编辑:严浠
从夹爪抓取到灵巧手抓取,机器人抓取技术日渐成熟。但除了抓取,通用机器人还应掌握非抓取操作的技能,以支撑其完成复杂场景下的操作任务。
像日常生活中的擦桌子、翻开书本,或是遇到过于庞大或轻薄无法抓取的物体,对于传统的依赖抓取的机器人来说都是十分棘手的难题。
为此,北京大学前沿计算研究中心联合银河通用等提出一个创新的动力学自适应世界动作模型(Dynamics-Adaptive World Action Model, DyWA),让机器人在非抓取操作上实现了重大突破。只需一个相机,就能灵活应对不同形状、重量、表面摩擦力的物体,完成非抓取操作任务,还能实现零样本Sim2Real迁移。与DyWA相关的论文成果已收录于ICCV 2025顶会。
实验表明,DyWA模型仅使用单视角点云观测时,在仿真环境成功率达到了82.2%,比基线方法提高了31.5%。DyWA在真实世界实验中达到了68%的平均成功率。

论文标题:
《DyWA:Dynamics-adaptive World Action Model for Generalizable Non-prehensile Manipulation》
论文链接:https://arxiv.org/abs/2503.16806
项目主页:https://pku-epic.github.io/DyWA/
收录情况:ICCV 2025
1
方法
1.1 任务设定
任务聚焦于通过非抓取操作实现目标物体的6D位姿重新摆放。机器人需要通过执行一系列非抓取动作(例如:推动、翻转),将桌面上的目标物体移动到目标位姿。
1.2 Pipeline概述
DyWA采用标准的teacher-student蒸馏框架。由于获取高质量演示数据较为困难,研究人员训练了一个基于状态的强化学习策略作为教师策略(teacher policy),该策略利用了完整的物体点云、任务状态以及物理参数。
为了适配真实世界的部署,研究人员引入了动力学自适应世界动作模型DyWA作为学生策略,该策略通过从教师策略蒸馏知识获得。但与教师策略不同,学生模型仅依赖于在真实场景中获取的有限观测信息。
1.3 世界动作模型 (World Action Model)
定义:世界动作模型是一种策略模型,它能够预测动作并预估该动作产生的结果。
观测与目标编码:模型以观测信息和目标描述作为输入,采用独立的编码器对不同模态数据进行编码。对于局部点云观测,使用简化版的 PointNet++进行处理,得到特征ftp 。对于机器人内部传感器信息,使用MLPs分别对关节位置、速度以及末端执行器位姿进行编码。
基于状态的世界建模:我们构建的端到端模型能够在进行动作决策的同时预测动作执行的结果,形成了一个相互促进的学习过程。模型通过预测动作产生的结果帮助其更好的执行动作,而实际动作的结果又可以让模型了解更多物理规律,帮助其更好的预测。

