,几年后教授回不回得来,也是个问号。
“人才旋转门”:
美国学术向产业流动的制度装置
Nelson的出走不是孤例,而是一种制度性现象。
在美国AI行业,高校教授去企业兼职或全职,有一条成熟的“旋转门”通道。卡内基梅隆大学(CMU)与当地企业的人才流动率高达37%——这意味着超过三分之一的CMU AI研究者会在学术和产业之间来回切换。
这种旋转门的底层逻辑是:企业能提供大学给不了的东西——算力、数据、真实场景、以及远超教职薪酬的报酬。而大学能提供企业给不了的东西——学术自由、长期研究空间、研究生资源、社会声望。两边互相需要,人才在门里门外转,知识也跟着转。
Nelson自己就是旋转门的典型产物。2021年到今年6月,他一边在伯克利当教授,一边在谷歌当研究科学家,两肩挑了四年。现在从谷歌换到Anthropic,不过是旋转门又转了一圈。
但这一圈转得比以前猛多了。
根据SignalFire 2025年人才报告,Google DeepMind工程师离职后选择去Anthropic的概率,是反向流动的近11倍。Anthropic在2026年6月秘密提交了IPO文件,估值约9650亿美元,年化营收约470亿。上市前的股权价值,再加上Anthropic能提供的算力规模和数据量级,每一项都让这些教授难以拒绝。
所以旋转门还在转,只是转速加快了,方向也更偏向产业一侧。
这对伯克利的影响是实实在在的。Jelani Nelson不只是普通教授——他是整个EECS系的系主任。他的离开意味着这所全美AI研究重镇,在理论算法方向暂时失去了最核心的掌舵人。这不像普通的人才流失,这是一整个研究方向暂时的群龙无首。
AI人才正在以前所未有的速度从学术机构向产业公司聚集。Anthropic用万亿美元估值、无限算力和上市前的股权,把学术向产业的人才流动转速推到了历史新高。这套“旋转门”机制,让知识在高校和企业之间持续循环,而Anthropic正在成为循环的终点站之一。