复盘历史——更智能、更快捷、更便宜
自 2022 年 11 月 GPT-3.5 发布以来,生成式 AI 逐渐从专业领域走向大众视野。进一步,GPT-4 多模态功能的推出和英伟达 H 系列芯片的起量,使得2023 年被视为人工智能产业的重要转折点。海外大模型追求智能化升级。自 2023 年以来,OpenAI、Anthropic、Google、Meta、xAI 等海外大模型厂商保持每半年一代的迭代速度,通过算力扩充和算法优化来持续推动产品智能化升级和丰富度提升。
DeepSeek 推动国产大模型崛起。在芯片制裁的扼制下,2023-2024 年的国产大模型迭代缓慢。但随着 DeepSeek-R1 的横空出世,2025 年开始国产大模型迭代提速,产品丰富度显著提升,但资本开支热情仍弱于海外。
算力的扩充规模决定了大模型智能化的上限,海外大模型厂商持续加大AI资本开支来保障其产品的领先性。根据 Marvell 指引,2025-2028 年全球AI 算力资本开支仍将保持 20%的年均增速成长。
北美主要大模型厂商的资本开支情况
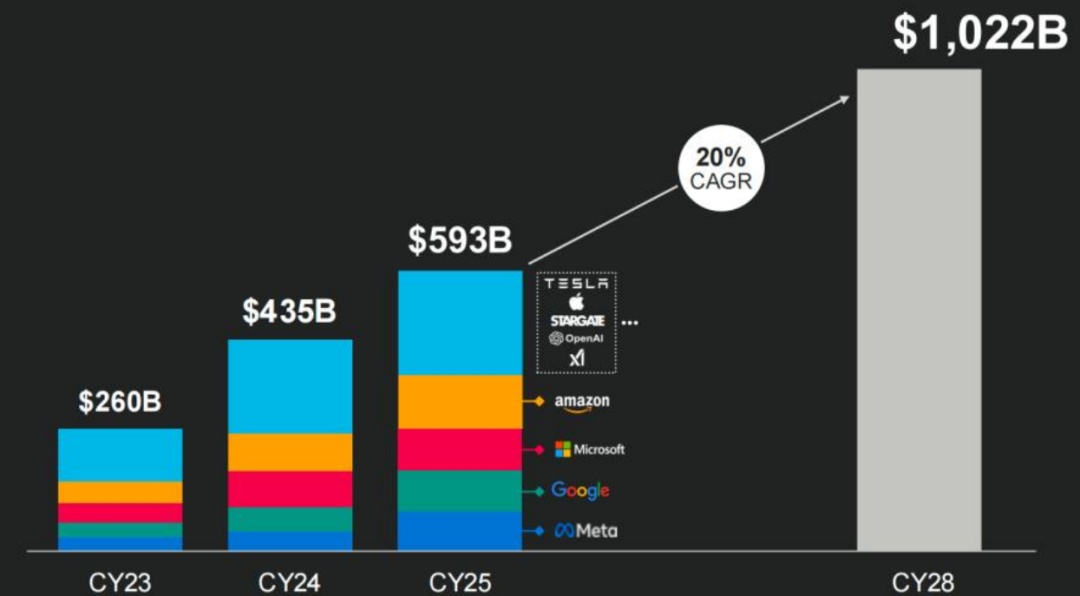
资料来源:Marvell,国信证券经济研究所整理
2024Q2 是国产算力资本开支的低谷,自 2024Q3 开始,腾讯和阿里的资本开支显著提速。然而,受制于 H20 进口限制,2025Q1 国产厂商资本开支有所下调,但同比仍显著增长。
“算力→大模型→终端软/硬件”是 AI 产业链闭环的核心途径,AI agent是大模型和终端之间的桥梁。
2025 年海外 AI agent 仍处于初步商业化阶段。1)产品化(2023 年):OpenAI和 Meta 等推出具有人机交互功能的 AI 产品;2)初步商业化(2024-2025年):在 2024 年,GitHub、Salesforce 等根据细分行业需求推出垂类AI agent产品。在 2025 年,特斯拉、Apple、微软对现有的车、手机、办公软件进行AI化升级,但 AI 产品仍处于起量初期、产品成熟度欠佳。3)规模商业化(2026 年开始):AI 手机、robotaxi、AI 软件产品日益成熟,预期将逐步进入显著放量阶段。
2025 年国产 AI agent 落地较慢。1)产品化(2023 年):百度和阿里等效仿海外厂商推出类似的具有人机交互功能的 AI 产品;2)初步商业化(2024-2025年):在 2024 年,飞猪(阿里)、字节、华为等针对其现有业务需求推出垂类AIagent产品。在 2025 年,百度、小米、理想等延续 2024 年的方式对其现有产品进行AI化迭代。3)规模商业化(2026 年开始):国产 AI agent 仍在等待海外AI产业的成功范例。
立足当下(算力端)——算力发展方兴未艾
愈发“才思敏捷”的人工智能需要更强的算力支撑,而算力的升级并不局限于芯片制程升级,而是机柜级、集群级的整体化技术迭代。为了突破集群算力的瓶颈,互联技术沿着 Scaleout(集群级升级)和 Scaleup(机柜级升级)两个方向发展。
