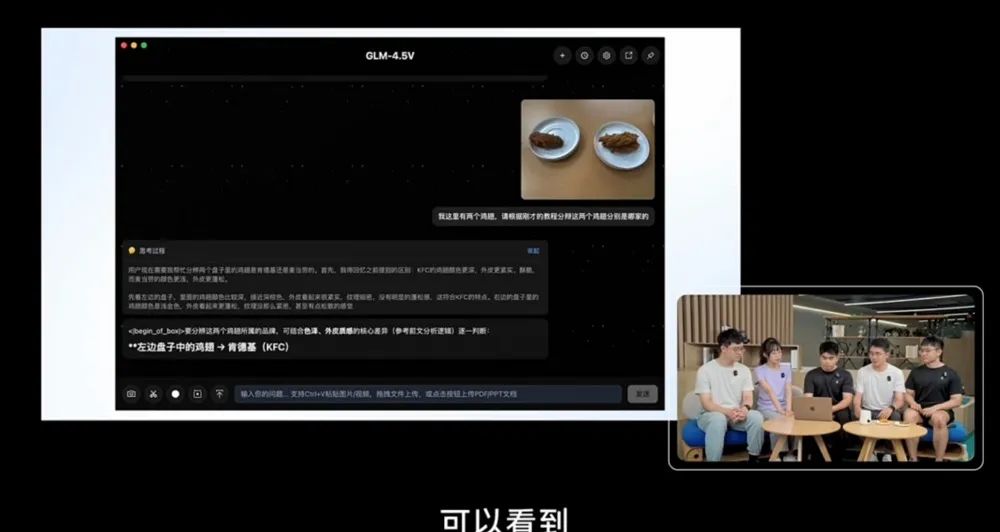
普通用户免费可玩,API有2000万token免费额度。智东西8月11日报道,今晚,智谱开源了其最新一代视觉理解模型GLM-4.5V。这一模型基于智谱新一代文本基座模型GLM-4.5-Air训练而来,延续上一代视觉推理模型GLM-4.1V-Thinking的技术路线,拥有1060亿参数,120亿激活参数。GLM-4.5V还新增了思考模式的开关功能,用户可自主控制模型是否进行思考。这一模型的视觉能力解锁了一些有趣的玩法。例如,模型现在可以看懂麦当劳和肯德基炸鸡翅的区别了,还从炸鸡的色泽、外皮质感等角度,进行了全面分析。GLM-4.5V也可以看图猜地点,智谱称,GLM-4.5V和人类玩家一起参与了拍图猜地点积分赛,加入比赛7天后,GLM-4.5V的积分直接排到了赛事网站的第66名,超越了99%的人类用户。智东西还让这一模型根据网页截图,打造了小红书的同款网页,实现了十之八九的相似度。智谱分享了GLM-4.5V在42个基准测试中的成绩,这些测试覆盖图像、视频、文档理解以及图形界面智能体操作等常见任务。GLM-4.5V在其中41个测试中,得分超过同尺寸模型,如Step-3、Qwen2.5-VL等。目前,这一模型已经在开源平台Hugging Face、魔搭、GitHub发布,并且额外提供了FP8量化版本。智谱为其打造了一个体验App,不过目前仅有Mac端可用(且必须为非Intel芯片)。用户可在z.ai选择GLM-4.5V模型,上传图片或视频进行体验,或在智谱清言APP/网页版,上传图片,开启“推理模式”进行体验。为帮助开发者体验GLM-4.5V的模型能力,智谱同步开源了一款桌面助手应用。该桌面应用可实时截屏、录屏获取屏幕信息,并依托GLM-4.5V处理多种视觉推理任务,日常处理如代码辅助、视频内容分析、游戏解答、文档解读等多类视觉任务。
GLM-4.5V API现已上线智谱开放平台BigModel.cn,并提供了2000万 tokens的免费资源包。其API最低价为每百万输入tokens/2元、每百万输出tokens/6元,支持图像、视频、文件和文本输入。
模型上线后,智东西第一时间对其能力进行了体验,并梳理了这款模型背后的部分技术创新。https://github.com/zai-org/GLM-Vhttps://huggingface.co/collections/zai-org/glm-45v-68999032ddf8ecf7dcdbc102https://modelscope.cn/collections/GLM-45V-8b471c8f97154ehttps://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App
