该AI大模型由杉数科技投递并参与数智猿×数据猿×上海大数据联盟共同推出的《2025中国数智产业AI大模型先锋企业》榜单/奖项评选。
当下企业决策正从传统的经验驱动向数据驱动、智能化转型。运筹学与人工智能技术的深度融合,正在重塑企业的决策逻辑。杉数科技联合上海交通大学智能计算研究院等单位推出了全球首个开源运筹学大语言模型ORLM,在多个标准测试集上的表现均超越了GPT-4等闭源模型,广泛应用到国内40多所科研院所与高校,成为优化建模领域目前备受关注和落地程度最高的大模型。这一创新成果标志着运筹学从依赖专家经验的传统建模范式,正式迈向自动化与智能化的崭新阶段。
ORLM通过对开源大语言模型进行专业化定向训练,将复杂的运筹优化技术转化为易于部署应用的智能工具,极大降低了工业界和学术界的使用门槛。该模型能够显著提升智能制造关键运营场景中的大规模复杂决策、精准规划、智能调度、资源分配等核心能力,助力企业实现降本增效,推动运筹优化技术以开源生态模式强势突围国外技术封锁。
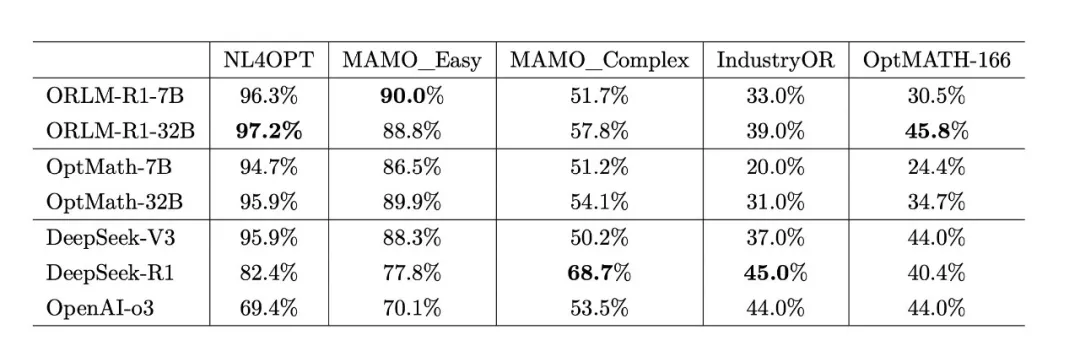
ORLM是全球首个开源运筹学大模型,它将过去高度依赖专家的复杂优化建模过程自动化与智能化。主要应用于制造、物流、供应链、电商零售等领域,解决生产计划、库存管理、路径优化等核心决策问题。其用户群体不仅包括需要从繁琐工作中解放出来的算法工程师和数据科学家,也涵盖了希望在保障数据安全前提下实现技术自主创新的企业,以及从事前沿探索的学术研究者。在此基础上我们又接出新一代的决策推理大模型——ORLM-R1。ORLM-R1采用基于可验证奖励的强化学习(RLVR, Reinforcement Learning from Verifiable Reward)的训练范式,以提升大语言模型在运筹学建模任务中的推理能力与准确性。与传统依赖最终答案正确性信号的稀疏奖励方法不同,ORLM-R1充分利用专业优化求解器提供的中间建模信息,构建出一种精细化且过程感知的奖励机制。该机制能够在复杂问题求解过程中对模型的中间推理步骤进行监督,显著缓解了因奖励稀疏而导致的训练效率低下问题。在具体实现上,ORLM-R1使用了Reinforce++框架,以实现对大语言模型输出的更细粒度控制。