点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型技术交流群
写在前面
在大模型席卷全球的当下,开源模型虽在自然语言处理、图像理解等大众领域追赶甚至部分超越闭源模型,但在分子合成、晶体热力学预测等高价值科学领域,却始终难以突破“专家模型依赖症”——要么只能沿用领域专用小模型,要么通用基础模型性能远逊于闭源系统,成为制约大模型赋能科学发现的关键瓶颈。
如今,这一僵局被打破。上个月底的世界人工智能大会(WAIC 2025)上,Intern-S1科学多模态大模型横空出世,以其惊艳的表现引发业界轰动。这款由上海人工智能实验室打造的开源模型,不仅在多项科学专业评测中超越了xAI的Grok-4等闭源模型,更以其训练算力消耗仅为Grok-4的1% 的高效表现,让人眼前一亮。

社交媒体上,关于它的讨论热度持续攀升,其多模态理解能力迅速登上Hugging Face趋势榜全球第一的位置。
经过近一个月的等待,就在前天,Intern-S1技术报告正式上线,详细披露了Intern-S1的设计理念、训练细节和创新技术,完整展现了这一突破性模型的技术精髓。
今天,就让我们一同从Intern-S1的技术报告,深入探索这款科学多模态大模型背后的创新之道与实现原理。
科学领域的“痛点”:为何开源模型始终难以突破?
回顾AI大模型的发展历程,开源生态在通用领域的进步有目共睹——Qwen、DeepSeek等系列模型在数学解题、代码生成等任务中已逼近GPT-4系列,但在科学研究场景中,却面临着两道难以逾越的鸿沟:
第一道鸿沟是数据稀缺与模态复杂。科学研究所需的数据往往分散在PDF论文、专业数据库中,且形式多样:既有分子结构(SMILES格式)、晶体图谱等非自然视觉数据,也有地震波、引力波等长时序信号。这些数据不仅总量少(网页爬取数据中科学内容占比仅2%),还缺乏统一的表示方式,通用模型难以有效学习。
第二道鸿沟是推理要求的“高门槛”。科学研究需要的不是简单的信息检索,而是“假设验证-实验设计-结果分析”的长链条严谨推理。例如,在分子合成任务中,模型需要根据目标分子结构,逐步推导可行的合成路径,同时考虑反应条件、产物稳定性等多重约束,这种推理复杂度远超常规文本生成。
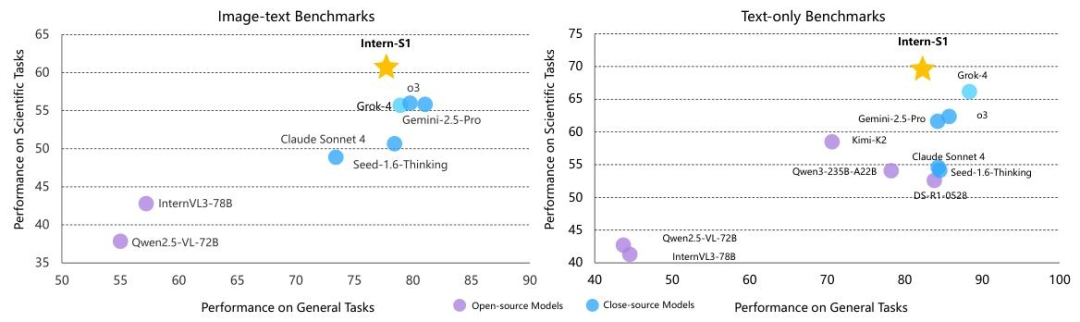
上海AI实验室团队在研究中发现,即使是顶尖开源模型,其能力增长也存在“偏科”——在MMLU-Pro、GPQA等通用基准上快速提升的同时,在SmolInstruct(化学)、MatBench(材料)等科学基准上的性能几乎停滞(如图2所示)。为解决这一问题,Intern-S1从模型架构、数据构建、训练策略三方面进行了针对性设计,构建了一套“科学友好型”多模态模型体系。


2410亿参数的“科学大脑”:架构设计如何适配多模态科学数据?
