
► 文 观察者网 吕栋
GPT-5的不再惊艳,让很多人意识到传统的Scaling Law(尺度定律)已经遇到明显瓶颈。从应用需求的角度来讲,更多企业开始关注模型推理的性能体验,这关乎商业落地和变现。
但在推理这个关键环节,中国正遭遇瓶颈。不仅基础设施投资远少于美国,同时还要面对算力卡阉割、HBM(高带宽内存)涨价禁运等困境。尤其是,随着AI应用场景不断拓展,长文本处理、多轮对话以及复杂业务流程的推理需求日益增长,更让中国AI推理困境凸显。
现实挑战下,华为重磅推出了AI推理加速“黑科技”UCM(推理记忆数据管理器,Unified Cache Manager)。这一突破性技术通过创新架构设计和存储优化,突破了HBM容量限制,提升了国内AI大模型推理性能,完善了中国AI推理生态的关键环节。

在英伟达因“后门”遭遇信任危机之际,华为将UCM主动开放开源,打通了框架、算力、存储三层协同,推动国产AI推理告别“堆卡依赖”,走向“体验提升-用户增长-企业加大投资-技术迭代”的正循环。这场围绕“记忆”的技术突围,或许正是中国AI行业落地的关键一役。

推理已成关键,中国瓶颈凸显
AI技术的蓬勃发展,让大模型训练成为成本中心,但真正创造价值的是推理过程。
数据显示,当前AI推理算力需求已超过训练。GPT-5开放首周API调用量超20亿次/分钟,70%的请求为复杂认为推理(如代码生成、多步规划等),而国内火山引擎的日均token调用量已达16.4万亿,70%以上来自线上推理而非训练。
推理性能关乎用户体验和商业可行性,已成为AI落地的关键。但随着AI行业化落地加深,推理能力也不断面临挑战,尤其是在长文本处理、多轮对话以及复杂业务流程的推理需求日益增长的情况下,对推理性能的要求愈发严苛。
在此背景下,一种名为键值缓存(KV Cache)的关键技术诞生,它可以优化计算效率、减少重复运算,即将已生成token的Key(键:表征历史输入的特征)和Value(值:基于Key的特征,用于生成当前输出的参考信息)临时存储起来,后续生成新token时直接复用,无需重新计算,可以显著提升推理效率。
但问题是,KV Cache需要占用GPU的显存(如高带宽内存HBM)存储历史Key/Value向量,生成的文本越长,缓存的数据量越大,有可能导致HBM和DRAM被挤爆。
中国企业不比美国,一方面中国互联网企业在AI基础设施上的投资只有美国的十分之一,中小企业预算少,买不起那么多高端的HBM,另一方面中国还面临出口管制,无法获得最先进的算力卡和HBM,不可能无限制地去堆卡。
更关键的是,面对大模型PB级的天量数据,传统推理架构过度依赖HBM的瓶颈也日益凸显。随着Agentic AI(代理式人工智能)时代到来,模型规模化扩张、长序列需求激增以及推理任务并发量增长,推理的KV Cache容量增长已超出HBM的承载能力,频繁的内存溢出,导致推理频繁出现“失忆”,需要GPU反复计算,造成卡顿迟缓。
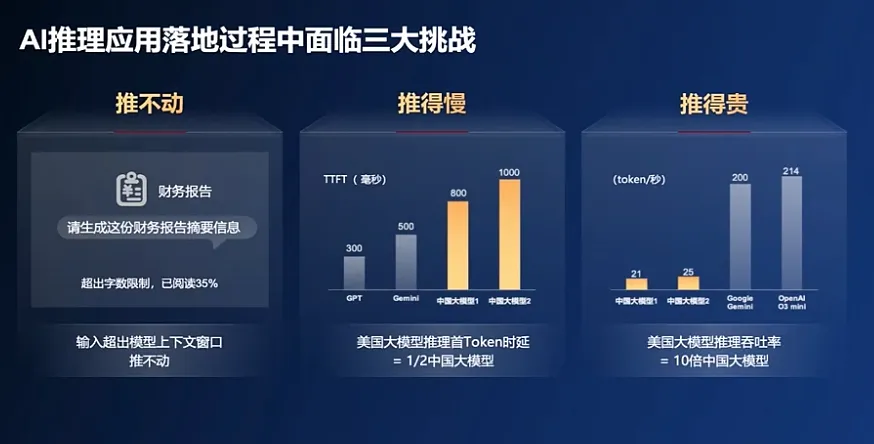
多种难题下,国产大模型陷入了“推不动”、“推得慢”和“推得贵”的困境。
数据显示,国外主流大模型输出速度为200 tokens/s区间(时延5ms),而中国普遍小于60 tokens/s(时延50-100ms),最大差距达到10倍。在上下文窗口上,海外模型普遍支持100万级Token(如GPT-5、Claude 3.5),而国内头部模型(Kimi)仅50万,且在长文本分析中,国内模型遗漏关键信息的概率超50%。