该框架使得训练目标不仅能够作用于最终答案,还能够约束推理链条中的关键环节,从而确保模型在复杂任务中的稳定性与可控性。同时,ORLM-R1结合提示词工程方法,引导模型生成思维链(CoTs, Chain of Thought),使模型具备分解复杂任务并逐步建模的能力。这一机制显著增强了大语言模型在处理多步骤运筹优化任务时的逻辑一致性与可解释性。在思维链生成的训练过程中,ORLM-R1进一步提出了一种双阶段强化学习生成策略。具体而言,第一阶段为自由探索阶段,在此阶段中模型不受严格约束,可以进行发散性推理和多路径探索,以最大限度激发创造性与多样性。第二阶段为严谨执行阶段,模型需收敛至规范化的建模逻辑,生成可由专业求解器直接验证与求解的优化模型。为在两个阶段之间实现平衡,ORLM-R1创新性地引入了选择性KL散度(Partial KL Divergence)。该方法的核心思想是“在正确的阶段做正确的事”:在自由探索阶段移除KL散度约束,从而赋予模型更大的探索空间;在严谨执行阶段重新引入KL散度约束,以确保生成结果的准确性与稳定性。通过这种分阶段的约束策略,ORLM-R1能够在保证模型创造性的同时,有效提升其建模精度与可验证性。综合而言,RLVR与选择性KL散度的结合,使得大语言模型在运筹学建模任务中实现了创造性与准确性的动态平衡。ORLM-R1对通过上述方法训练的两个推理模型: ORLM-R1-7B 和 ORLM-R1-32B,在NL4OPT、MAMO_Easy、MAMO_Complex、IndustryOR和OptMATH 这几个数学建模基准数据集上进行了系统性评估。在这些数据集上,ORLM-R1的模型效果远超于之前其他论文所提出的离线微调方法和Agent-based方法。同时ORLM-R1也和最先进的基座模型DeepSeek-V3, 大型推理模型DeepSeek-R1,OpenAI-o3进行比较,下面的图表展示了比较结果:可以看到,ORLM-R1-32B模型在平均性能上表现出色,优于DeepSeek-V3和OpenAI-o3。作为新一代开源的运筹学大语言模型,ORLM-R1的问世具有里程碑意义。