
在今年的 CoRL (Conference on Robot Learning)会议上,共有 42 篇 Oral 论文脱颖而出(仅占总投稿的 5% 左右),涵盖了操作与模仿学习、感知、规划与安全、运动控制、人形与硬件五大主题。

▲官网链接见文末
在本文中,我们挑选了17 篇已经公开的研究进行盘点,内容横跨人形机器人、腿足机器人、大模型驱动的操作、多模态感知,以及安全与鲁棒规划等多个方向。
希望帮各位读者快速了解 CoRL 2025 的核心成果,并理清机器人学习领域正在发生的技术脉络。

人形机器人与硬件创新
聚焦人形机器人控制、外骨骼系统、智能皮肤等,探索硬件与学习结合的前沿。
AirExo-2: Scaling up Generalizable Robotic Imitation Learning with Low-Cost Exoskeletons
研究机构:上海交通大学、上海穹彻智能科技有限公司
主要内容:在机器人模仿学习中,采集高质量的人类演示是关键。但传统遥操作设备成本高且场景受限,而“野外”采集又面临视角不足、域差距过大等问题。
为此,研究者提出了 AirExo-2 ——一套低成本外骨骼系统,可以在日常环境中大规模采集人体操作数据,并通过一系列适配器将其转化为伪机器人演示。基于这些数据,他们进一步设计了 RISE-2 策略,将三维空间感知与二维语义信息融合,提升机器人在复杂操作中的鲁棒性。
实验显示,RISE-2 在泛化评测上超越现有方法,且仅依赖 AirExo-2 采集的数据,其表现已接近传统遥操作训练的效果。这一成果为可扩展、低成本的模仿学习提供了新路径。

▲图1|对 AirExo-2 系统和 RISE-2 策略的概述:AirExo-2 能够实现大规模的演示收集与适应。视觉适配器将这些内容转化为伪机器人演示,用于训练。通用的 RISE-2 策略仅通过这些数据即可学习,并能在真实的双臂机器人上实现零样本部署,其性能与基于远程操作机器人数据训练的策略相当©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2503.03081
项目地址:https://airexo.tech/airexo2/
HuB: Learning Extreme Humanoid Balance
研究机构:清华大学、上海期智研究院、加州大学伯克利分校、加州大学圣地亚哥分校
主要内容:人类能轻松完成单脚站立、凌空高踢等高难度动作,但对人形机器人而言,这类平衡密集型技能一直是难点。
研究团队提出了 HuB 框架,针对三大挑战:参考动作误差带来的不稳定、机器人形态与人类差异导致的学习困难、以及感知噪声带来的仿真到现实落差。
HuB 通过动作修正、平衡感知策略学习和鲁棒训练模块逐一应对这些问题。在 Unitree G1 上的实验表明,该方法能稳定完成“燕式平衡”、“李小龙踢腿”等极限姿态,甚至在强烈干扰下依然保持稳定,而对比方法则频繁失败。
该研究展示了人形机器人向复杂运动控制逼近人类水平的重要一步。

▲图2|极端平衡任务演示:HuB使类人机器人能够执行极端准静态平衡任务具有高稳定性。(a)燕子平衡:保持一个具有挑战性的t形姿势,躯干伸展水平;(b)李小龙的踢腿:在保持单腿平衡的同时,用全腿伸展来执行高踢腿脚;(c)哪吒姿势:一种受武术启发的抬起手臂的单腿姿势;(d)高膝盖;(e)单腿站;(f)深蹲©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2505.07294
项目地址:https://hub-robot.github.io/
Visual Imitation Enables Contextual Humanoid Control
研究机构:加州大学伯克利分校
主要内容:如何让人形机器人学会上下楼梯、坐椅子等带有环境上下文的技能?
研究者提出了 VIDEOMIMIC,一种“视频到仿真再到现实”的模仿学习流程。方法首先从日常视频中自动重建人类与环境信息,然后在仿真中训练机器人全身控制策略,最后迁移到现实机器人执行。
这样一来,普通生活视频即可成为机器人技能学习的“教科书”。实验展示了多样化成果:机器人能稳定完成上下楼梯、坐立、以及其它全身动态动作,并且所有能力由一个统一策略管理。
VIDEOMIMIC 展示了一条低门槛、可扩展的人机知识迁移路径,为人形机器人在现实环境中的多技能学习打开了新可能。

