公众号记得加星标⭐️,第一时间看推送不会错过。

GPU利用率和性能改进
深入研究 GPU 的架构,你会发现其核心包含大量的SIMD 单元,这些单元的作用是读取数据,执行矢量或标量 ALU(VALU 或 SALU)运算,并将结果写入渲染目标或缓冲区。这些单元存在于 Nvidia 所谓的流多处理器 (SM) 和 AMD 所谓的工作组处理器 (WGP) 中。充分利用 SIMD 单元和 VALU 吞吐量(即保持它们忙于工作)对于提升渲染任务的性能至关重要,尤其是在 GPU 越来越宽、SIMD 单元越来越多的时代。
为了读写其操作的数据,SIMD 单元通过一些“固定功能”单元与 GPU 的其余部分进行交互,例如用于处理数据请求的 TEX 单元、用于存储临时数据 (VGPR) 的寄存器文件、用于写入渲染目标的 ROP 单元,以及用于存储和读取数据的多个缓存。例如,这是 Blackwell 架构的 SM,展示了 VALU (FP32/INT32) 单元与之交互的一些单元。
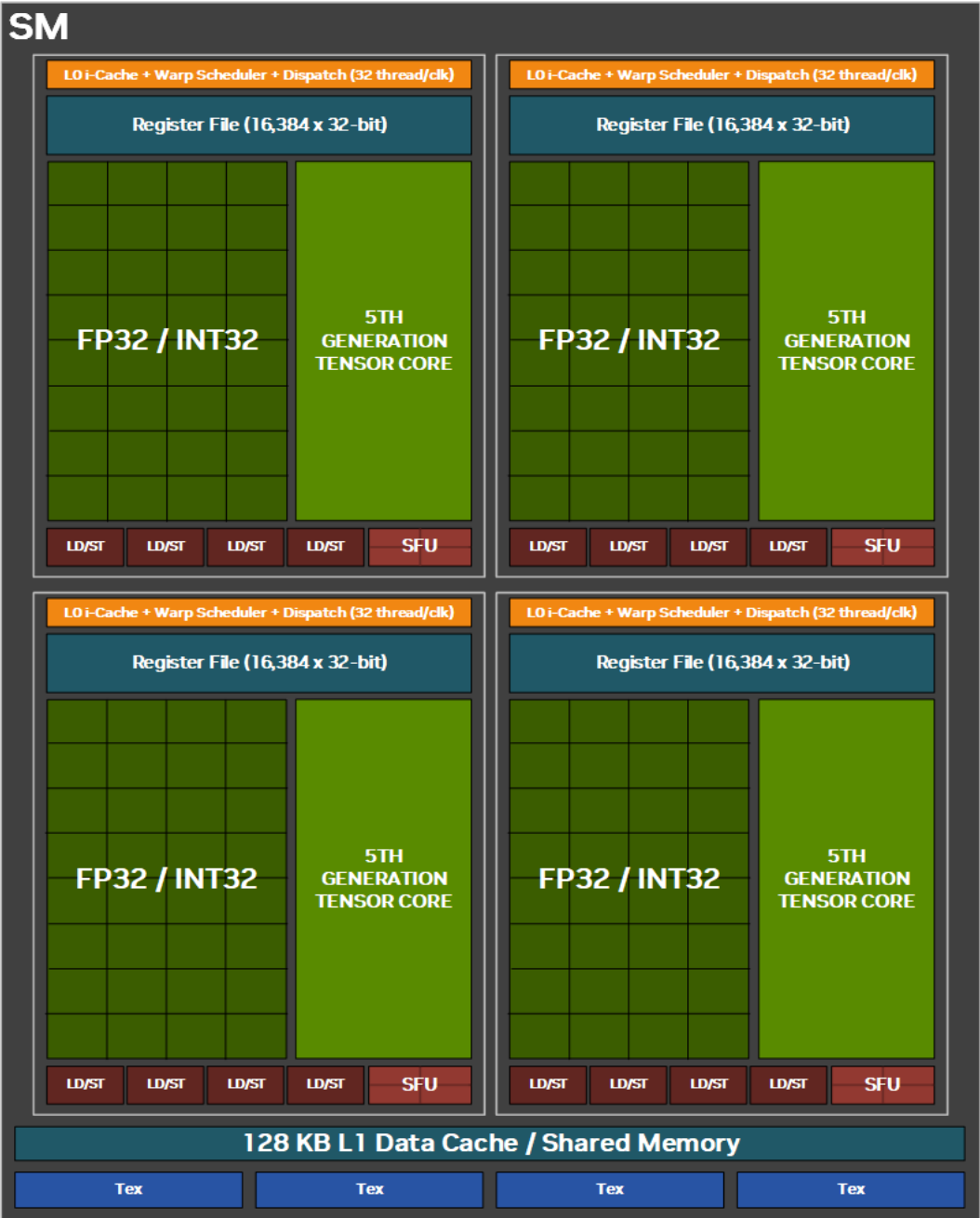
固定功能单元由于其工作性质简单而速度很快,但它们仍然可能成为瓶颈,导致 VALU 单元无法工作,或阻止其输出结果。因此,图形程序员的一个重要工作是分析渲染工作负载(绘制调用和调度),并尝试消除由上述固定功能单元以及其他单元(例如输入汇编器 (IA)、光栅单元以及内存带宽等)造成的瓶颈,因为这些单元会降低 VALU 的利用率。
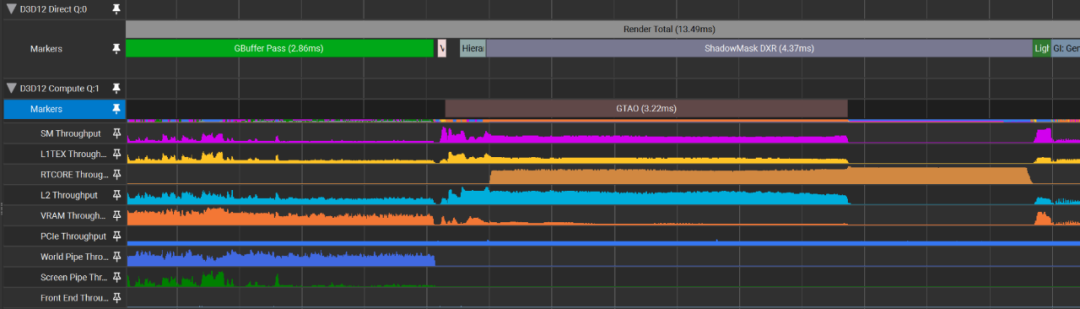
有时,由于渲染工作的性质,降低 VALU 利用率/吞吐量的瓶颈更难消除,例如阴影贴图通道在 VALU 工作上会很轻松,并且受到 IA(World Pipe)和内存(VRAM)的瓶颈,为其提供顶点数据,因此 SM 吞吐量(代码执行)会很低:

另一个例子是计算着色器通道,它会复制渲染目标或创建深度mipchain,此时着色器中的工作量不足以让VALU单元保持繁忙。在这种情况下,为了获得最佳效果,我们需要退一步,从整体上审视GPU性能,关注的不是单个渲染任务(绘制调用/调度)的性能,而是跨渲染任务,并衡量整个帧的改进。在这篇博文中,我将讨论一些可以用来实现这一点的技术。免责声明:任何性能优化工作的有效性在很大程度上取决于目标GPU、着色器编译器、渲染器和渲染内容,很难一概而论。一如既往,请谨慎对待任何建议,并始终分析您的用例。
