作者丨视觉语言导航
编辑丨视觉语言导航
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
作者: I-Tak Ieong, Hao Tang 单位:同济大学计算机学院,北京大学计算机学院 论文标题: Multimodal Perception for Goal-oriented Navigation: A Survey 论文链接:https://arxiv.org/pdf/2504.15643
主要贡献
基于推理域的分类:首次将目标导向导航方法按照推理域进行分类,涵盖了多种任务范式。这种分类方法揭示了不同任务之间的共性和差异,为理解导航方法提供了统一的框架。 计算模式的识别:识别了超越特定导航任务的共同计算模式,为具身推理的基本原理提供了见解。这些模式包括显式地图构建、隐式表示学习、图结构推理等。 推理域的优势和局限性比较:系统地比较了不同推理域在各种导航场景中的优势和局限性。例如,显式地图方法在路径规划中表现优异,但计算成本较高;而隐式表示方法则在计算效率上更具优势,但在复杂环境中的泛化能力可能受限。 多模态集成趋势:突出了多模态感知的集成挑战和机遇,特别是视觉、语言和音频处理的融合,以增强导航能力。文章讨论了如何通过多模态融合来提高导航的鲁棒性和适应性。
研究背景
目标导向导航是自主系统中的一个基本挑战,要求智能体能够在复杂环境中导航以到达指定目标。 过去十年中,导航技术从简单的几何路径规划发展到复杂的多模态推理,整合了视觉、语言和音频信息。 随着领域的发展,成功的导航方法越来越多地将低级感知与高级语义理解相结合,通过不同的计算框架实现。
基础概念
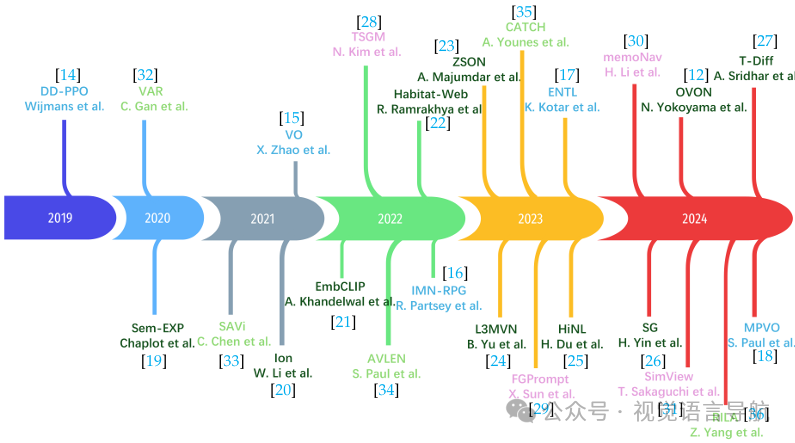
历史发展
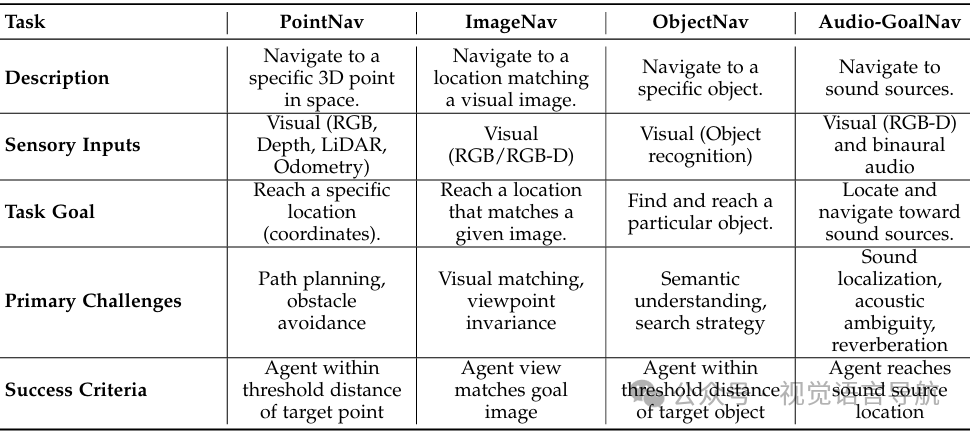
导航任务的历史发展:从简单的点目标导航(PointNav)到更复杂的多模态导航范式,导航任务的复杂性不断增加。例如,ObjectNav要求智能体找到特定对象,ImageNav要求智能体导航到与给定图像匹配的位置,AudioGoalNav要求智能体导航到声音源。 任务形式化定义:导航任务被形式化为一个决策过程,智能体需要在未知环境中通过一系列动作到达指定目标。数学框架适用于所有导航模态,包括环境(E)、状态空间(S)、观测空间(O)、动作空间(A)和目标空间(G)。
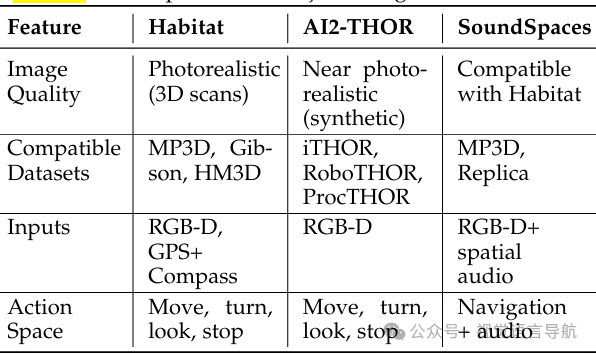
导航数据集
数据集规模和覆盖范围:Habitat-Matterport 3D (HM3D) 数据集是最大的集合,包含1000个建筑规模的重建,覆盖112.5k平方米的可导航区域。其他数据集如Gibson和Matterport3D在规模和复杂性上有所不同。 导航复杂性和场景杂乱程度:Matterport3D的导航复杂性最高,而RoboTHOR和ScanNet等房间规模的数据集则相对简单。 视觉保真度和重建质量:HM3D在视觉保真度上表现最佳,而ScanNet在重建缺陷方面表现最差。