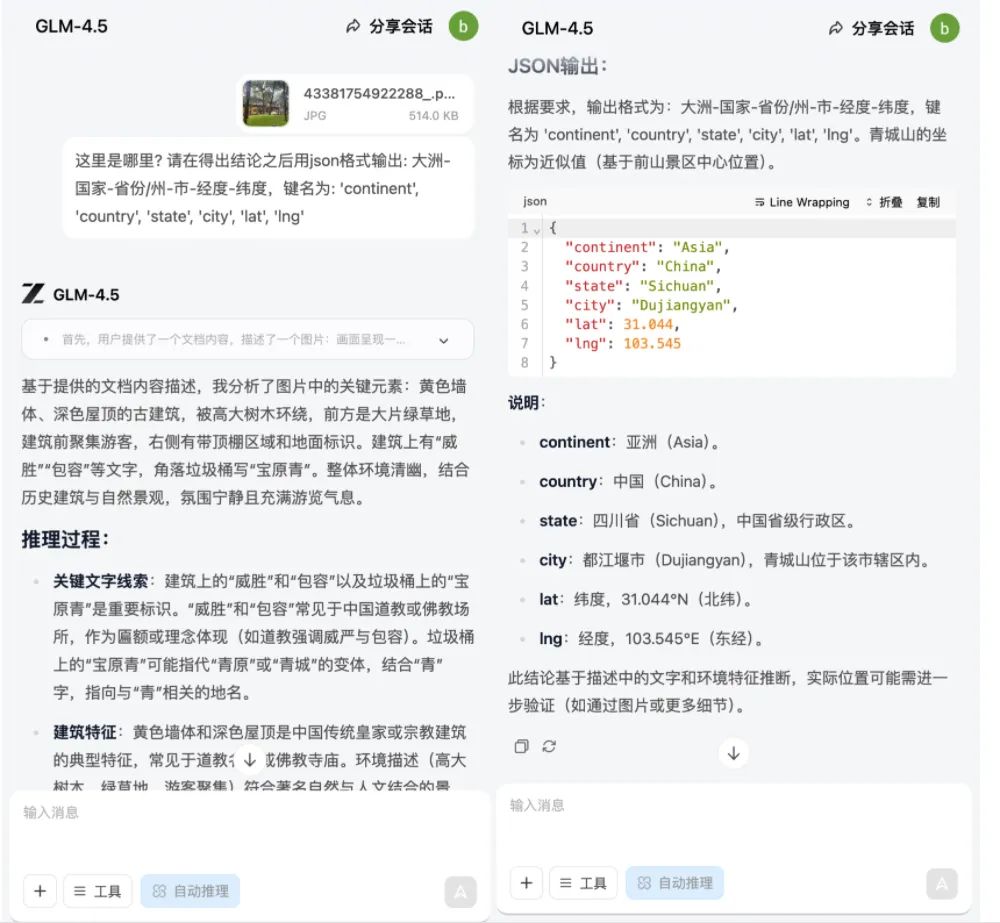
智东西在搭载GLM-4.5V的桌面助手应用中体验了模型的部分功能。这一应用中提供了思考开关等设置,用户还可自定义提示词、模型设置等,提供了较大的自由度。要使用模型,用户需要提供GLM-4.5V的API密钥,可在智谱的开放平台获得。测试中,智东西首先使用了官方提供的一张照片,模型能够准确猜出地点,并按照要求精确到经纬度。随后,我们上传了自己的测试图,选用了一张“灵隐寺一角”的照片,这张图难度不小——画面中虽有黄色墙体、深色屋顶的古建筑、高大树木与游客,但没有明显的地标性信息。右下角的路灯上虽印有“灵隐寺”字样,但因使用的并非简体字,未被系统识别出来。系统在分析中误将路灯上的“灵隐寺”识别为“宝原青”,并将图片上的“感恩”识别成“威胜”,同时捕捉到另一处“包容”字样。结合这些文字与环境特征,系统最终将结果推断为四川都江堰的青城山。虽然未能准确匹配真实地点,但推理过程细节丰富,结果具备一定参考价值。这一模型具备一定的GUI(图形用户界面)能力,这对理解、操作网页或App等Agent场景至关重要。官方Demo中,GLM-4.5V可以帮助用户在眼花缭乱的购物网站截图中,计算出折扣信息,还对生成结果进行反思和确认。智谱的思考与执行智能体AutoGLM最新版,就将使用GLM-4.5V。生产力方面,GLM-4.5V现在可以根据网页录屏、截图等复现前端代码,分析画面中内容、样式、布局等元素,推测背后的代码,然后对交互逻辑进行建模与实现。智东西体验了App端提供的“网页录屏/截图,复现特定功能”能力。用户可在页面上直接点击截屏或局部录屏按钮,将录制的视频上传至系统,由系统进行压缩处理后,推理分析生成对应的HTML代码,渲染可交互的前端。在实际测试中,因访问量可能过大,系统在近50分钟内未返回结果。随后,我们将相同任务提交至智谱官方平台,并以截图形式交给GLM-4.5V,不到10分钟便生成了网页复刻版本。▲智东西实测结果(结果链接:https://chat.z.ai/space/f00sx6s4jgp1-art)