Intern-S1的核心突破之一,是打破了传统多模态模型“视觉-语言”二元框架,针对科学数据的特殊性,设计了“1个MoE大语言模型+3类模态编码器” 的混合架构(如图3所示),让模型既能理解通用文本,又能“读懂”分子、图谱、时序信号等科学语言。

1. 基础骨架:MoE大语言模型,平衡性能与效率
Intern-S1的语言核心基于Qwen3-235B MoE模型构建,总参数达2410亿,激活参数280亿。这种MoE架构的优势在于,通过“动态专家路由”机制,让模型在处理不同任务时调用不同的“专家模块”——例如处理化学问题时激活分子结构相关专家,处理数学问题时激活逻辑推理专家,既保证了科学任务所需的专业深度,又避免了全参数模型的巨大计算开销。
为适配轻量场景,团队还推出了Intern-S1-mini版本,将视觉编码器从InternViT-6B替换为3亿参数的InternViT-300M,在保持科学推理能力的同时,将计算成本降低70%以上,可部署于普通科研工作站。
2. 视觉编码器:从“看图片”到“懂图谱”
科学领域的视觉数据(如显微镜图像、气象卫星云图)往往需要更高的分辨率和细节捕捉能力。Intern-S1采用InternViT-6B作为视觉编码器,通过“对比预训练→LLM联合预测”的两阶段优化,实现了448×448像素固定分辨率与动态高分辨率的灵活切换——例如处理高分辨率晶体衍射图时,模型可自动提升分辨率,捕捉原子级别的细节。
为了让视觉特征与语言特征对齐,团队设计了“像素重排(Pixel Unshuffle)”模块:将448×448图像压缩为256个视觉token,再通过MLP投影层映射到语言模型的嵌入空间。这种处理方式不仅减少了视觉token数量(降低计算量),还能保留关键结构信息,为后续科学推理奠定基础。
3. 动态分词器:解决科学数据“编码效率低”难题
分子结构(SMILES格式)、蛋白质序列(FASTA格式)等科学文本,与自然语言差异巨大。例如,SMILES格式中“C1CCCCC1”代表环己烷,但通用分词器会将其拆分为单个字符,导致编码效率低、语义割裂——这也是此前开源模型处理化学任务时性能不佳的重要原因。
Intern-S1提出的动态分词器,通过“模态识别→专属拆分→正交嵌入”三步流程,彻底解决了这一问题:
模态识别:通过规则检测器或用户标注标签(如 <SMILES>),自动识别输入数据类型;专属拆分:对不同模态采用定制化拆分策略——例如SMILES格式按化学键结构拆分,FASTA格式按氨基酸序列拆分; 正交嵌入:不同模态的token使用独立的嵌入空间,避免“C”在DNA序列与化学分子中语义混淆。