▲图3|VIDEOMIMIC是一个real-sim-real的方法,可以将单目视频转换为可迁移的类人技能,让机器人学习情景感知行为(穿越地形、爬楼梯、坐)单一的策略©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2505.03729
项目地址:https://www.videomimic.net/
DexUMI: Using Human Hand as the Universal Manipulation Interface for Dexterous Manipulation
研究机构:斯坦福大学、哥伦比亚大学、摩根大通人工智能研究、卡耐基梅隆大学,英伟达

▲图4|DexUMI利用可穿戴设备将灵巧的人类操作技能转移到各种机器人手上外骨骼和数据处理框架。DexUMI可以有效作用于欠驱动和全驱动机器人手,用于各种操作任务©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2505.21864
项目地址:https://dex-umi.github.io/
相关阅读:破天荒!五家顶尖机构联合发布 | 可穿戴外骨骼 + 视觉合成:机器人Ctrl C人类的精细操作

腿足机器人与运动控制
涉及腿足机器人感知、力控制、策略泛化与 Sim2Real 迁移。
Omni-Perception: Omnidirectional Collision Avoidance for Legged Locomotion in Dynamic Environments
研究机构:香港科技大学(广州)、香港科技大学、清华大学、北京人形机器人创新中心有限公司
主要内容:在复杂 3D 环境中,传统基于深度的感知方法容易受噪声、光照和非平面障碍影响,性能受限。
本文提出 Omni-Perception,一种直接处理原始 LiDAR 点云的端到端腿足机器人控制策略,实现了三维空间感知与全向避障。其核心模块 PD-RiskNet 能够解释时空点云,进行风险评估。
作者还开发了高保真 LiDAR 仿真工具包,支持 Isaac Gym、Genesis、MuJoCo 等平台,实现大规模训练与高效 sim-to-real 迁移。
实验结果显示,该方法在动态复杂场景中展现出强大的避障和运动性能,优于依赖中间地图的传统方案,并已开放代码和模型。

▲图5|全感知框架的验证方案:在左侧展示了有效的全方位避碰,机器人对来自各种接近向量的障碍物做出反应。鲁棒性右侧展示了不同的环境特征,包括成功地跨越空中、透明、细长和地面障碍。这些结果突出了全感知的实现能力直接从原始激光雷达输入在具有挑战性的3D环境中进行无碰撞运动©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2505.19214
项目地址:https://github.com/aCodeDog/OmniPerception
相关阅读:「全向避障」最新范式!港科大&清华:基于纯 LiDAR 点云数据,重构四足机器人空间认知!
Learning Unified Force and Position Control for Legged Loco-Manipulation
研究机构:北京通用人工智能研究院、北京邮电大学
主要内容:现有视觉运动控制多聚焦于位置或力控制,忽视二者的协同。
本文提出首个无需力传感器的统一位置-力控制策略,通过在仿真中组合位置/力指令与扰动,利用强化学习学习从历史状态估计力,并通过位置与速度补偿。该策略支持跟踪、施力、顺应等多样操作任务,在四类复杂操作中相比传统位置控制成功率提升约 39.5%。
此外,该策略能增强基于轨迹的模仿学习效果。实验验证了其在四足与人形机器人上的鲁棒性与多样性。