生成的页面在信息呈现上比小红书网页端更丰富——除点赞数外,还额外显示评论数据,并增加了下方功能栏和右上角的通知按钮。但在瀑布流对齐效果上未能还原,缺少小红书“精髓”的布局感。此外,该版本并未实现交互功能,可能是截图内容无法体现动态操作所致,上传视频或许可以改善。智谱官方Demo展示的案例中,工作人员上传了一小段知乎网页版的操作录像,最终GLM-4.5V交付了一个相对完整的网页,点击、跳转、输入等功能都正常运行。如果对网页局部位置不满意,又不知道该如何在代码中定位问题,用户可以直接在网页截图中圈出不满意的位置,模型能直接对背后代码进行修改。在PPT、PDF场景,GLM-4.5V可阅读含有大量图表的复杂长文本,能够对文本进行总结、翻译、图表提取等操作。模型并不是通过OCR实现图像信息提取的,而是直接用视觉方式读取图片,能在一定程度上避免了信息提取过程中的错误传递,对于图表、表格等视觉化、结构化信息的保留和解读准确性得到提升。博客介绍,GLM-4.5V在视觉定位这种传统CV领域表现不错,可以根据用户提问,精准识别、分析、定位目标物体并输出其坐标框。这一能力可运用于安全与质量检查、高空遥感监测分析。相较于传统的基于视觉模型的物体识别,GLM-4.5V 凭借更丰富的世界知识与更强大的语义理解能力,能够通过推理理解更复杂的定位指令。
GLM-4.5V由视觉编码器、MLP适配器和语言解码器三部分组成,支持64K多模态长上下文,支持图像与视频输入,并通过三维卷积提升视频处理效率。
模型采用双三次插值机制,有效增强了模型对高分辨率及极端宽高比图像的处理能力与稳健性;同时,引入三维旋转位置编码(3D-RoPE),显著强化了模型对多模态信息的三维空间关系的感知与推理能力。
GLM-4.5V 采用三阶段策略:预训练、监督微调(SFT)和强化学习(RL)。其中,在预训练阶段,智谱结合大规模图文交错多模态语料和长上下文内容,强化了模型对复杂图文及视频的处理能力。在SFT阶段,智谱引入了显式“思维链”格式训练样本,增强了GLM-4.5V的因果推理与多模态理解能力。最后,RL阶段,模型经历了全领域多模态课程强化学习,通过构建多领域奖励系统(Reward System),结合可验证奖励强化学习(RLVR)与基于人类反馈的强化学习(RLHF),优化了其在STEM问题、多模态定位、Agent任务等方面的能力。
视觉理解一直被认为是Agent与电脑、现实世界等交互的重要能力之一,在纯文本模态之外,Agent还需要理解图像、视频等信息,才能补齐它与人类认知方式之间的差距。智谱本次开源的GLM-4.5V拥有一定视觉理解能力,并在GUI等场景展现出了应用价值,其后续与Agent应用的结合,值得期待。(本文系网易新闻•网易号特色内容激励计划签约账号【智东西】原创内容,未经账号授权,禁止随意转载。)