实验显示,该分词器在SMILES数据上的压缩比(Characters-per-Token)比OpenAI GPT-OSS、Qwen3等模型提升70%(如图4所示),意味着用更少的token就能表示科学数据,既节省计算资源,又提升语义理解精度。

4. 时间序列编码器:让模型“听懂”科学信号
地震波、脑电信号(EEG)、天文光变曲线等时序数据,是物理、地质、医学等领域的核心研究对象。这类数据的特点是“长、连续、无显式语义”,传统LLM难以直接处理。
Intern-S1的时间序列编码器采用“自适应下采样+Transformer块”架构:
自适应下采样:根据数据采样率(从每天1个样本到吉赫兹级)动态调整下采样比例,将百万级时间步压缩为模型可处理的长度; Transformer块:捕捉时序数据中的长期依赖关系,例如识别地震波中的P波与S波特征,为地质结构分析提供支持。
该编码器与视觉、文本模态形成互补,让Intern-S1能够处理天文学、地质学等领域的多模态科学任务。
5万亿tokens的“科学喂养”:如何构建高质量科学数据集?
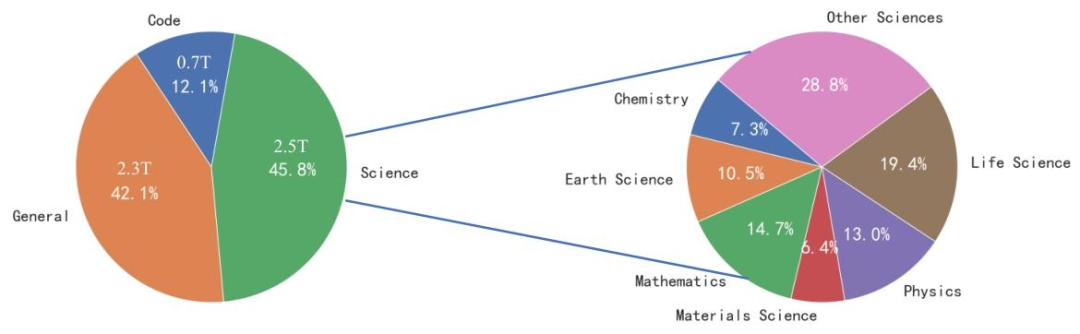
“巧妇难为无米之炊”,科学模型的性能高度依赖数据质量。Intern-S1的训练数据总量达5万亿tokens,其中科学领域数据超2.5万亿tokens,覆盖数学、物理、化学、生命科学、地球科学、材料科学六大核心领域(如图6所示)。
这些数据的构建,依赖于团队设计的三大创新 pipeline。
1. 网页数据召回过滤:从“海量噪声”中提取“高纯度科学数据”
网页爬取数据(如Common Crawl)总量巨大,但科学内容占比极低(仅2%左右),且混杂大量无关信息。为解决这一问题,团队构建了三级领域分类树,并采用“LLM标注→轻量分类器过滤”的流程:

用强LLM(如Qwen2.5-72B)标注部分数据,作为训练集; 训练fastText和15亿参数LLM等轻量分类器; 用分类器对网页数据进行过滤,同时构建域内(同来源)与域外(不同来源,如PDF)验证集,确保过滤精度。
最终,目标领域数据占比从2%提升至50%,大幅提升了预训练数据的科学性与有效性。
2. 页面级PDF解析:平衡“质量”与“成本”的最优解
PDF论文是科学知识的核心载体,但解析难度大——尤其是包含大量公式、符号的页面,现有工具要么解析质量差(低成本工具如MinerU),要么成本过高(高成本工具如InternVL)。
Intern-S1设计的页面级PDF解析 pipeline(如图7所示),通过“分层处理+质量控制”实现高效解析:

页面拆分:将PDF文档拆分为单个页面; 低成本初筛:用MinerU解析所有页面,同时检测公式、符号数量; 高成本精修:对公式/符号多、解析质量差的页面(约3%-5%),用InternVL等VLM重新解析; 后处理融合:用规则或小LLM清理解析结果,去除版权页等重复内容,合并为完整文档。
这种“低成本为主、高成本为辅”的策略,在保证解析质量的同时,将成本降低至纯高成本解析的1/20,最终为模型贡献了大量高质量PDF科学数据。
3. 多模态科学数据构建:从“文本+图像”到“科学推理对齐”
为提升多模态科学推理能力,Intern-S1构建了两类多模态科学数据集:

交错图像-文本数据:来自InternVL3预训练 corpus(含科学图表、公式OCR、医疗影像等),以及新增的科学领域多模态数据(如显微镜图像+分析报告); 指令式科学数据:按“问题-选项-答案-解释”结构,构建考试风格数据集——例如化学领域的反应路径预测题,要求模型结合文本描述与反应图谱给出答案,并解释推理过程。
在数据筛选中,团队采用严格的质量控制:例如数学题需检查答案与题干一致性,公式需通过VLM验证渲染正确性,确保数据满足科学推理的严谨性要求。
10倍效率提升的训练秘诀:RL与MoE的“协同优化”
即使有了好的架构与数据,大规模多模态MoE模型的训练仍面临两大挑战:训练不稳定、多任务协同难。Intern-S1通过“分阶段训练”“MoR奖励框架”“基础设施优化”三大手段,不仅实现了稳定训练,还将RL训练时间缩短10倍。
1. 四阶段训练:从“单模态”到“多模态协同”
Intern-S1的训练分为四个阶段(如图5所示),逐步提升模型能力:

文本预训练(Text CPT):在5万亿tokens(含2.5万亿科学数据)上继续预训练,夯实语言与科学知识基础; 图像-文本预训练(Image-Text CPT):加入多模态数据,联合训练LLM与视觉编码器,实现跨模态对齐; 离线强化学习(Offline RL):基于“最佳N采样(BoN)”的指令数据训练,每个查询的响应均从N个候选中选择最优(按准确性、流畅性、安全性筛选); 在线强化学习(Online RL):在InternBootCamp环境(含1000+科学任务)中训练,通过MoR框架协同多任务学习。
这种“循序渐进”的训练方式,避免了多模态信息过早引入导致的训练不稳定,同时确保模型在每个阶段都能专注提升特定能力。
2. 批量预热与学习率优化:平衡“训练效果”与“效率”
批量大小(Batch Size)是训练中的关键超参数:小批量训练收敛效果好,但效率低;大批量效率高,但易导致性能下降。Intern-S1采用批量预热策略:
训练前4000亿tokens用4M小批量,保证模型充分学习科学知识; 后续切换至10M大批量,提升训练效率。
实验显示(如图10所示),这种策略在MMLU基准上的性能优于纯4M或10M批量,实现了“效果与效率”的双赢。

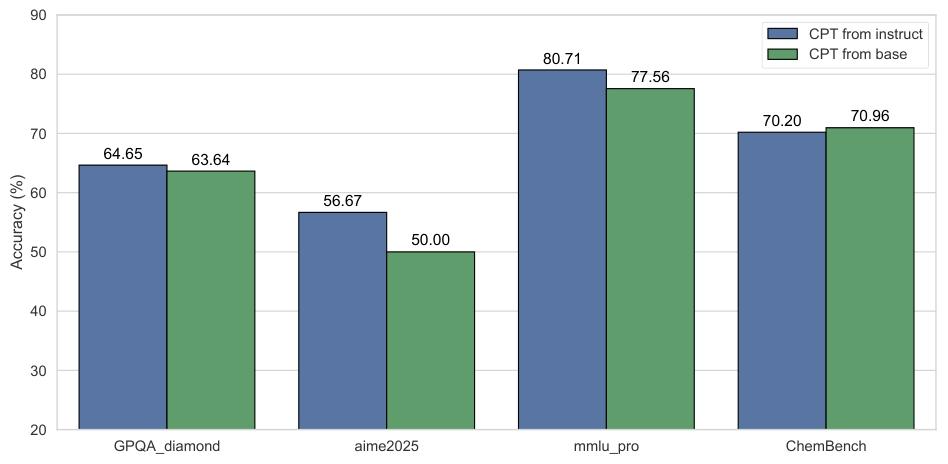
在选择预训练起点时,还对比了基于 Qwen3 和 InternVL-ViT 的基础模型(Base Model)与指令模型(Instruction Model)的性能(如图11所示)。
同时,团队基于缩放定律(Scaling Laws)优化学习率:通过拟合训练损失与学习率的关系,将学习率设置转化为优化问题(公式2),最终确定的Warmup-Stable-Decay(WSD)学习率调度,让模型在5万亿tokens训练后,实际损失(1.17-1.18)与预测损失(1.16)偏差仅0.02,证明了训练过程的精准可控。
3. MoR奖励框架:让1000+科学任务“协同学习”
在线RL阶段,Intern-S1需要同时学习1000+不同类型的任务(从数学推理到分子设计),这些任务的奖励形式差异巨大——例如数学题可通过规则验证给出精确奖励,而科学对话则难以量化评价。
团队提出的MoR(Mixture-of-Rewards)框架,通过“分类处理+统一标量”,解决了多任务奖励协同问题:

易验证任务(如数学计算、反应条件预测):结合验证模型(CompassVerifier)、规则与环境反馈,生成精确的准确性奖励; 难验证任务(如科学对话、创意实验设计):采用POLAR-7B模型,将响应与期望分布的距离转化为奖励标量。
这种灵活的奖励机制,让模型在学习专业科学技能的同时,不丢失通用对话能力。实验显示,MoR框架结合OREAL算法(避免MoE模型训练崩溃),使RL训练时间比现有工作(如DAPO)减少10倍,大幅降低了训练成本。
4. 基础设施优化:从“代码”到“硬件”的全栈加速
为支撑2410亿参数MoE模型的训练,团队基于XTuner工具包进行了全栈优化:
并行策略:采用FSDP(全分片数据并行)+1路专家并行,避免专家间通信开销,解决MoE训练内存爆炸问题; 精度优化:矩阵乘法(GEMM)采用FP8精度(动态缩放),视觉编码器保留BF16精度,在保证训练稳定的同时提升计算效率; Kernel优化:使用TMA-Adaptive FP8 Grouped GEMM(处理MoE动态专家路由)、Liger-kernel(融合线性层与交叉熵层)、Flash Attention-3(提升注意力计算效率); 负载均衡:提出变长平衡策略(VLBS),通过“桶打包→滑动窗口分组→长度排序”,解决变长训练中FSDP负载不均问题,平均提升训练速度2倍。