▲图6|这篇文章提出了一种统一的力-位置策略,可实现多种移动操作行为,包括位置跟踪、力施加和柔性交互(上)。当用于模仿学习数据收集时,策略的学习内力估计器提供力觉演示,在无接触的富任务中提高模型性能依靠力传感器(中)。四足机器人和类人机器人的实验结果证明了这一点策略的多功能性和稳健性(下)©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2505.20829
项目地址:https://unified-force.github.io/
FACET: Force-Adaptive Control via Impedance Reference Tracking for Legged Robots
研究机构:清华大学、上海期智研究院、上海人工智能实验室
主要内容:学习型腿足控制常忽略力反馈,导致刚性过大、危险行为频发。
本文提出 FACET,受阻抗控制启发,训练机器人模仿虚拟质量-弹簧-阻尼系统,使其能在外力下展现柔顺性与鲁棒性。实验表明,四足机器人在遭受 200 Ns 冲击时仍能稳定恢复,碰撞冲击降低 80%。
在实机测试中,机器人表现出可控的顺应性,并能通过人机协同完成牵引等大力任务。该方法还成功推广到腿足操作机器人和人形机器人,展示了全身顺应控制的潜力。

▲图7|受阻抗控制的启发,FACET通过模仿参考弹簧-质量-阻尼器模型(b),实现了四足机器人的任务空间可变柔度和力自适应控制强化学习。高顺应性允许机器人停止或运动 (a),而高刚度允许机器人在推/拉时施加大的力有效载荷(b),该框架适用于不同的形态和更复杂的配置(c)。©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2505.06883
项目地址:https://facet.pages.dev/#/
Sampling-Based System Identification with Active Exploration for Legged Robot Sim2Real Learning
主要内容:现实与仿真差异(sim-to-real gap)严重制约高精度任务。
本文提出 SPI-Active 框架,通过两阶段流程缩小差距:首先利用大规模并行采样估计关键物理参数,减少状态预测误差;其次引入主动探索策略,最大化 Fisher 信息,以优化数据收集。该方法无需可微分动力学或直接力矩测量,适用于接触复杂的腿足系统。
实验证明 SPI-Active 在多种 locomotion 任务上实现了 42–63% 的性能提升,显著提高策略迁移的准确性与泛化能力。

▲图8|SPI-Active实现了跨不同运动任务的高保真模拟到真实迁移。强调在保证精度的前提下,所有任务均为开环跟踪,无需全局位置反馈。(a)高速绕障导航,(b)精确向前跳跃,(c)精确偏航跳跃,(d)人形精确速度跟踪©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2505.14266
项目地址:https://lecar-lab.github.io/spi-active_/

操作与模仿学习
代表机器人学习的核心方向,涵盖大模型驱动、语言引导、数据生成及协作操作。
π0.5:a Vision-Language-Action Model with Open-World Generalization
研究机构:Physical Intelligence
主要内容:大名鼎鼎的π0.5想必大家都不陌生了,要让机器人真正有用,它们必须能在实验室之外完成实际任务。现有的视觉-语言-动作(VLA)模型虽然在端到端控制上表现惊艳,但能否在复杂的真实环境中泛化仍是未解之题。
π0.5在π0的基础上提出了一种新的框架,通过在多样化任务上的协同训练,实现了广泛的泛化能力。该方法结合了来自多机器人平台的数据、高层语义预测、网页数据等多模态来源,并通过图像观测、语言指令、物体检测、语义子任务预测与低层动作的混合示例进行训练。实验结果表明,这种跨任务知识迁移对于提升泛化至关重要。
更重要的是,系统首次展示了机器人在全新家庭环境中,能够端到端完成诸如厨房或卧室清洁等长时序、灵巧的操作任务,为通用型机器人学习迈出了关键一步。