短暂休息一下,讨论一下瓶颈。我多次提到了瓶颈,但如何才能确定真正的瓶颈是什么以及需要解决哪些问题呢?像 Nsight Graphics(GPU Trace)、AMD Radeon Profiler和PIX这样的性能分析工具都是不错的选择。使用性能分析工具,最简单的方法是绘制每个 GPU 单元的利用率图表来可视化瓶颈。对于 GPU Trace,也就是我上面发布的截图,它绘制的是各种“吞吐量”。通过这样的视图,我们很容易看出,例如,阴影贴图通道主要受 VRAM(内存带宽)和顶点输入(World Pipe)的约束(这意味着它最常使用那个单元/资源)。GTAO 通道受 L2 缓存的约束,而 ShadowMask 通道(用于计算光线追踪阴影)受 RT 核心的约束。这意味着,如果我们想要提升任何一个通道的性能,那么主要的瓶颈是我们首先应该解决的问题。
因此,首先值得强调的是,我们应该尽可能降低单个高开销 Drawcall 的成本/提高 VALU 的利用率,并针对其特定的瓶颈。例如,如果 Drawcall 受内存延迟限制,即 VALU 指令需要等待内存到达,那么可以通过减少 VGPR(矢量寄存器)分配来提高内存占用率,或者重新设计着色器,以便在内存读取和内存使用之间留出更多指令,例如部分展开循环,这些都是值得尝试的方法。此外,通过打包/压缩着色器的输入和输出来增加数据流以解除 VALU 阻塞(这适用于所有类型的着色器,包括顶点着色器,因为其导出属性的数量可能会成为某些 GPU 的瓶颈),以及观察数据访问模式并调整所使用的数据结构(例如,在 Nvidia GPU 上,结构化缓冲区在随机访问方面的表现优于常量缓冲区),这些方法都将获得回报。
如果瓶颈的性质决定了进一步提升性能并非易事,那么进一步提升仍有可能,但方法可能违反直觉。例如,如果着色器的占用率非常高,这可能会导致缓存抖动,因为不同的运行中的线程会尝试访问缓存。在这种情况下,可以通过增加 VGPR 分配(一种方法是创建一个永远不会被执行的虚拟大型动态分支)来降低占用率;或者,如果这是一个计算着色器,则可以通过执行虚拟组共享内存 (LDS) 分配来降低占用率。如果可能,最好使用 LDS 分配来限制占用率,因为让 VGPR 保持空闲状态可能对与此任务并行运行的其他任务有利(在同一图形管道上,但也使用异步计算,稍后会详细介绍)。然而,增加 VGPR 分配可能会带来其他积极的影响,编译器可能会利用这一点,并在着色器启动时批量加载纹理,以减少内存延迟。
另一件值得考虑的事情是,对于特定的工作负载,哪种着色器类型最合适。像素着色器是 GPU 几何处理流水线的一部分,这意味着它依赖于固定函数单元的输入(光栅化器和顶点着色器导出的数据)和输出,以及 ROP 单元写入渲染目标,因此它可能会受到其中任何一项的制约而成为瓶颈。屏幕空间、导出绑定的像素着色器(受 ROP 单元阻塞)或具有发散执行(即,warp/wave 中某些像素的早期输出)作为计算着色器可能会更有优势,因为计算着色器没有所有这些依赖项。此外,计算着色器可以访问另一种类型的内存,即组共享内存(或本地数据存储),它可以用作中间存储,在线程组线程之间共享数据,从而大幅加快执行速度。