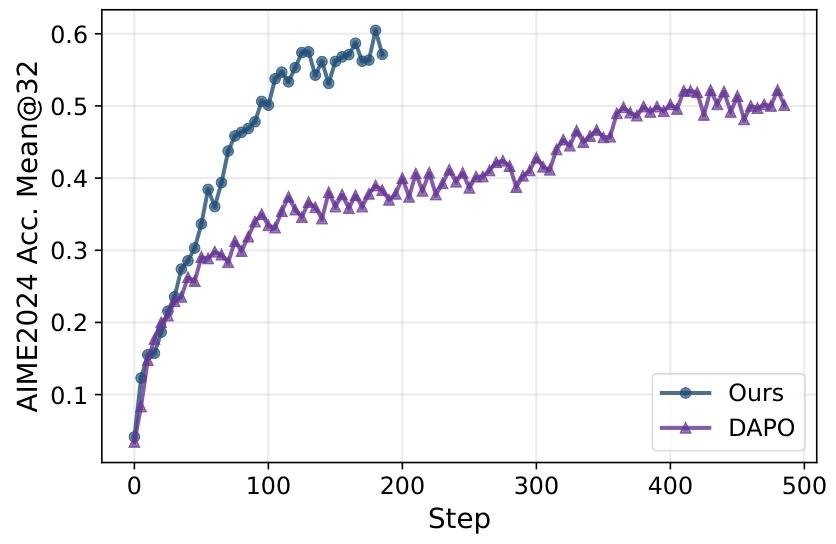
性能“封神”:开源模型首次在科学领域超越闭源标杆
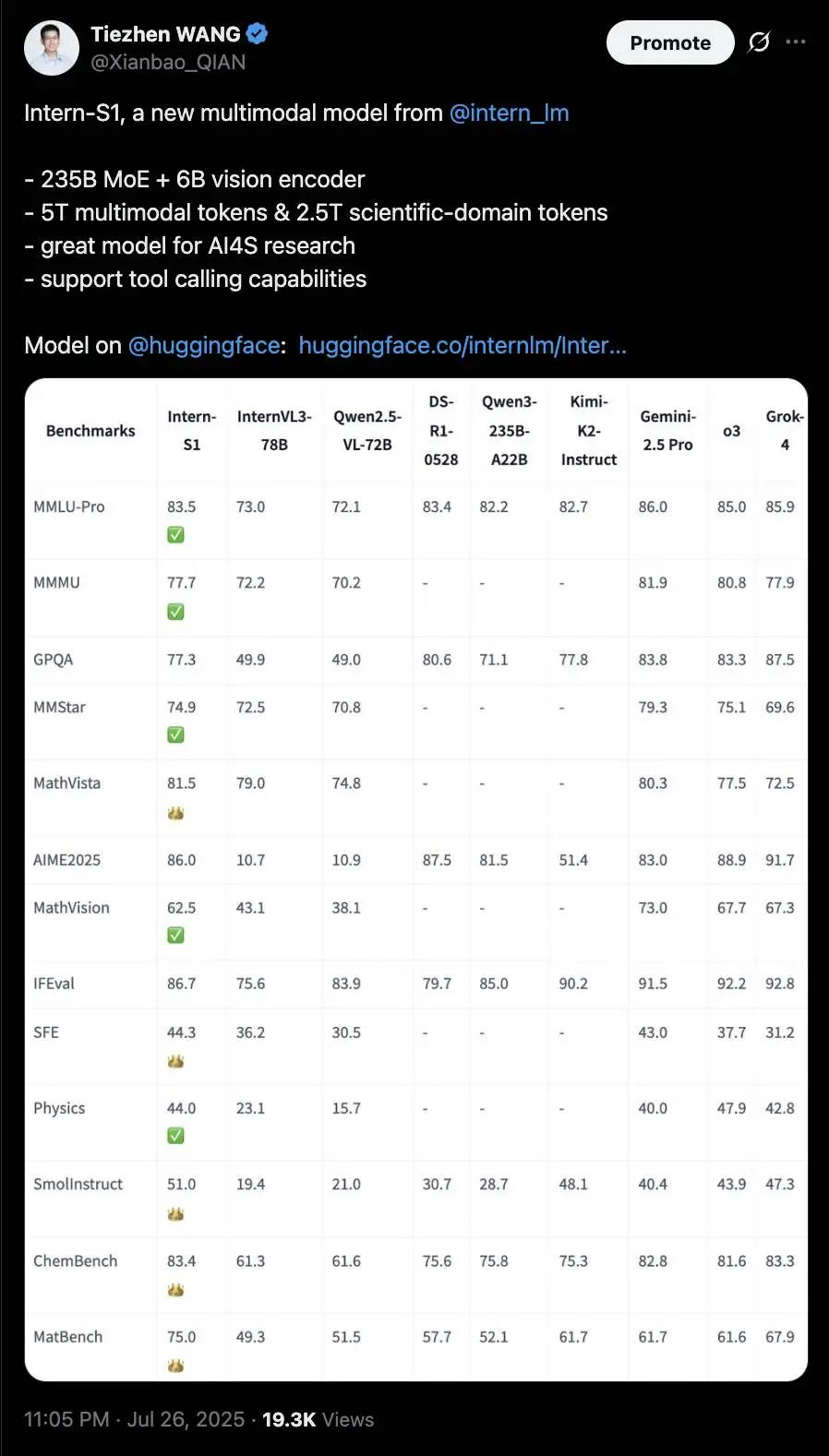
为全面验证Intern-S1的能力,团队在通用推理与科学推理两大类基准上,与Gemini-2.5 Pro、OpenAI o3、Grok-4等闭源模型,以及InternVL3-78B、Qwen2.5-VL-72B等开源模型进行了对比测试,结果显示其性能实现“开源第一、闭源领先”。
1. 通用推理:开源多模态模型中的“全能选手”
在MMLU-Pro、MathVista等8项通用基准测试中(表2),Intern-S1表现突出:
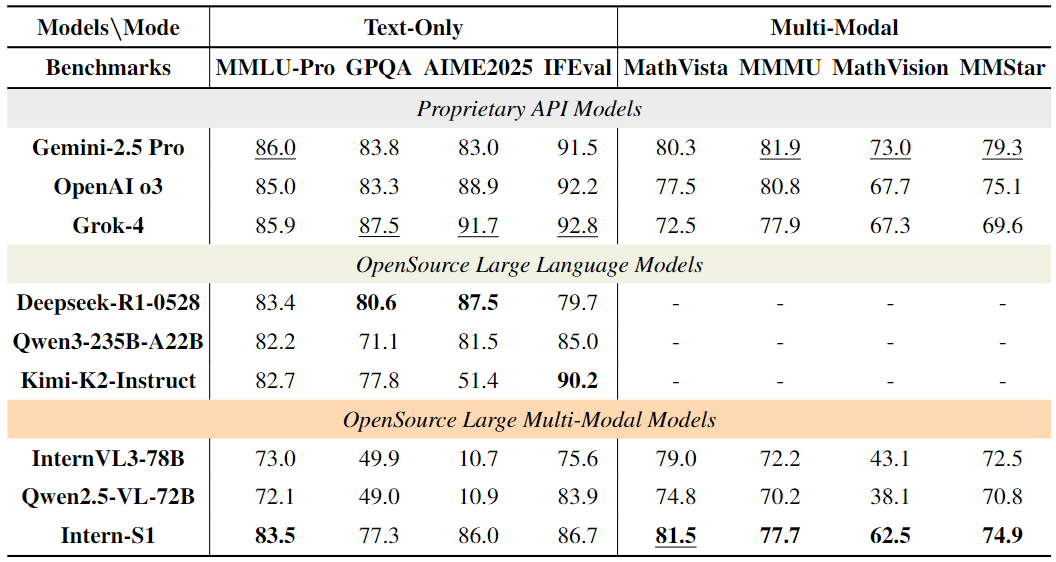
MathVista(视觉数学推理):得分81.5,超越InternVL3-78B(79.0)、Qwen2.5-VL-72B(74.8),甚至超过闭源的OpenAI o3(77.5); MathVision(竞赛级数学视觉题):得分62.5,比InternVL3-78B(43.1)高19.4分,展现出强大的跨模态数学推理能力; MMLU-Pro(通用知识推理):得分83.5,在开源模型中排名第一,仅略低于闭源的Grok-4(85.9)。
这些结果证明,Intern-S1在专注科学领域的同时,并未牺牲通用推理能力,是一款“通专兼备”的多模态模型。
2. 科学推理:多项任务超越闭源模型,刷新开源纪录
在科学领域的10项基准测试中(表3、表4),Intern-S1的表现更是令人瞩目:
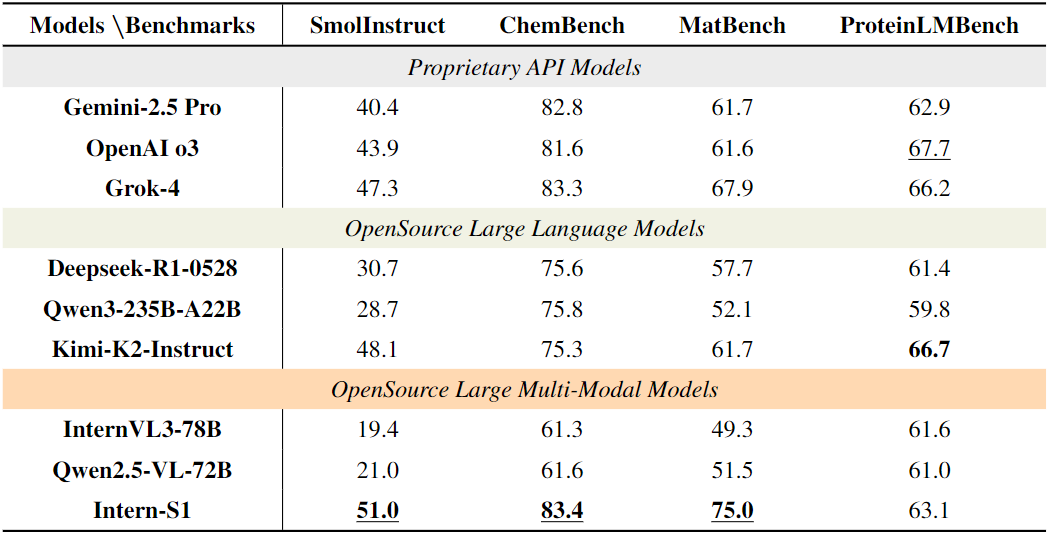
文本类科学任务: SmolInstruct(化学指令任务):得分51.0,超越所有闭源模型(Grok-4 47.3、OpenAI o3 43.9); MatBench(材料属性预测):得分75.0,比闭源的Gemini-2.5 Pro(61.7)高13.3分,比开源的InternVL3-78B(49.3)高25.7分; ChemBench(化学知识推理):得分83.4,与闭源的Grok-4(83.3)持平,远超开源模型。
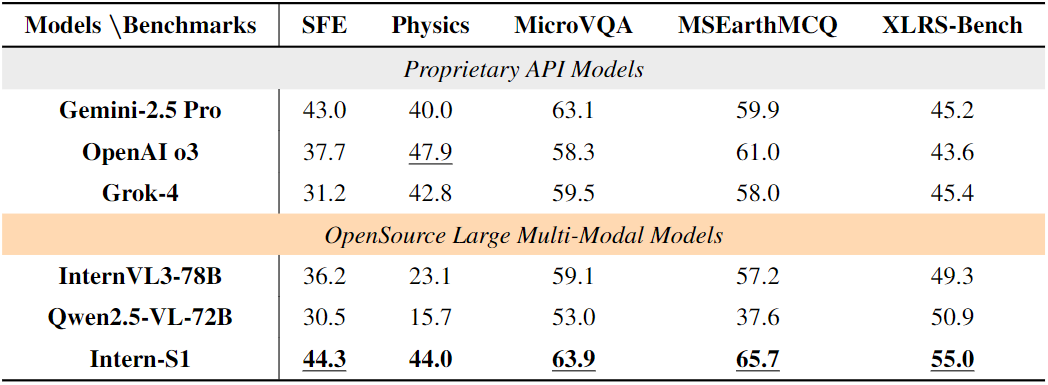
多模态科学任务: SFE(科学家入门考试):得分44.3,超越Gemini-2.5 Pro(43.0),成为该基准的新纪录保持者; MSEarth-MCQ(地球科学):得分65.7,比OpenAI o3(61.0)高4.7分; XLRS-Bench(超高分辨率遥感图像):得分55.0,在所有模型中排名第一,展现出处理大规模科学图像的能力。