从芯片来看,以英伟达的芯片技术路径为例,更大的存储量、更强的稠密算力能力、更快的带宽速度是算力芯片一直以来的迭代方向。
从机柜来看,随着 AI 资本开支规模的持续上涨,人工智能软/硬公司愈发倾向于本地化部署算力,因此更一体化、更具性价比的算力部署单元更获得青睐,超节点需求应运而生。自 B 系列以来,GB200 开辟了 AI 算力超节点时代,单机柜算力升级向超节点模式发展,且超节点带动液冷、铜缆等技术的升级。
从集群来看,随着大模型参数的持续扩张,算力集群规模越来越大。128节点的超级集群可由 32 个叶交换机和 16 个脊交换机构成,且交换机间需要较高的传输速度来满足快速通信需求。为了满足日益提升的传输速度需求,CPO 技术和PCB材料的升级成为重要方向。
立足当下(模型端)——Scaling-law 仍在延续
自 DeepSeek-R1 推出以来,叠加海外高端算力芯片禁运仍在持续,一方面国产大模型寻觅到了用中低端算力即可实现大模型迭代的途径,另一方面国产大模型仍难超越海外头部大模型厂商的智能化进度。在这种形势下,海外大模型厂商坚定通过算力资本开支扩张来实现大模型智能化升级,而国产大模型厂商将重心放在应用端的商业化落地。
海外大模型智能化竞赛加剧。Anthropic 于 2025 年5 月23 日推出ClaudeOpus4和 Claude Sonnet 4,代表了人工智能在推理、编码和多模态处理领域的顶尖水平,其相对于 Claude 3.7 和 GPT-4.1 在智力方面都有更突出的表现。
大模型细分化趋势显著。OpenAI GPT-4.1 是 2025 年4 月15 日推出的模型系列,该系列包含 GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano 三款子模型,在编程、指令遵循和上下文理解方面表现突出,标志着 AI 模型从“通用能力扩张”向“场景化深度优化”的战略转型。其中,GPT-4.1 为旗舰级全能模型,在智能性、创造力和复杂任务处理方面表现卓越;GPT-4.1 mini 为中型模型,是性价比较高的选择;GPT-4.1 nano 是三者中最小、最快的模型,在轻量级任务上表现出色。
国产大模型更加重视多模态。受制于芯片制裁的固有限制,叠加传统互联网的价格竞赛模式,国产大模型具有三大特点:(1)To C 端大模型免费,注重产品化体验。(2)不过分追求智能化水平,重视多模态发展。(3)重视轻量化模型,对垂直领域的适配性更强。
更多行业研究分析请参考思瀚产业研究院官网,同时思瀚产业研究院亦提供行研报告、可研报告(立项审批备案、银行贷款、投资决策、集团上会)、产业规划、园区规划、商业计划书(股权融资、招商合资、内部决策)、专项调研、建筑设计、境外投资报告等相关咨询服务方案。

 关 于 我 们
关 于 我 们 
·官方网站: Chinasihan.com










