
论文题目:A Systematic Analysis of Hybrid Linear Attention
论文地址:https://arxiv.org/pdf/2507.06457

创新点
本文首次系统性地评估了三代线性注意力模型(从向量循环到高级门控机制)在独立使用和混合使用时的表现。以往的研究多集中在混合架构中全注意力层与线性注意力层的比例优化,而对线性注意力组件本身的架构选择关注较少。
本文识别出选择性门控(Selective Gating)、层次化循环(Hierarchical Recurrence)和受控遗忘(Controlled Forgetting)是实现高效混合模型的三个关键架构组件。这些组件共同作用,使得线性模型能够在较小的KV缓存成本下达到与Transformer相当的回忆性能。
本文推荐了具体的混合架构和线性与全注意力层的比例,这些架构在1.3B参数规模下能够实现接近Transformer的回忆性能,同时将KV缓存成本降低4到7倍。
方法
本文采用的主要研究方法是系统性地评估和对比不同代际的线性注意力模型及其在混合架构中的表现。研究者们训练并开源了72个模型,包括340M参数和1.3B参数两种规模,覆盖了六种线性注意力变体和五种混合比例。这些模型在标准的语言建模和回忆任务上进行了基准测试,以评估其性能。
三代线性注意力状态更新图

本图展示了三代线性注意力模型的状态更新机制。左侧展示了第一代模型,采用向量循环机制,通过元素级门控更新状态,但由于状态向量的维度有限,难以存储多个竞争性记忆。中间部分展示了第二代模型,通过外积将隐藏状态扩展为矩阵,并引入衰减机制,显著提升了模型容量,但计算复杂度也相应增加。右侧展示了第三代模型,采用Delta规则进行选择性遗忘和写入,通过投影器实现内容的更新,有效缓解了状态拥挤问题,显著提升了长距离回忆能力。这三代模型的更新机制从简单到复杂,逐步解决了线性模型在回忆能力上的瓶颈。
混合架构图
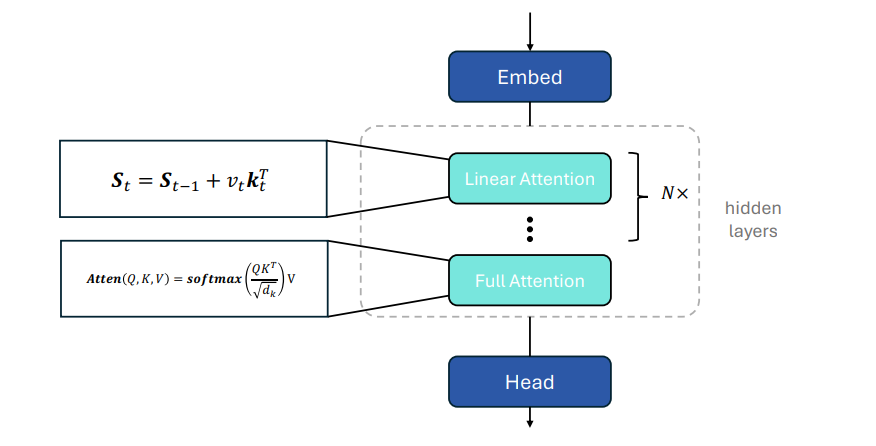
本图描述了本文实验中使用的混合架构。架构由嵌入层、重复的线性注意力层和全注意力层组合块以及投影头组成。线性注意力层负责更新固定大小的隐藏状态,计算复杂度较低,几乎不增加缓存。全注意力层则负责全局token交互,更新KV缓存。通过改变线性与全注意力层的比例(如24:1、12:1、6:1、3:1),研究者分析了不同比例对语言建模和回忆任务的影响。这种混合架构既利用了线性模型的高效性,又通过少量全注意力层提升了模型的回忆能力。
语言建模性能与回忆性能对比图

本图展示了不同线性注意力模型在不同混合比例下的语言建模性能和回忆性能。左侧图显示,语言建模性能在不同混合比例下变化不大,大多数架构的平均分数集中在0.55到0.57之间,表明语言建模对线性与全注意力层的比例不敏感。右侧图显示,回忆性能随着全注意力层比例的增加显著提升,当全注意力层比例达到3:1时,大多数架构的回忆性能接近或超过Transformer基线。这表明回忆任务对全注意力层的依赖性更强,而语言建模任务则对混合比例的容忍度更高。
实验

本表展示了不同线性注意力模型在不同线性与全注意力层比例(linear-to-full attention ratio)下的语言建模性能。这些性能结果是通过对1.3B参数和340M参数两种规模的模型进行平均得出的,从而提供了一个综合的性能评估。表中列出了六种线性注意力模型(DeltaNet、GatedDeltaNet、GLA、HGRN、HGRN2、RetNet)在不同混合比例(24:1、12:1、6:1、3:1以及纯线性模型)下的平均语言建模性能。从表中可以看出,语言建模性能在不同混合比例下变化较小,大多数模型的平均分数集中在0.55到0.57之间。这表明语言建模任务对线性与全注意力层的比例具有较高的容忍度,即使在全注意力层比例较低的情况下,模型仍能保持相对稳定的性能。本表通过详细的实验数据,揭示了线性与全注意力层比例对语言建模性能的影响,为设计高效且性能稳定的混合架构提供了重要的参考依据。
-- END --

关注“学姐带你玩AI”公众号,回复“注意力全新”
领取注意力机制高分论文合集+开源代码



![邀请参会:西门子EDA年度大会[8.28 上海]](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-08-11/68994cd5b85a2.jpeg)