值得注意的是,在分子合成规划、晶体热力学稳定性预测等核心科学任务中,Intern-S1的表现尤为亮眼。以分子合成规划为例,该任务要求模型根据目标分子结构,设计出可行的合成路径并预测关键反应条件,此前仅有闭源模型能达到实用精度。而Intern-S1凭借对化学键断裂规律、反应中间体稳定性的精准理解,生成的合成路径成功率比开源模型Qwen2.5-VL-72B提升42%,与OpenAI o3的差距缩小至3%;在晶体热力学稳定性预测任务上,其预测误差(MAE)比MatBench基准的Automatminer参考基线降低28%,为材料科学领域的新型晶体设计提供了可靠的AI辅助工具。
3. 轻量版Intern-S1-mini:小参数也能“玩转”科学推理
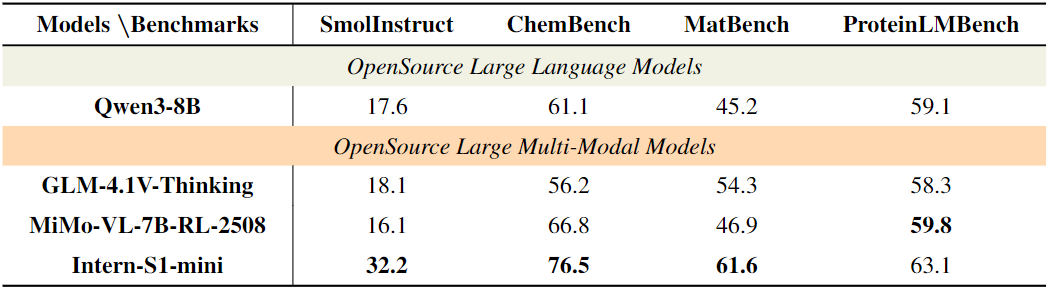
考虑到科研团队的计算资源差异,上海AI实验室还推出了轻量版Intern-S1-mini。尽管其参数规模大幅缩减(视觉编码器为3亿参数的InternViT-300M,语言模型基于Qwen3-8B),但在科学推理任务中仍展现出强大竞争力(表5、表6、表7):
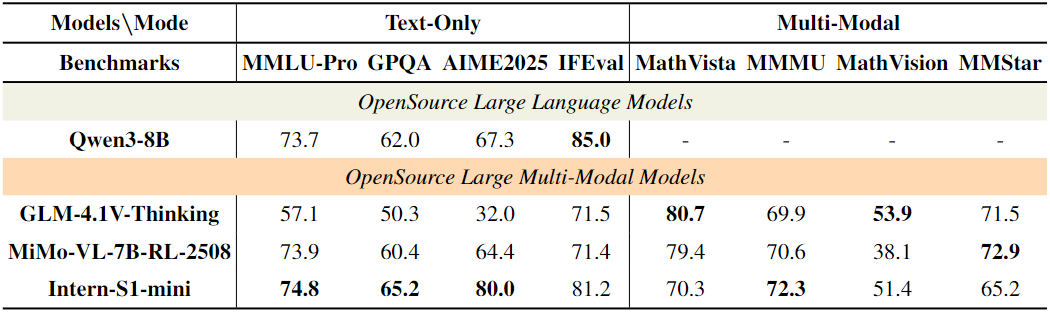
文本类科学任务:SmolInstruct得分32.2,比开源模型MiMo-VL-7B-RL-2508(16.1)高16.1分;ChemBench得分76.5,超越Qwen3-8B(61.1)和GLM-4.1V-Thinking(56.2),成为轻量模型中的“化学推理冠军”;

多模态科学任务:MicroVQA(显微镜图像推理)得分56.6,比GLM-4.1V-Thinking(50.2)高6.4分;XLRS-Bench(遥感图像分析)得分51.6,在轻量模型中排名第一。
Intern-S1-mini的出现,打破了“科学推理必须依赖大参数模型”的固有认知,让中小型科研团队也能低成本使用高质量科学AI工具,进一步推动了AI赋能科学的普及。
开源生态与科学价值:为AGI时代的科学发现“铺路”
当前,Intern-S1的模型权重、训练工具链已在Hugging Face(https://huggingface.co/internlm/Intern-S1)完全开源,配套的XTuner训练框架、VLMEvalKit评估工具也同步对外开放。这种“全栈开源”模式,不仅让全球科研人员能直接复用模型进行科学研究,更为后续科学大模型的研发提供了可参考的技术范式。