另一方面,像素着色器管线可能拥有计算着色器所不具备的快速路径和功能。例如,GCN 在渲染后端单元中有一个专用缓存(“颜色缓存”),可以直接与 DRAM 通信以读取/写入颜色值,从而绕过二级缓存。这意味着使用像素着色器写入渲染目标可能比计算着色器更快,因为它可以释放二级缓存用于其他用途。不过,其他架构上可能不存在这种专用缓存。像素着色器也可以受益于硬件 VRS,从而降低成本,这一点值得考虑(尽管计算着色器也可以采用“软件 VRS ”解决方案)。像素着色器输出可以进行DCC 压缩,这可能会在后续将渲染目标作为纹理读取时提高内存带宽。此外,像素着色器(包括全屏着色器)可以受益于模板操作,甚至深度操作,以加快处理速度。不生成波形比生成波形并提前终止(由于某种情况而停止着色器执行)更快。
在决定将工作迁移到何处时,还应考虑每种着色器类型之间的工作分布差异。例如,GPU 会将整个线程组分配给特定的 SM 或 WGP,并且其所有 warp/wave 都将在同一个 SM/WGP 上执行。这对于缓存一致性和数据局部性非常有用,并且可以充分利用组共享内存,尤其是对于大型线程组而言。另一方面,大型线程组在 SM/WGP 上生成之前需要更多可用资源(VGPR/LDS),这可能会导致争用和延迟。像素着色器 wave 的生成更具预测性,会根据屏幕位置以平铺方式生成。

并可能提高执行速度。将 VALU 工作移至顶点着色器,以减轻受 VALU 约束的像素着色器的压力,是一种选择,但需要注意:由于波发射模式(例如,在 GCN 上每个计算单元一个波发射模式),顶点着色器的缓存一致性和数据局部性可能不太好;为剔除的三角形/像素完成的顶点着色器工作被浪费;此外,将数据从顶点着色器导出到像素可能会成为某些 GPU 架构的瓶颈。考虑到当前的三角形数量和密度,将工作移至顶点着色器可能不太吸引人。
在某些架构上,例如在 RDNA 上,可以选择 wave 大小,着色器类型也可能会影响执行和性能。在 RDNA 上,计算着色器每个 wave 以 32 个线程运行(wave32),而像素着色器则以 64 个线程运行(wave64)。对于严重依赖 wave intrinsic 的着色器,选择 wave64 像素着色器可能会更有优势,因为它可以完成更多工作(64 个工作项,而非 32 个)。此外,与前面提到的组共享内存相比,wave intrinsic 是一种更好的线程间数据共享方式,因为它存储在 VGPR 中,这是 SIMD 可用的最快存储方式。另一方面,对于执行方式不同的着色器(例如(随机)屏幕空间反射),选择 wave32 计算着色器可能会表现更好,因为 wave 更有可能在线程数较少的情况下提前完成并退出。值得一提的是,由于SM6.6 HLSL 为计算着色器定义了 WaveSize,因此在支持的情况下,也可以选择增加其大小。