它凭借出色的逻辑推理能力和极高的求解准确率,不仅代表了大模型在专业领域应用上的一次重要突破,更标志着运筹学的自动化与智能化建模范式迈上了全新的台阶。不同于通用大语言模型,ORLM-R1在研发过程中引入了基于强化学习的定向训练方案,将开源LLM 与专业数学优化求解器深度结合,从而使其具备了自动生成高质量运筹优化模型的能力。借助这一创新,ORLM-R1成功蜕变为一位真正意义上的“建模专家”。这种自动化的建模能力为工业界与学术界带来了多方面的价值:它不仅显著提升了建模效率,减少了人工建模中反复调试的工作量,还有效降低了技术门槛,使得即使缺乏深厚运筹学背景的企业或研究人员,也能快速利用先进的优化技术,辅助战略规划与业务决策。在复杂的供应链管理、生产调度、资源配置等实际场景中,ORLM-R1可以帮助用户快速生成可行的优化模型并求解,从而实现降本增效、提升整体竞争力。COLORMind是杉数科技基于ORLM大模型打造的智能决策平台,其核心功能是将自然语言描述的实际业务问题(如“优化物流成本”或“处理库存溢出”)一键转化为可执行的数学规划模型与求解代码。用户无需具备非常丰富的运筹学或编程背景,即可获得定制化决策方案。
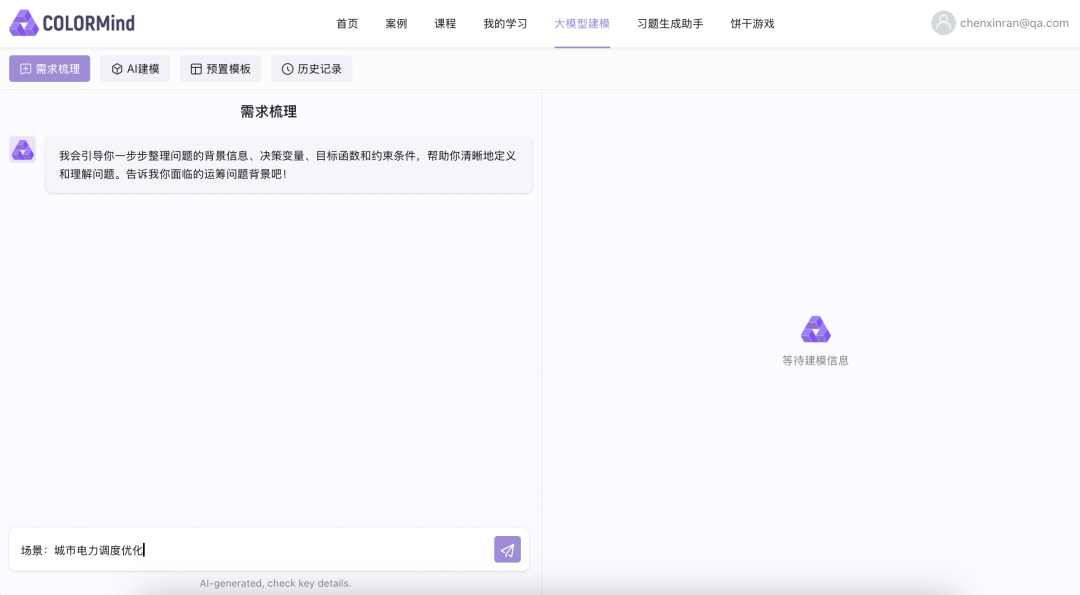
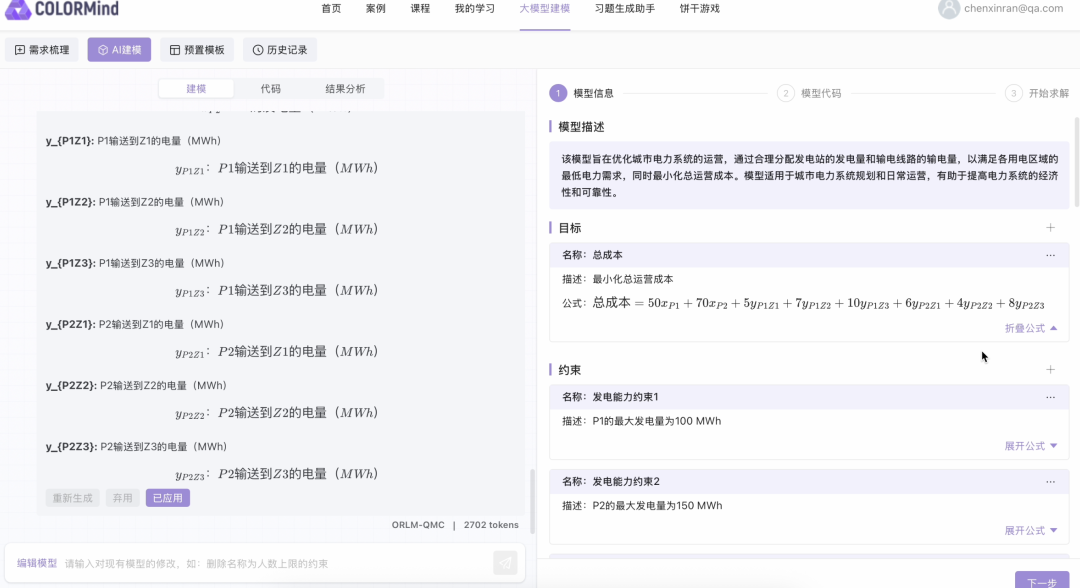
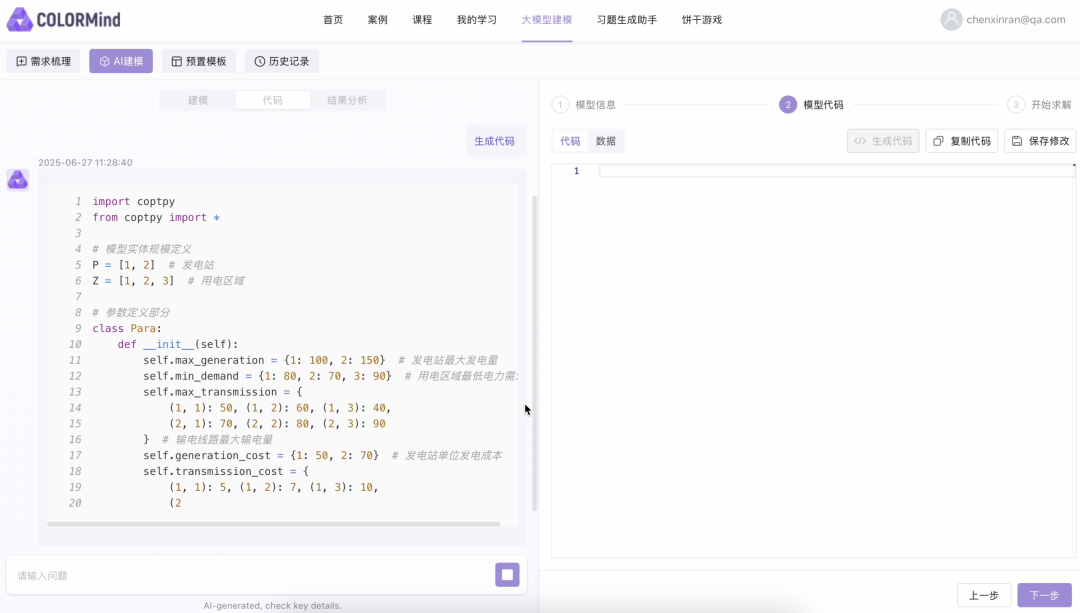
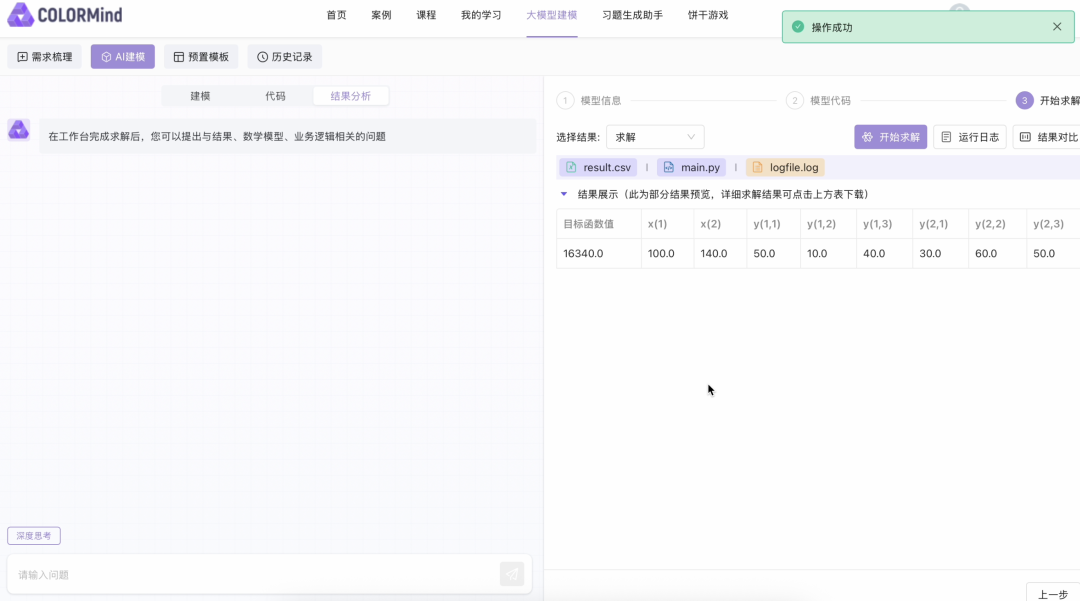
输入:帮助工程师快速梳理业务场景。在平台输入业务问题描述(如“最小化物流成本,满足库存约束”)。处理:自动生成数学模型与求解代码,工程师可手动调整后执行。输出:平台返回优化方案及代码,支持快速响应需求变更。交互式建模:业务人员通过问答形式输入需求(如“如何处理库存溢出?”),ORLM生成数学模型,经用户确认后求解。可视化结果:输出决策结果(如库存调整方案的求解结果),降低技术门槛。教学沙盘:学生分组模拟企业决策,用自然语言描述问题→ORLM建模→求解→结果分析→方案优化。应用:学生更深入理解现实业务场景并针对性做出优化方案。首先,COLORMind帮助用户自动梳理需求。