1.4 动力学自适应模块
在真实环境中,机器人往往无法直接获得桌面的摩擦系数及物体的质量分布是否均匀。DyWA引入了一种类似RMA(Rapid Motor Adaptation)的动力学自适应模块,通过分析历史观测和动作序列,推理出环境中隐含的物理属性,例如表面是否光滑、物体是否沉重或质量分布是否均匀。同时,历史信息还包含更完整的几何线索,弥补了单帧观测中的缺失。该动力学表示通过FiLM机制调控世界模型的中间特征,使策略在执行过程中能够动态调整 “用力” 或 “稳住” 的程度,实现自适应的物理交互。
2
实验
2.1 仿真环境中的基准测试
研究人员基于CORN设定建立了一个综合性基准,利用IsaacGym仿真环境,并使用DexGraspNet数据集中的323个物体进行训练。此外,研究人员又引入一个未见过的物体测试集,包含10个形状各异的物体,每个物体再按5种不同尺寸进行缩放,一共50个物体。
研究人员还引入了两个额外的感知维度:
(i) 单视角 vs 多视角(三相机)观测;
(ii) 是否已知用于构建任务状态 St 的物体位姿。在训练和测试环境在动力学属性(包括质量、摩擦系数、恢复系数)方面完全随机化。
选取了两种最先进的基线方法HACMan、CORN与DyWA模型进行对比,实验结果如下表所示。
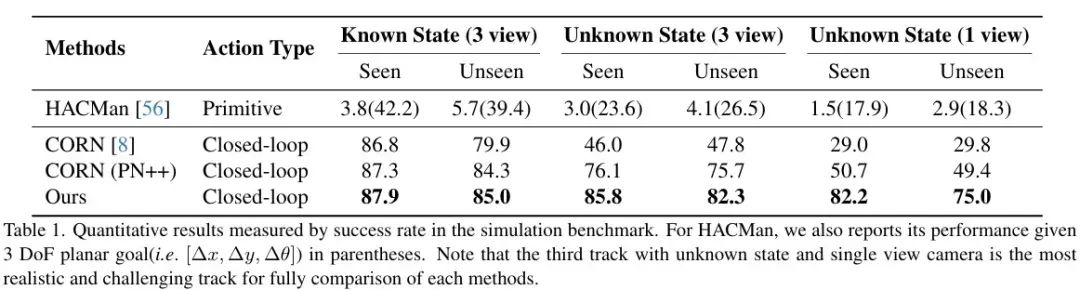
结果表明,在已知物体状态(三视角点云),未知物体状态(三视角点云)和未知物体状态(单视角点云)三种设置下,DyWA都显著优于基线方法,成功率达到了75%到87.9%。在未知物体状态(三视角点云)时,成功率相较于CORN(PN++)提高了31.5%。
2.2 真实世界实验
研究人员在真实世界中的Franka机械臂上进行了实验,配置一台放置于侧面的RealSense D435相机采集RGB-D 图像。在10个未见过的物体上进行评估,包括表面光滑的物体(光滑的金属片)和质量不均匀的物体(如半瓶水)。为评估模型对不同物体的泛化能力,研究人员将DyWA模型与CORN进行了对比,实验结果如下表所示。

实验结果表明,DyWA模型平均成功率达到了68%,显著高于了CORN的36%的成功率。CORN因单视角局部点云的遮挡问题及真实世界位姿估计不准确的问题难以很好地执行非抓取操作任务。如下视频所示为机器人将盛有半瓶水的瓶子立起来并放到指定位置。
研究人员还测试了机器人在不同摩擦力的桌面上的表现,选择了四种摩擦系数依次递减(即 µ₁ > µ₂ > µ₃ > µ₄)的桌布,并使用玩具推土机作为测试物体,实验结果如下表。

结果表明,未使用动力学自适应模型在摩擦力逐渐增大的桌面上表现出显著的性能下降,并导致执行时间明显增长。相比之下,DyWA模型在不同摩擦力的桌面上均保持80%成功率,同时任务时长也保持在45s~51s之间。这说明了DyWA模型能快速适应不同的桌面环境。如下视频所示为机器人在摩擦力最大的桌面上将玩具推土机立起来并放到指定位置。
2.3 应用
研究人员提出了一种实用操作系统,该系统整合了VLMs、DyWA模型以及一个抓取模型Asgrasp。利用VLMs,模型能够根据语言指令完成相应的操作任务。如下视频所示,传统的抓取-放置策略难以抓取一个很小的开关,而本论文提出的系统则能很好的实现。
3
总结
本论文提出了一个创新的动力学自适应世界动作模型DyWA。该模型能够预测未来状态,并基于历史轨迹自适应地调整动力学模型。只需要用一个相机,就能灵活应对不同形状、重量、表面摩擦力的物体,在非抓取操作任务中表现出了很强的泛化性。
在真机实验中验证了模型的性能,针对10个未见过且很难抓取的目标物体,平均成功率达到了68%。在“把玩具推土机摆放正确并挪到正确位置的实验中”,DyWA模型在不同摩擦力的桌面上均保持80%成功率,同时任务时长也保持在45s~51s之间。
END
智猩猩全新打造的「具身智能交流群」火热招募中!群内将提供独家公开课直播分享、一手活动和资源优先获取、精选优质内容分享、高质量同行交流~🎁前100名入群者,免费领取价值149元的具身智能技术研讨会视频,先到先得!

推荐阅读
RSS 2025最佳Demo奖!UC伯克利联合谷歌开源机器人强化学习框架MuJoCo Playground
从第一视角人类视频中学习操作技能!UCSD联合NVIDIA提出VLA模型EgoVLA,无需使用大量真机数据训练
首次将触觉作为原生模态引入VLA!清华叉院高阳团队联合提出Tactile-VLA,任务成功率近100%
实现灵巧手抓取80%成功率!银河通用王鹤团队提出视觉语言抓取模型DexVLG | ICCV 2025
点击下方名片 即刻关注我们