▲图9|π0.5模型从异构数据源迁移知识,包括其他机器人、高级子任务预测、口头指令、和来自网络的数据,以实现跨环境和对象的广泛泛化。π0.5可以控制移动机械手清洁厨房和训练数据中不存在的新房卧室,执行持续10至15分钟的复杂多阶段行为©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2504.16054
项目地址:https://arxiv.org/pdf/2504.16054
相关阅读:π0.5泛化真的强吗?(伪代码篇)VLA模型深度解析:从预备知识到训练方法
ReWiND: Language-Guided Rewards Teach Robot Policies without New Demonstrations
研究机构:南加利福尼亚大学、亚马逊的机器人研发部门、韩国科学技术院
主要内容:现有强化学习与模仿学习通常依赖每个任务的人类示范或奖励函数,难以扩展。
ReWiND 通过一个小规模示范集学习语言条件奖励函数,并结合离线RL预训练策略,实现对新任务的快速适应。在仿真和真实双臂操作中,ReWiND显著提升了奖励泛化与策略对齐指标,样本效率优于基线2–5倍,为大规模可扩展机器人学习提供了新路径。

▲图10|ReWiND从一组小的语言标签中预训练一个策略和奖励模型。通过语言引导的强化学习解决未见过的任务变化,而不需要额外的演示©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2505.10911
项目地址:https://rewind-reward.github.io/
Real2Render2Real: Scaling Robot Data Without Dynamics Simulation or Robot Hardware
研究机构:加利福尼亚大学伯克利分校、丰田研究院
主要内容:大规模机器人学习依赖海量数据,但人工远程操作收集成本高昂。
R2R2R提出了一种新颖框架:仅需智能手机扫描和一次人类演示视频,即可通过3DGS重建物体几何与运动,渲染数千条高保真机器人演示。生成数据可直接用于VLA模型和模仿学习策略,实验证明其效果可媲美150条人工演示,大幅降低了数据采集门槛。

▲图11|Real2Render2Real为“把杯子放在咖啡机上”任务生成机器人训练数据。首先以多视角物体扫描和单目人体演示视频为输入。然后通过并行渲染合成不同的、领域随机的机器人执行,并输出成对的图像动作数据用于策略训练©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2505.09601
项目地址:https://real2render2real.com/
相关阅读:不碰真机也不仿真?(伪代码)伯克利最新:仅用一部手机,生成大规模高质量机器人训练数据!
Latent Theory of Mind: A Decentralized Diffusion Architecture for Cooperative Manipulation
研究机构:新加坡国立大学、斯坦福大学
主要内容:多机器人协作操控常依赖集中式控制,缺乏分布式泛化能力。
LatentToM提出了一种去中心化扩散策略,让每个机器人同时维护自我嵌入与共识嵌入,并通过“潜在心智”机制预测伙伴的意图。训练中引入基于sheaf理论的一阶上同调损失来对齐共识嵌入,同时保留表达能力。
实验证明,该方法无需显式通信即可实现高效协作,在硬件测试中优于分布式基线,并接近集中式策略水平。
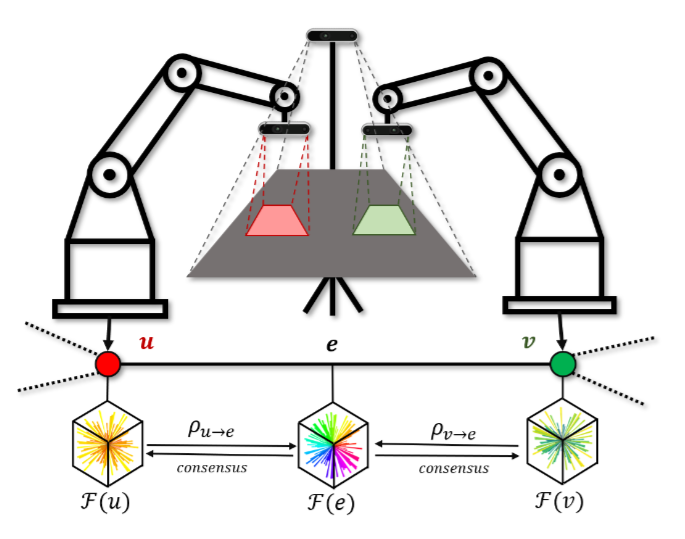
▲图12|在作者的设置中,系统由两个机械臂组成,每个机械臂配有末端执行器和相机,红色和绿色区域表示它们各自的视野。此外,第三人称摄像机观察元素之间的重叠工作区,用灰色表示。该方法可以让多机器人不建立显式的通讯就达成高效的协作©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2505.09144
项目地址:https://stanfordmsl.github.io/LatentToM/