评估指标
成功率(SR):智能体成功到达目标的百分比。 路径长度加权成功率(SPL):结合成功率和路径效率的指标。 距离相关指标:如目标距离(DTG)和导航误差(NE)。 多目标导航指标:如进度(PR)和路径长度加权进度(PPL)。 音频导航特定指标:如声音导航效率(SNE)和动态SPL(DSPL)。
点目标导航
任务描述
任务描述:智能体需要根据相对坐标导航到目标位置,没有环境布局的先验知识。主要挑战是使用以自我为中心的感官输入(主要是视觉数据,如RGBD、GPS/指南针)来确定智能体的位置,估计距离并规划路径。
潜在地图推理域

方法:构建和维护环境的显式表示,如占用网格或语义地图,以支持路径规划。例如,ANM通过神经SLAM构建地图,LSP-UNet通过U-Net架构估计前沿属性,UPEN通过集成学习生成不确定性地图。 关键方法: ANM:通过神经SLAM模块构建地图,结合全局策略进行探索,局部策略进行短期动作执行。 LSP-UNet:使用U-Net架构估计前沿属性,通过Bellman方程进行路径规划。 UPEN:通过集成学习生成不确定性地图,引导智能体探索信息丰富的区域。
隐式表示学习推理域
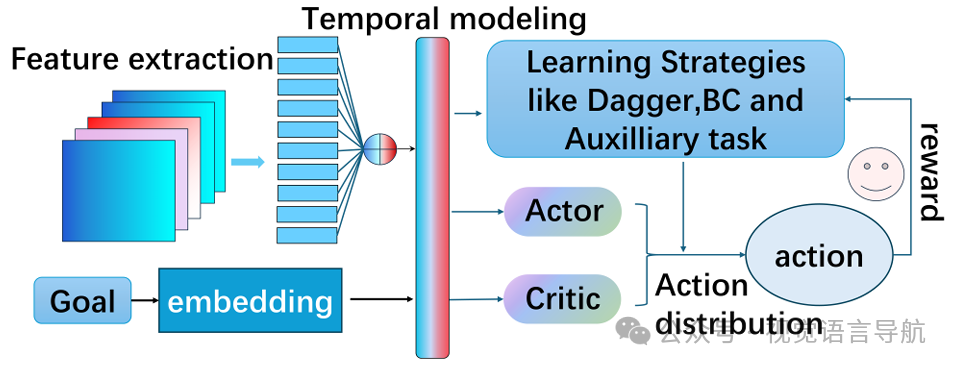
方法:不构建显式地图,而是通过神经网络参数隐式编码空间理解。例如,DD-PPO通过分布式训练提高可扩展性,IMN-RPG结合自我监督的视觉里程计和强化学习,无需显式映射。 关键方法: DD-PPO:通过分布式训练提高可扩展性,解决了高维输入的收敛问题。 IMN-RPG:结合自我监督的视觉里程计和强化学习,无需显式映射,通过自我运动预测维持智能体的中心位置估计。
目标对象导航
任务描述
任务描述:智能体需要在未知环境中找到并导航到特定对象。与PointNav不同,ObjectNav需要语义理解,智能体必须根据语义线索推断对象的位置。
模块化方法
方法:将ObjectNav任务分解为不同的模块,如映射、策略和路径规划。例如,Sem-EXP构建语义地图,PEANUT预测目标概率,L2M主动学习预测语义地图。 关键方法: Sem-EXP:通过不同iable投影构建语义地图,使用Mask R-CNN进行目标检测,结合目标导向的语义策略进行长期导航规划。 PEANUT:使用PSPNet生成语义分割掩码,投影到顶视图地图上,预测目标概率。
端到端方法
方法:直接从原始感官输入学习导航策略,无需显式中间表示。例如,VTNet利用空间感知描述符,DRL方法结合卷积层与LSTM进行序列处理。 关键方法: VTNet:利用空间感知描述符,结合DETR进行目标检测,通过预训练方案将视觉特征与导航信号关联。 DRL:结合卷积层与LSTM进行序列处理,通过PAAC算法进行训练。