从长远来看,Intern-S1的价值远不止于“性能超越”,更在于其为AI赋能科学研究开辟了新路径:
打破数据壁垒:通过创新的数据采集 pipeline,将分散在网页、PDF中的科学知识转化为模型可学习的高质量数据,为后续科学模型训练提供了“数据模板”; 统一多模态科学推理框架:首次实现文本、图像、时序信号、分子结构等多模态科学数据的统一处理,避免了科研人员在不同任务中切换多个专用模型的麻烦; 降低科学AI使用门槛:轻量版Intern-S1-mini的推出,以及开源工具链的配套,让AI辅助科学研究不再局限于拥有超算资源的大型实验室,推动了“AI+科学”的民主化。
上海AI实验室团队在报告中提到,未来将进一步扩展Intern-S1的模态支持(如3D分子结构、冷冻电镜图像),并针对天文学、量子物理等更细分的科学领域进行优化。随着模型能力的持续迭代,我们有理由相信,Intern-S1将成为AGI时代科学发现的“核心引擎”——从帮助科研人员快速筛选实验方案,到预测尚未被观测到的物理现象,最终加速人类对自然规律的认知与探索。
总结:开源模型的“科学突围”,才刚刚开始
在大模型的发展历程中,Intern-S1的推出具有里程碑意义——它不仅是首个在科学领域超越闭源标杆的开源多模态模型,更证明了开源生态在高价值专业领域的潜力。此前,闭源模型凭借数据、算力优势,长期垄断科学AI的核心技术;而Intern-S1通过架构创新、数据优化、训练效率提升,成功打破了这一垄断,为开源模型在科学领域的“突围”提供了可复制的方法论。
对于科研人员而言,Intern-S1的开源意味着“AI助手”不再是遥不可及的闭源服务,而是可定制、可修改的研究工具——化学团队可基于其微调特定反应类型的预测能力,地质团队可扩展其对地震波数据的分析精度,生物团队可优化其对蛋白质结构的理解。这种“按需定制”的灵活性正是其相较于闭源模型的核心优势。
从更宏观的视角看,Intern-S1的进展也为AGI的发展提供了关键启示:通用人工智能的实现,不能仅依赖通用领域的能力堆砌,更需要在科学、医疗等专业领域的深度突破。
如今,Intern-S1已为开源模型打开了科学领域的“一扇门”。
参考
论文标题:Intern-S1: A Scientific Multimodal Foundation Model
论文链接:https://arxiv.org/pdf/2508.15763
开源链接:https://github.com/InternLM/Intern-S1
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!