感知与多模态融合
聚焦视觉-触觉融合、生成式 3D 感知和复杂场景下的抓取。
SAVOR: Skill Affordance Learning from Visuo-Haptic Perception for Robot-Assisted Bite Acquisition
研究机构:康奈尔大学、加州大学圣地亚哥分校
主要内容:在机器人辅助进食中,如何可靠地完成“咬合获取”(bite acquisition)是一个核心挑战。不同食物物理性质多样,餐具与食物的交互过程还会随时间发生变化(如牛排冷却后变硬)。
为此,本文提出了 SAVOR,一种新方法用于学习技能可供性,即判断某种操作技能(如叉取、舀取)是否适合特定餐具-食物交互。方法分为两个层面:餐具可供性通过离线标定获得,建模不同餐具与食物交互时的功能能力;食物可供性则基于软硬度、湿度、黏性等属性,先由视觉条件下的语言模型进行常识推理,再在操作过程中结合多模态视觉-触觉感知(SAVOR-Net)动态更新。最终系统在实时预测中整合两类可供性,使机器人能选择最合适的操作技能。
实验证明,在 20 种单一样本食物和 10 份真实餐食上,SAVOR 比基于类别的最新方法提升了 13% 的成功率,凸显了交互驱动技能建模的重要性。

▲图13|SAVOR,通过结合工具可供性和食物可供性选择合适的操作模式,从而更好的提升机器人辅助进食的表现©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2506.02353
项目地址:https://emprise.cs.cornell.edu/savor/
ScrewSplat: An End-to-End Method for Articulated Object Recognition
研究机构:韩国首尔大学、麻省理工学院
主要内容:识别带有可动部件的关节物体(如门、笔记本电脑)的几何结构与运动关节,是机器人交互的关键能力。但现有方法往往依赖已知部件数量、深度图输入,或复杂的中间步骤,限制了实际应用。
本文提出了 ScrewSplat,一种简单高效的端到端方法,仅依赖 RGB 观测即可完成关节物体识别。其核心思想是随机初始化螺旋轴(screw axes),并通过迭代优化恢复物体的运动学结构。在此过程中结合 Gaussian Splatting,同时重建三维几何并将物体分割为刚性与可动部分。
实验表明,该方法在多类关节物体上实现了 最新最优的识别精度,并进一步支持零样本的文本引导操作。这使得 ScrewSplat 不仅是识别方法的提升,更为语言驱动的物体操作提供了可能。
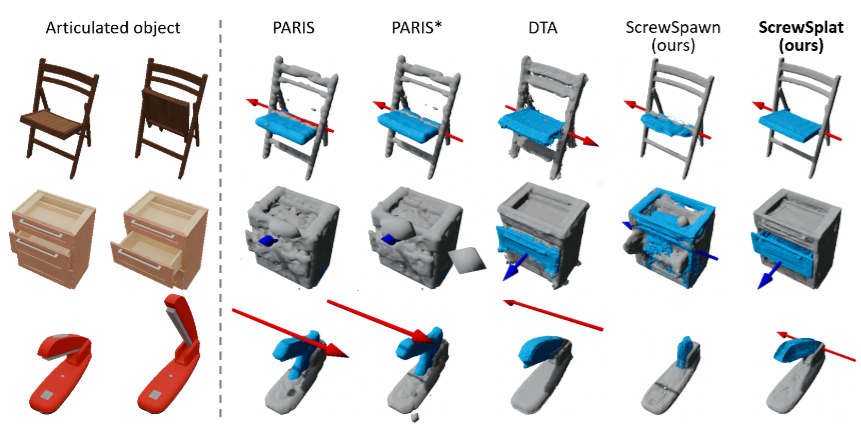
▲图14|ScrewSplat可以通过基于3DGS的重建方式,仅依赖于RGB输入就对带有可动部件和关节的物体实现稳定的识别©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2508.02146
ClutterDexGrasp: A Sim-to-Real System for General Dexterous Grasping in Cluttered Scenes
研究机构:北京大学计算机学院前沿计算研究中心、北京大学Agibot Lab、北京大学PsiBot Lab、普林斯顿大学
主要内容:在杂乱场景中进行灵巧抓取极具挑战:物体几何多样,遮挡与潜在碰撞频繁。现有方法大多专注于单物体抓取或静态抓取位姿预测,难以应对复杂环境。近期的视觉-语言-动作模型虽有潜力,但需要大量真实演示,代价高昂。
本文提出 ClutterDexGrasp,一个两阶段的教师-学生框架,实现面向目标的闭环灵巧抓取,并支持零样本从仿真到现实的迁移。教师策略在仿真中通过杂乱密度课程学习和安全课程进行训练,学习到通用且动态的抓取行为。随后通过模仿学习,将其知识蒸馏到基于三维扩散的学生策略(DP3),该策略仅依赖部分点云观测即可运行。
实验结果显示,这是首个实现零样本 sim-to-real 的闭环抓取系统,在多样物体与布局下均展现出鲁棒性能。