将工作负载转换为计算着色器还有另一个潜在的巨大优势,它为使用异步计算与图形管道并行运行开辟了道路(即重叠顶点着色器、像素着色器,甚至其他计算着色器的执行)。异步计算是提高 VALU 利用率的绝佳工具,因为它可以重叠其他可能存在固定功能单元瓶颈的通道,并利用它们无法使用的资源。例如,缓存和 SM 瓶颈通道(GTAO),

可以与 RT Core 绑定通道 (Shadowmask) 完美搭配
使用通道无法使用的 GPU 资源。异步计算还可能与其他 VALU 利用率较低的通道重叠,例如 z-prepass 或阴影通道,这些通道可能主要受到几何吞吐量或像素着色器导出绑定通道(屏幕空间,但也可能填充 gbuffer,具体取决于材质着色器的复杂性)。这里有几件事值得考虑,目前没有 API 公开的方法来控制异步计算任务的执行,在优先级、节流以减少对图形管道的影响等方面(在 DirectX 12 上,我相信 Vulkan 公开了 VK_AMD_wave_limits),因此异步计算可能会对图形管道产生负面影响,这可能是可以接受的,只要并行运行的两个任务的总成本低于在图形管道上串行运行时的成本。虚拟 LDS(或者不太推荐使用 VGPR,因为它更有可能影响图形管道上的 wave 启动)分配和线程组大小也可用于影响异步计算任务的执行,例如,小型线程组可能比大型线程组重叠得更好,并且需要进行一些实验才能找到适合特定用例的正确配置。最后,关于计算着色器重叠的问题,在某些 GPU 架构上,只要没有屏障,图形管道上的计算工作可以与像素/顶点着色器工作重叠。
为了实现良好的渲染性能,消除固定函数和其他瓶颈,并允许 GPU 执行有用的工作至关重要。我们有很多工具和技术可以实现这一点,无论是单次绘制调用/调度优化,还是重叠工作以利用未使用的计算资源,即使这会增加单个渲染任务的成本。由于市场上 GPU 架构种类繁多,很难确定哪种方法最有效,而且需要反复试验才能确定哪种方法在每种用例中效果最佳,因为并非所有方法在所有 GPU 上都能同样出色地运行。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
END
今天是《半导体行业观察》为您分享的第4141期内容,欢迎关注。
推荐阅读

加星标⭐️第一时间看推送,小号防走丢