这种体验,显然对中国AI的规模化落地不利。长此以往,甚至会形成商业的恶性循环,进一步导致中国企业投入降低、投资降速,在AI的国际竞争中被国外拉开差距。
怎么在不大幅增加算力基础设施投入的前提下,显著优化推理体验,推动AI推理进入商业正循环,成为中国的当务之急。

华为“黑科技”,打通推理体验堵点
前面提到,“Token经济”时代,KV Cache与记忆数据管理是优化推理性能、降低计算成本的核心,但HBM这种高性能内存太贵,且不能无限制堆卡,而SSD(固态硬盘)的传输速率太慢,似乎形成了成本、性能和效果的“不可能三角”。
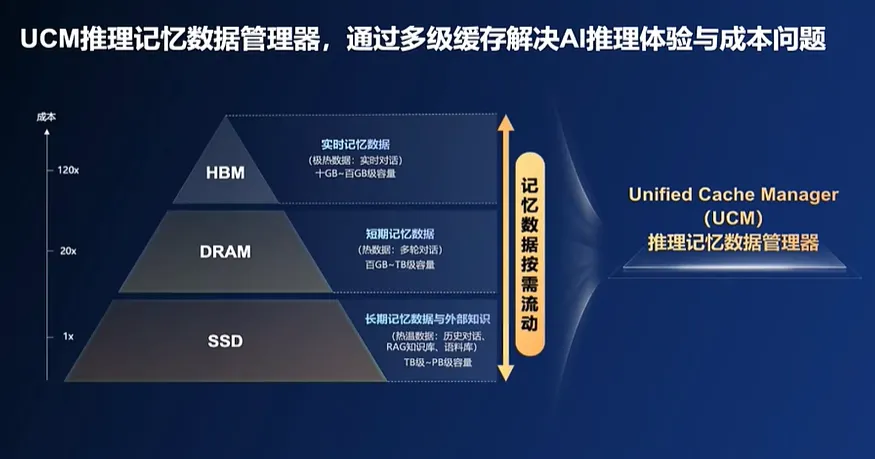
那能不能根据记忆热度,在HBM、DRAM、SSD等存储介质中分级缓存数据,让模型能记住的KV Cache数据更多,同时能更智能、更快速的调用数据?就像人类一样,可以把“记忆”放在大脑、书本和电脑等不同地方,按需快速调取。
华为这次推出的“黑科技”UCM就是类似的思路。
UCM的全称是“推理记忆数据管理器”(Unified Cache Manager),它是一款以KV Cache为中心的推理加速套件,融合了多类型缓存加速算法工具,可以分级管理推理过程中产生的KV Cache记忆数据,扩大推理上下文窗口,以实现高吞吐、低时延的推理体验,降低每Token推理成本。
比如为了解决“推得慢”的问题,UCM将历史已处理过的结果、历史对话、语料库、RAG知识库的数据以KV Cache的形式缓存至第三层的高性能外置共享存储上,遇到已推理过、已缓存过的信息不用再重新推理,而是只用从外置存储中查询并调用即可,实现大幅推理加速,将首token延迟降低90%,也节省了token by token的时间。
有了这种能力,大模型还可以记住更多的历史内容和对话,不用再“重复劳动”,以前生成内容需要10秒,现在可能1秒就能搞定,显著改善推理体验。
这还不是这项“黑科技”的全部。
关注大模型的都知道,随着推理任务越来越长,长序列推理让大模型常常“只有七秒钟记忆”,比如在分析一篇万字长文时,由于HBM容量有限,缓存到前2000字可能就装不下了,这就容易出现推理失败、关键关联信息丢失的情况,形成“推不动”的困境。
华为是如何解决的?
UCM通过一系列智能算法突破,对长序列内容进行切片,并把已处理的切片卸载到更大的DRAM或外置共享存储,相当于扩充了HBM的容量,让上下文窗口扩大10倍、满足长序列推理需求。换言之,模型的“记忆能力”从“记3页纸”提升至“记30页纸”。

更关键的是,华为采用了注意力稀疏及相关技术,可以识别大量KV Cache数据的重要程度、相关性和热度,将重要的/不重要的、相关的/不相关的数据,分层分级地进行缓存并流动。在下一次推理过程中,只需要把关键的、合适的向量提取出来即可,这也就降低了向量推理过程中向量的数量,提升整体吞吐量。
“面向推理加速的KV数据,一定会有热/温/冷,不可能都用最贵的介质,去存储所有数据。我们做存储系统有很深的体会,每类数据都有这个特征,都有一个生命周期,一定会用多层介质解决性能问题,又平衡成本问题。”华为技术专家对观察者网说道。
在存算协同能力深度加持下,通过多层介质平衡性能和成本,“推得贵”也不再是难题。华为表示,无需过多投资,UCM就可以让长序列场景下TPS(每秒处理token数)提升2-22倍,相当于降低每Token推理成本,为企业减负增效。

UCM的意义,更像是华为的另一种“系统补单点”,它不是为了取代HBM,而是降低了对HBM的依赖,把HBM的优势发挥在更合适的地方。
在这种技术加持下,企业可以维持算力投入不变,仅花销小部分外置存储的投资,让缓存原地“升级”,改善推理效率、摊薄每token推理成本,进而形成“用户流量增大-企业收益-进一步扩大AI投资-技术快速迭代”的正循环,拉动中国整体AI水平提升。