▲图15|ClutterDexGrasp 实现了零样本的仿真到现实迁移,用于闭环的目标导向灵巧抓取,即使在杂乱场景中也能完成任务。它能够在多样化的物体和复杂环境中实现鲁棒泛化,即便在存在严重遮挡的情况下依然表现出色©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2506.14317
项目地址:https://clutterdexgrasp.github.io/

规划与安全鲁棒性
探索在复杂环境中的规划策略与安全机制。
Real-Time Out-of-Distribution Failure Prevention via Multi-Modal Reasoning
研究机构:斯坦福大学、英伟达
主要内容:机器人在未知危险场景下(分布外失败,OOD)往往缺乏可靠的安全回退机制。现有方法多依赖人工定义的固定策略,无法在语义层面实现通用的安全规划。
FORTRESS 提出了一种新的安全框架:在常规运行时低频调用多模态推理器,用于识别任务目标和潜在失败模式。当监控触发回退时,系统能实时合成回退路径,同时推断并规避语义上不安全的区域。这样,它无需人工硬编码的干预策略,就能在开放世界中生成具备动态可行性的安全动作。
实验表明,FORTRESS 在安全分类、仿真和真实机器人(ANYmal 与四旋翼)测试中均超越现有方法,大幅提升了系统的鲁棒性与任务成功率。

