SHCHEGRIKOVICH
2025 年 8 月 4 日
新的焦点:深度研究智能体
在众多 AI 智能体中,深度研究智能体(DRA)正成为新的焦点。
其核心使命在于自主完成复杂的信息研究任务,涵盖了从在线搜索、深度分析到最终报告撰写的全过程。
例如,它能独立应对诸如 GitHub 上最热门的代码仓库是哪些,或 就聚变能源的最新突破撰写一篇文章 这样的深度探究。
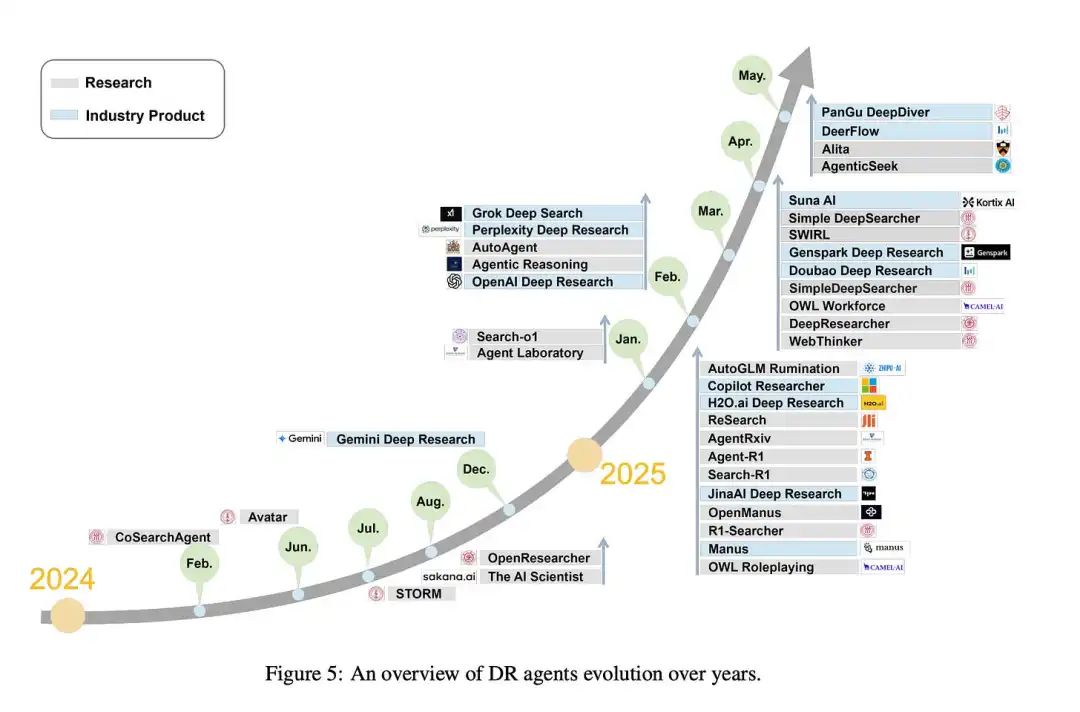
核心构建模块
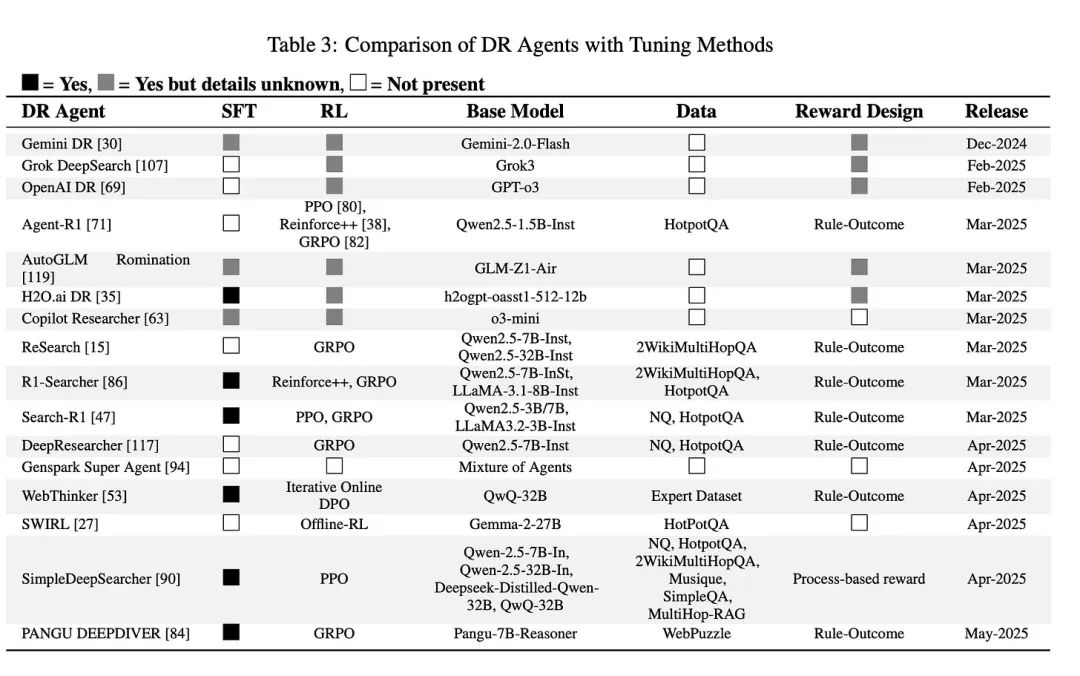
剖析深度研究智能体的架构,其核心构建模块包括搜索器、任务执行器、工作流编排器、报告生成器及调优器。
尽管有论文提出了如搜索引擎、工具使用、工作流、调优与非参数化持续学习等不同命名,但其底层逻辑与核心功能是相通的。

模块深度解析
搜索器作为信息入口,负责在线搜集或从本地数据库中检索资料。其搜索方式主要有两种:API 调用和模拟浏览器访问。
API 方案直接对接谷歌或 arXiv 等学术平台,效率高;而浏览器方案则能加载动态网页内容,但需处理 JavaScript 渲染。一个有趣的观察是,移动版网页有时比桌面版更简洁,易于解析。