零样本方法
方法:利用预训练的视觉语言模型实现零样本泛化,如EmbCLIP、ZSEL等。这些方法通过统一的嵌入空间建立视觉观察和语言描述之间的语义联系。 关键方法: EmbCLIP:使用冻结的CLIP ResNet-50嵌入,通过GRU进行有效的动作预测。 ZSEL:引入模块化迁移学习框架,结合视图对齐优化和任务增强技术,建立联合目标嵌入空间。
图像目标导航
任务描述
任务描述:智能体需要根据参考图像导航到目标位置,需要视觉推理能力来建立当前观察和目标图像之间的对应关系。

潜在地图推理域
方法:构建显式环境表示以支持目标匹配和路径规划。例如,MANav通过自监督状态嵌入网络增强导航,Mod-IIN结合前沿探索和目标实例再识别。 关键方法: MANav:通过自监督状态嵌入网络和情节记忆机制增强导航。 Mod-IIN:结合前沿探索和目标实例再识别,使用SuperPoint和SuperGlue进行目标匹配。
隐式表示推理域
方法:不依赖显式地图,通过神经网络参数隐式编码环境理解。例如,EmerNav通过估计观察和目标图像之间的匹配特征来直接导航。 关键方法: EmerNav:通过估计观察和目标图像之间的匹配特征来直接导航。 SLING:结合神经关键点描述符和透视-n-点算法,动态调整探索和利用策略。
图推理域
方法:将环境表示为关系结构,通过图遍历算法进行规划。例如,TSGM实现了一个双记忆系统,包括一个拓扑图和语义特征。 关键方法: TSGM:实现了一个双记忆系统,包括一个拓扑图和语义特征,通过层次化决策过程进行规划。
扩散模型推理域
方法:使用扩散模型生成导航策略,如NOMAD,它通过目标掩码进行条件推理,生成探索和目标导向行为的统一策略。 关键方法: NOMAD:通过目标掩码进行条件推理,生成探索和目标导向行为的统一策略。
音频目标导航
任务描述
任务描述:智能体需要根据声音源导航到目标位置,需要整合空间音频处理、视觉感知和路径规划。
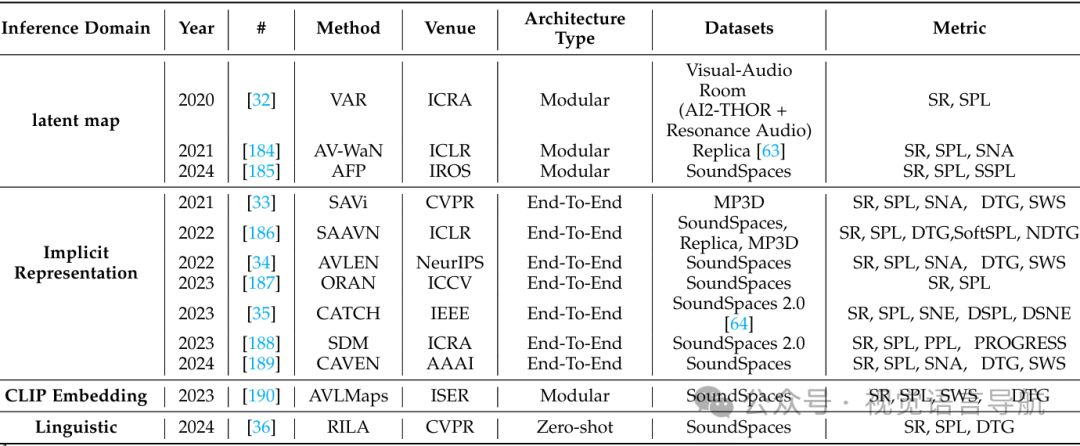
潜在地图推理域
方法:构建显式空间-声学表示以指导导航。例如,VAR结合视觉感知映射和声音定位,AV-WaN构建空间音频强度图。 关键方法: VAR:结合视觉感知映射和声音定位,通过STFT频谱图处理声音信号。 AV-WaN:构建空间音频强度图,结合几何表示进行路径规划。
隐式表示学习推理域
方法:不构建显式地图,而是通过神经网络参数编码空间-声学理解。例如,SAVi处理静态声源导航,ORAN处理动态声源导航。 关键方法: SAVi:处理静态声源导航,通过Transformer架构处理视觉和双耳音频输入。 ORAN:处理动态声源导航,通过深度几何地图和双耳音频输入进行路径规划。
嵌入式推理域
方法:利用预训练的视觉和音频模型建立语义连接。例如,AVLMaps通过自然语言理解扩展音频-视觉导航。 关键方法: AVLMaps:通过自然语言理解扩展音频-视觉导航,结合视觉、音频和语言模态。