▲图16|FORTRESS 框架概览:FORTRESS通过以下方式防止 OOD(分布外)失败:基于回退策略的语义描述推理出具体的目标位置,提前预判潜在的失败模式,并在正常轨迹中以低频率构建代价函数,用于识别语义上不安全的区域。当安全响应被触发时,算法能够快速生成语义安全的回退规划©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2505.10547
项目地址:https://milanganai.github.io/fortress/
"Stack It Up!": 3D Stable Structure Generation from 2D Hand-drawn Sketch
研究机构:新加坡国立大学
主要内容:传统的机器人建构系统需要精确的三维目标输入,这对普通用户而言门槛极高。
StackItUp 打破了这一限制,允许用户仅通过二维手绘草图即可指定复杂的三维结构。其核心在于引入抽象关系图,捕捉草图中的符号几何关系(如“在左侧”)与稳定性模式(如“两柱支撑”),同时过滤掉草图中的噪声度量信息。随后,系统利用组合扩散模型将关系图映射为三维姿态,并通过预测隐藏支撑结构不断修正结果。
实验涵盖地标建筑与房屋草图,StackItUp 能稳定生成多层三维结构,在稳定性与视觉相似度上均优于现有基线。
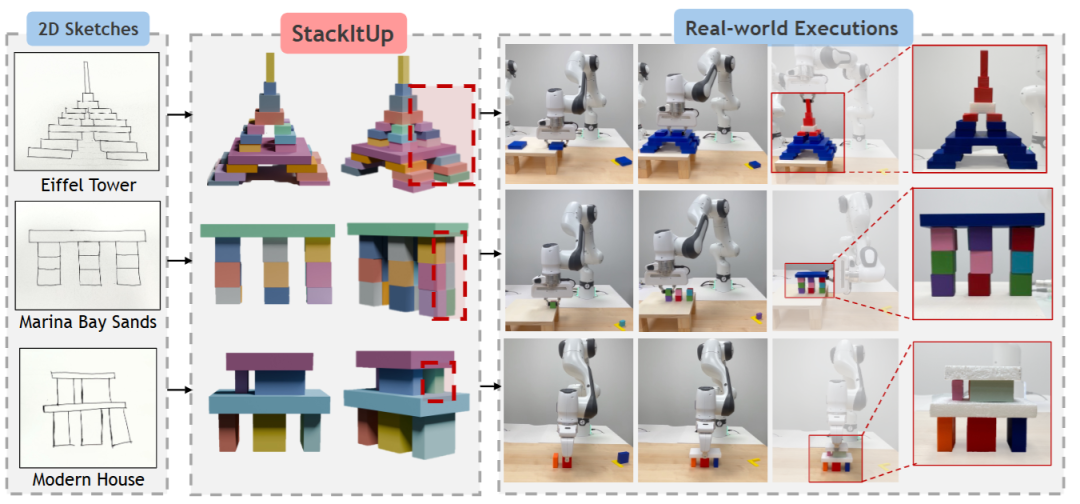
▲图17|StackItUp 演示。StackItUp 允许非专业人员通过简单的二维草图为机器人指定三维结构。从粗略的正视图绘图中,系统能够预测出精确的三维位姿以及隐藏支撑,从而生成与草图相似的稳定结构。这些位姿可以直接作为目标规范,供机械臂进行运动规划与实际执行。图中展示了输入草图(左)、包含预测支撑的生成三维结构(中)以及真实机器人执行结果(右)©️【深蓝具身智能】编译
论文地址:https://arxiv.org/pdf/2508.02093

总结
CoRL 每年就像是机器人研究的一面“风向标”,这17 篇论文构成了一幅完整的研究图景:既有面向远景的基础性探索,也有紧贴应用的落地尝试。
它们不仅展现了当前学界的研究热点,也预示了未来机器人如何逐步走向开放世界、与人类环境更好地协同。
不知道各位读者有没有发现,今年的论文盘点展现了一个共同点——机器人正从实验室走向复杂真实环境,从单一任务走向开放世界的智能协作。
如果各位读者朋友对某一类方向特别感兴趣,欢迎在评论区留言。我们会挑选部分代表性论文,做更深入的解读和方法拆解。
编辑|阿豹
审编|具身君
Ref : https://www.corl.org/program
>>>现在成为星友,特享99元/年<<<

我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

商务合作扫码咨询

机器人、自动驾驶、无人机等研发硬件

关于我们:深蓝学院北京总部于2017年成立,2024年成立杭州分公司,2025年成立上海分公司。
学院课程涵盖人工智能、机器人、自动驾驶等各大领域,开设近100门线上课程。拥有多个实训基地助力教学与科研,多台科研平台硬件设备可供开展算法测试与验证。
服务专业用户数达11万+(人工智能全产业链垂直领域的高净值用户),硕博学历用户占比高达70%。已与多家头部机器人企业、头部高校建立深度合作,深度赋能教育 、企业端人才培养与匹配。
工作投稿|商务合作|转载:SL13126828869


点击❤收藏并推荐本文