联合创新,验证技术价值
任何技术只有真正落地才能产生价值。华为UCM推出后,已经携手中国银联率先在金融典型场景开展UCM技术试点应用。
为什么会率先选择金融场景?
华为技术专家告诉观察者网,金融行业大模型推理有三个核心难题。首先是“推不动”,无论生产环境的投研分析,还是舆情分析,都会涉及非常多的长序列输入,像一份投研报告可能就是上兆级别的,精准营销需要输入的上下文基本也是长序列,容易出现关键信息丢失;其次是“推得慢”,核心是并发上不去,上去之后每token时延特别长;最后“推得贵”,原因是需要耗费大量的算力,做KV Cache的重复计算。

“难题是长序列推理,我们与客户的对话时长非常长,转化成文字之后会形成大量历史对话和内容,通过KV Cache的方式会挤占我们的显存,瓶颈就变成了显存,因为我们要缓存大量的KV Cache,但是我们显存有限。”中国银联相关负责人说道。
于是,华为和中国银联开展了UCM技术联合创新。一方面是将计算过的KV Cache数据,从显存分片卸载到内存和存储,缓解显存的压力,使其能处理更长序列的数据;另一方面是使用注意力稀疏技术,让大模型可以区分KV Cache缓存中,有哪些数据是和这次推理相关度最高的,只要把关键的向量获取出来,就可以降低推理时间,提高吞吐量。
就是在这种联合创新技术试点中,UCM的技术价值得到了充分验证。
在中国银联“客户之声”业务场景下,借助UCM技术及工程化手段,大模型推理速度提升125倍,仅需10秒即可精准识别客户高频问题。在“营销策划”场景中,过去需要数分钟才能生成一份的营销策划案,现在缩短至10秒以内,且单台服务器可支持超过5名营销人员同时在线协作。而在“办公助手”场景中,对于超过17万Token的超长会议语音进行转写和纪要生成,借助UCM也能轻松应对,摆脱了“推不动”的困境。

那UCM未来能否应用到其他场景,助推AI落地千行百业?华为技术专家给出肯定答复。
“随着Agentic AI时代到来,信息量爆炸,体现在模型侧是显存不足以及推理Token成本的问题。UCM方案是去解决这一类的问题,不是一个单点,只是在金融行业首先应用起来,未来在各行各业一旦AI发挥真正的价值,都会走向这个领域。”他对观察者网说道。

填补生态短板,华为再度开源
随着推理性能的重要性不断提升,业界其实也都在探索KV Cache分级缓存管理技术。比如英伟达今年5月就推出了分布式推理服务框架Dynamo,支持将KV Cache缓存从GPU内存卸载到CPU、SSD甚至网络存储,解决大模型显存瓶颈,避免重复计算。
但当下英伟达正陷入“后门”风波,信任危机下,行业更呼唤中国方案。

“分级缓存管理很多人在做,UCM最大的差异化是将专业的存储纳入进来。”华为技术专家对观察者网表示,华为通过大量的软硬协同和卸载,比如KV检索的索引和KV Cache生命周期管理等,构建了在分级缓存管理上的差异化能力,“业界很多方案在算法加速库这一层只有传统的Prefix Cache,并没有像今天这样去商用全流程地稀疏、后缀检索算法以及其他一系列的算法,所以中间的算法库上面,我们相对业界贡献了非常多、更加丰富、更加可靠、加速效果更好的算法,并且这个算法库还在持续增加当中。”
关注大模型的可能都知道,华为之前开源了AI框架MindSpore,近期又开源了对标英伟达CUDA的神经网络异构计算架构CANN,而这次华为再度宣布,将在9月开源UCM。
从架构上看,华为的UCM解决方案主要有三大组件构成:对接不同引擎与算力的推理引擎插件(Connector)、支持多级KV Cache管理及加速算法的功能库(Accelerator)和高性能KV Cache存取适配器(Adapter),实现了推理框架、算力、存储三层协同。

通过开放统一的南北向接口,UCM可适配多类型推理引擎框架、算力及存储系统。对于推理引擎框架开发者而言,UCM开放的接口使得他们能更方便地将UCM技术集成到自己的框架中,提升框架性能和竞争力;对于算力及存储系统厂商来说,UCM的开源提供了新的发展机遇,促使他们研发更适配的产品和解决方案,以更好地与UCM协同工作。
“我们并不希望控制这个框架,或者在框架上构建差异化的能力控制什么,我们希望这个生态能够繁荣起来,真正解决AI推理化的问题,华为的UCM今天推出来以后,在整个推理框架、推理体验生态、成本方面贡献了一份力量,未来相信会有更多的玩家在里面做贡献,是一个大家共创繁荣的过程。”华为技术专家对观察者网表示。
从更长远的意义来看,华为推出UCM并开源,仍是系统工程的胜利,将推动中国AI产业进入“体验提升-用户增长-投资加大-技术迭代”的良性商业正循环。它并不是为了替代什么,而是要打通AI行业化落地的关键堵点,为中国AI产业的长远发展注入更强的动力。