语言推理域
方法:利用大型语言模型增强音频-视觉导航,如RILA,它通过语言模型进行环境推理。 关键方法: RILA:通过语言模型进行环境推理,结合视觉和音频输入进行路径规划。
讨论
跨任务见解
潜在地图适应性:潜在地图方法在不同导航任务中表现出不同的复杂性和信息内容。例如,在PointNav中,地图主要编码几何信息;在ObjectNav中,地图整合了语义对象标签和概率分布。 隐式表示的专门化:隐式表示方法在不同任务中表现出专门化,但共享核心架构元素。例如,在PointNav中,重点是视觉里程计和姿态估计;在ObjectNav中,重点是对象关系建模。 图的语义变化:图方法在不同任务中表现出不同的节点语义和关系结构。例如,在ObjectNav中,图通常表示对象-场景关系;在ImageNav中,图表示视觉上不同的位置。 语言集成策略:语言推理域在不同导航范式中表现出不同的集成深度。例如,在ObjectNav中,语言模型用于推理对象关系和空间布局;在AudioGoalNav中,语言模型用于推理声音源的语义属性。 嵌入平衡和适应性:嵌入式方法在不同任务中表现出不同的预训练知识和任务特定适应性平衡。例如,在ObjectNav中,直接利用CLIP的语义知识;在AudioGoalNav中,需要仔细整合AudioCLIP嵌入与空间推理。 扩散模型的环境合成:扩散模型在需要语义预测未观察区域的任务中表现出特别的潜力。例如,在ObjectNav中,扩散模型用于生成未观察区域的语义地图。
当前挑战
模拟到现实的转移:模拟环境与现实世界之间存在显著差异,尤其是在物理动态、传感器噪声特性和声学属性方面。虽然有一些方法开始解决声学模拟到现实的差距,但全面的解决方案仍然难以捉摸。 多模态表示和集成:虽然在多模态集成方面取得了显著进展,但最优融合策略仍然是一个开放性问题。当前的方法通常优先考虑一种感官模态,而其他模态则起到辅助作用。例如,在AudioGoalNav中,音频通常提供方向线索,而视觉数据主要用于障碍物避免。
未来工作
人机交互:结合自动化泛化和战略性人类互动,开发能够识别自身局限性并请求帮助的系统。例如,通过人类指导提供补充支持,结合语言机制进行通信、潜在地图进行空间表示和扩散模型进行环境补全。 多模态表示学习:开发真正平衡集成的多模态表示学习方法,通过共享标记化方法和跨模态注意力机制动态加权模态。例如,开发专门针对具身导航任务的多模态基础模型,建立统一的环境理解框架。
结论
本文通过推理域的视角,对多模态导航方法进行了全面分析,揭示了具身智能体如何感知、推理和导航复杂环境。 随着自主系统向现实世界部署的推进,有效整合多种感官模态已成为关键能力。 尽管取得了显著进展,但在多模态表示融合、模拟到现实的转移和计算效率方面仍面临重要挑战。

本文只做学术分享,如有侵权,联系删文