任务执行器是 DRA 能力的延伸,通过工具调用来执行代码、分析数据、处理多模态信息,甚至操作计算机。这使得 DRA 能够胜任多样化的任务,如生成图表或验证算法。
报告生成器负责将研究成果整合,呈现给用户。例如,字节跳动的 DeerFlow 项目便是通过 LangChain 调用大语言模型,根据预设的风格和用户意图,自动生成结构化报告。
工作流编排器堪称系统的大脑,它澄清用户意图,制定研究计划,并管理记忆上下文。其运行模式分为静态和动态两种。
静态模式按预设流程执行,而动态模式则更为复杂,能够即时规划,甚至引入其他智能体协同工作。Manus 博客提出的广度研究理念,正是这种动态协作的体现,即主智能体可将子任务分派给其他 DRA。
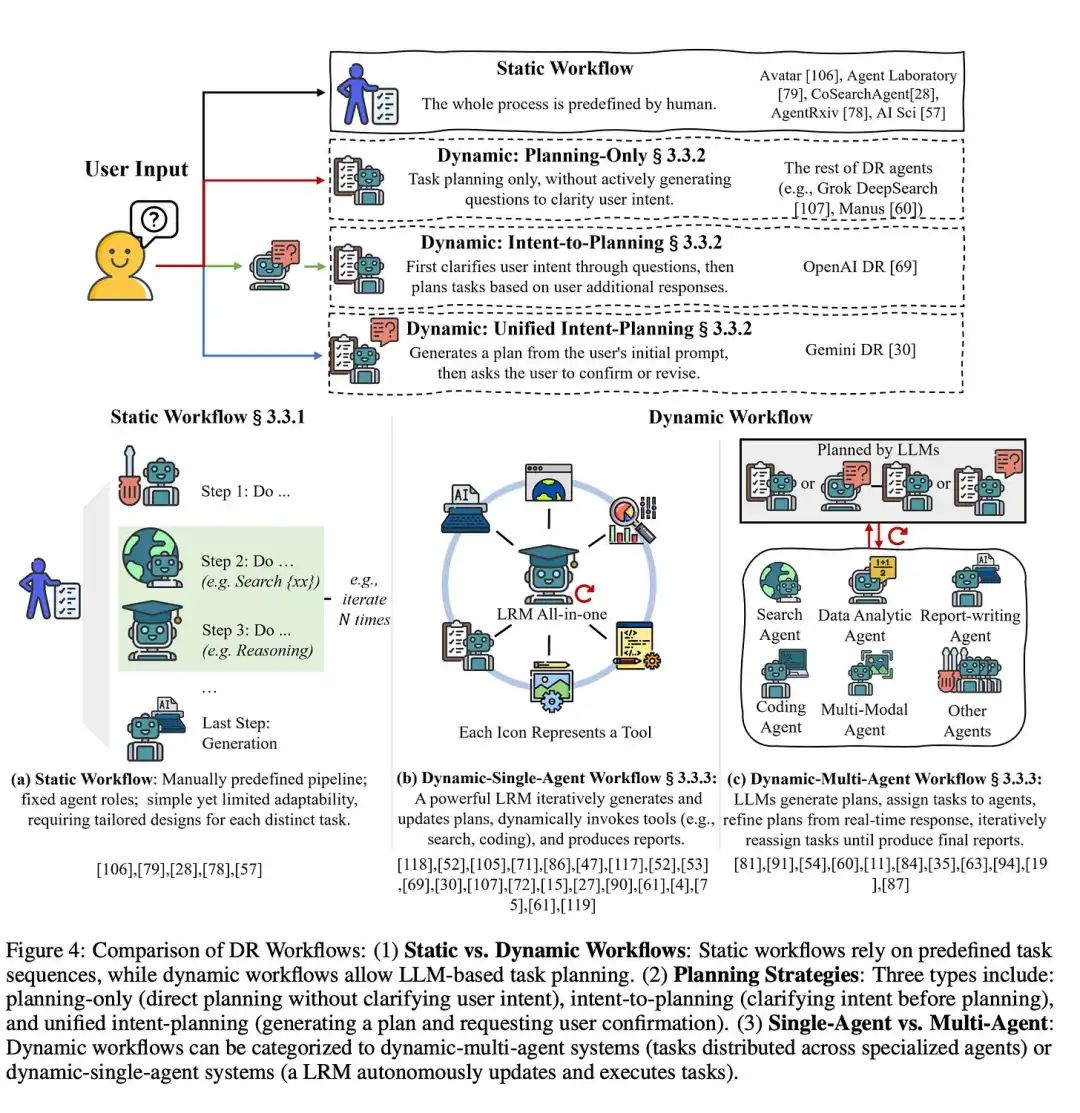
工作流背后的认知模式
值得一提的是,工作流的设计本身,就蕴含了某种解决问题的认知模式或心智模型。
最简单的模式是线性的:基于用户输入生成查询、获取结果、撰写报告。这是一种基础的研究直觉。
谷歌的论文则展示了一种更为精妙的认知模式,它模仿了人类学者的研究习惯:先形成草稿,再通过一轮轮的研究迭代来逐步精炼。
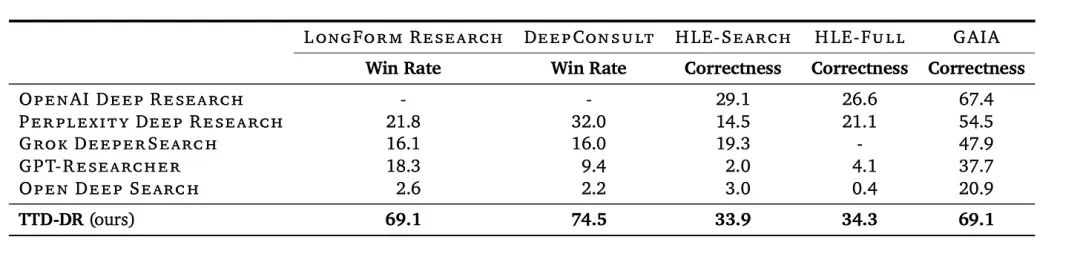
在这个模型中,每一个研究步骤,例如提出问题并利用搜索 API 寻找答案,都是对最终报告的一次打磨和深化。
其实现机制更为复杂,引入了自我进化理念,通过生成多个备选答案,并利用 LLM 即法官的模型进行裁决,选出最优解。
自我进化的关键:调优器
最后,调优器赋予了 DRA 自我完善和进化的能力。它让智能体能够从过往的经验中学习,不断提升自身性能。
实现路径有两条:一是参数化方法,如对模型进行微调或重新训练;二是非参数化方法,即通过非参数化持续学习,复用历史案例以实现快速适应与优化。
参考文献
论文:Deep Research Agents: A Systematic Examination And Roadmap - https://arxiv.org/abs/2506.18096 论文:Deep Researcher with Test-Time Diffusion - https://www.arxiv.org/abs/2507.16075 博客:Introducing Wide Research - https://manus.im/blog/introducing-wide-research Github:Deep Research assistant by ByteDance - https://github.com/bytedance/deer-flow
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!