用户在平台输入框直接描述业务需求,例如以下用户询问一个城市电力调度优化场景:现在到了数学建模部分。梳理完需求后,用户点击“开始建模”,COLORMind生成数学模型:接下来是代码生成部分。用户点击生成代码,COLORMind自动生成Python代码:最后来到求解部分。COLORMind调用杉数科技自研求解器COPT根据之前建模和代码生成的结果进行求解结果。同时,用户可即时调试参数并调用内置COPT求解器执行,大幅缩短响应周期:目前COLORMind平台已在物流调度(如列车分配)、库存管理、指挥决策(如乘务排班)、金融优化(如投资组合优化)、生产自动化(如无人仓调度)和路径规划等领域落地应用,并内置多个不同领域的实战案例,例如供应链优化和电力调度场景,方便用户直接尝试和学习。·杉数科技
杉数科技,由四位斯坦福博士于2016年联合创立,是中国先进的人工智能决策技术服务商。依托中国首个智能计算求解器COPT为核心引擎,专注智能决策计算与运筹优化领域,打造“智能算力+优化计算引擎+决策技术中台+业务场景”的端到端智能决策计算业务体系,为客户提供灵活、轻便、高效的决策优化计算服务,解决生产、供应、物流等系列业务场景难题,实现数字化转型与业务二次增长。
杉数科技在人工智能领域持续深耕,技术成果荣获国家工信部权威认可,多次入选Gartner、IDC、福布斯等咨询报告;公司获评国家高新技术企业、国家级专精特新“小巨人”企业、北京民营企业中小百强、北京市两业融合试点企业、北京市"硬科技”潜在独角兽企业等荣誉,拥有自主知识产权200余项,产品、服务及案例荣获行业荣誉140余项,广受行业与市场认可。
自成立以来,杉数科技产品及服务已在工业制造、轨道交通、能源电力、石油石化、航空航天、零售快消等20余个细分领域落地应用,服务数百家国内外行业头部企业。
点击“阅读原文”链接还可查看ORLM智能决策大模型官网
★以上由杉数科技投递申报的项目案例,最终将会角逐由数智猿×数据猿×上海大数据联盟联合推出的《2025中国数智产业AI大模型先锋企业》榜单/奖项。
该榜单最终将于9月8日北京举办的“2025第五届数智化转型升级发展论坛——暨AI大模型&AI Agent趋势论坛”现场首次揭晓榜单,并举行颁奖仪式,欢迎报名莅临现场: