公众号记得加星标⭐️,第一时间看推送不会错过。

近期发布的超以太网(Ultra Ethernet,简称UE)1.0规范,为未来人工智能(AI)和高性能计算(HPC)系统定义了一套变革性的高性能以太网标准。本文由该规范的编写者共同撰写,对超以太网的设计进行了高层级概述,为理解其创新点提供了关键的设计动因与科学背景。尽管超以太网在整个以太网协议栈中均实现了技术突破,但其最突出的贡献是创新性的超以太网传输层(Ultra Ethernet Transport,简称 UET)——这是一种可完全通过硬件加速的协议,专门为超大规模系统中的可靠、高速、高效通信而设计。
二十多年前,InfiniBand(无限带宽)是高性能网络领域最后一项重大标准化成果,而超以太网则充分利用了以太网庞大的生态系统,以及每传输 1 比特数据所带来的千倍级计算效率提升,开启了高性能网络的新时代。
引言
超以太网(UE)通过标准化的新协议,实现了基于以太网的高性能人工智能(AI)与高性能计算(HPC)网络支持。本文由超以太网规范的编写者撰写,补充了完整规范中的核心内容,重点阐述了历时近2.5年的研发过程中所涉及的技术发展历程与创新性技术要点。本文面向广大读者群体,因此对诸多细节进行了简化处理,并采用通俗易懂的表述与解释方式。有关超以太网的所有问题,最终权威参考依据为长达562页的完整规范。
2022 年,全球迅速迈入满足人工智能系统需求所必需的大规模计算新时代,此时各大数据中心服务商均意识到,InfiniBand 及其配套协议——基于融合以太网的远程直接内存访问(Remote Direct Memory Access over Converged Ethernet,简称 RoCE)——存在明显的局限性。与此同时,以太网作为通用互联技术的成功地位毋庸置疑:每年部署的端口数量高达数亿个,其发明者也在当年荣获了图灵奖。
大约十年前,RoCE v2(第二代 RoCE 协议)将 InfiniBand 的传输层嵌入到可路由的以太网(OSI 模型第3层,即网络层)中,从而实现了在数据中心的部署应用。RoCE协议几乎原封不动地沿用了InfiniBand的传输协议,要求网络提供无损传输能力,并保证数据包的严格按序交付。在融合以太网中,这种无损按序的数据包交付主要通过优先级流控(Priority Flow Control,简称PFC)机制来保障。
然而,PFC 需要为特定流量类别预留大量的头部缓冲空间,且容易引发拥塞扩散与队首阻塞(Head-of-Line Blocking)问题。此外,按序交付的要求限制了路径选择的灵活性,可能导致网络性能无法达到最优水平。RoCE协议的上述及其他局限性在文献中有详细总结。
最初的 InfiniBand 传输层协议诞生于 25 年前,当时的技术环境下,架构设计人员只能在有限的计算资源条件下尽可能提升带宽 。经过 25 年遵循摩尔定律的指数级发展,晶体管成本(进而带动计算成本)降低了超过 10 万倍,而可用带宽仅从单数据速率(Single Data Rate,简称 SDR)提升至扩展数据速率(eXtended Data Rate,简称 XDR),增幅仅为 100 倍。因此,不仅终端的加速器性能得到了显著提升,网络架构设计人员在每传输 1 比特数据时可利用的计算资源也增加了 1000 倍以上。这一变化促使众多企业开始重新思考内部 AI 产品线 [16,25,32] 与 HPC 部署中的网络协议栈设计。一些业内人士很早就意识到,数据中心网络与 HPC 网络必将融合为单一技术,随后几家企业开启了相关讨论,致力于推动这一融合进程。
2022 年第一季度,AMD、博通(Broadcom)、HPE、英特尔(Intel)和微软(Microsoft)等公司率先组建了一个小型工作组,一致同意基于各企业内部并行开展的技术研发成果,打造一套面向下一代以太网的开放标准,以开拓更广阔的市场。该项目最初名为 HiPER,后更名为超以太网(Ultra Ethernet,UE)。2022 年 7 月,新的联盟正式成立,并于同年 9 月举行了首次线下会议。在首次会议上,各方提出了广泛的意见:从“将某一种 RoCE 变体标准化”到“基于现有多种技术要素构建全新标准”,整个团队参与热情高涨,讨论氛围浓厚。2023 年 1 月,工作组确定了发展方向:融合为 HPC 设计的功能特性、安全机制,以及为数据中心设计的拥塞管理技术,打造一种全新的技术方案——一种可在传统以太网(plain old Ethernet)上运行的高可扩展性传输层协议。
不久后,2023 年 7 月,超以太网联盟(Ultra Ethernet Consortium,简称 UEC)由AMD、安华高(Arista)、博通(Broadcom)、思科(Cisco)、源讯(Eviden,原 Atos)、HPE、英特尔(Intel)、Meta和微软(Microsoft)联合正式宣布成立。作为 Linux 基金会联合开发基金会(Joint Development Foundation,JDF)旗下的开放项目,该联盟发展迅速,截至 2024 年底,成员公司已超过 100 家,参与人数超过 1500 人。
超以太网联盟(UEC)的目标是定义一套开放的下一代 HPC 与 AI 网络标准,该标准需与现有以太网部署兼容,且支持不同厂商设备间的互操作。联盟的讨论围绕以下几项核心原则展开:
大规模可扩展性:满足未来 AI 系统大规模部署需求的关键。超以太网(UE)设计支持数百万个网络端点以灵活的方式部署,并提供无连接 API(Connectionless API)。初期,超以太网重点支持传统的胖树(fat tree)拓扑结构,同时不限制其他经过优化的拓扑(如汉明网格(HammingMesh)、蜻蜓(Dragonfly)或精简飞(Slim Fly))的应用,不过联盟尚未对这些非传统拓扑进行测试验证。
高性能:通过专为大规模部署设计的高效协议实现。例如,超以太网的无连接 API 通过一种无需额外延迟即可建立端到端可靠性上下文的机制提供支持——即首个到达的数据包即可建立上下文(耗时可低至纳秒级),即便在数据包大规模乱序交付的场景下也能实现。此外,超以太网还支持可选的扩展功能,如数据包裁剪(packet trimming),可实现快速的丢包检测与恢复。
与现有以太网数据中心部署的兼容性:通过对交换机基础设施提出最低限度的要求,超以太网实现了与现有以太网数据中心部署的兼容性,便于现有基础设施的轻松部署与逐步扩展。超以太网交换机仅需支持等价多路径(Equal-Cost Multi-Pathing,简称 ECMP)和在出口端标记的基础显式拥塞通知(Explicit Congestion Notification,简称 ECN)功能,同时可(可选)支持数据包裁剪功能以提升网络性能。超以太网无需对物理层(PHY Layer,OSI 模型第 1 层)或数据链路层(Link Layer,OSI 模型第 2 层)进行修改,但为提升新部署场景下数据链路层的性能,定义了若干可选扩展功能,为厂商差异化竞争提供空间。超以太网完全兼容以太网标准,这意味着用户可使用现有的运维管理、调试与部署工具。
厂商差异化:在规范确保互操作性的前提下,超以太网最大限度地支持厂商差异化创新。这使得现有的以太网厂商生态系统能够在活跃且庞大的市场中,推动快速的创新周期与技术研发。在诸多场景中(如数据包负载均衡、快速丢包检测),规范仅提出一组可实现兼容协议的选项,而非强制要求采用特定方案。厂商既可选择规范中提出的某一种方案,也可自主研发创新方案。这一设计使架构师能够根据系统优化目标进行定制化设计,例如,厂商可选择特定的负载均衡与丢包检测方案,以打造易于运维、性能可靠的高性能系统。
适用范围
超以太网将网络划分为三种基本类型:本地网络(通常称为纵向扩展型网络,scale-up)、后端网络(通常称为横向扩展型网络,scale-out)和前端网络。图 1 展示了这三种网络类型的架构。本地网络(紫色)用于连接中央处理器(CPU)与加速器(XPU,如 GPU、TPU 等),当前的典型部署场景中,此类节点级或机架级网络采用 CXL、NVLINK 或以太网技术,传输距离可达 10 米,延迟目标为亚微秒级。前端网络(绿色)是传统的数据中心网络,承担 “东西向”(数据中心内部)和 “南北向”(数据中心与外部)流量传输。后端网络(蓝色)是连接计算设备(如加速器)的高性能网络。后端网络与前端网络通常均被称为 “横向扩展型网络”,二者可通过单一物理网络实例实现,实际上超以太网也支持这种网络融合部署,同时也允许采用物理上独立的网络实例分别部署。
超以太网的关键特性
超以太网(UE)可在现有以太网网络上无缝运行。规范建议将超以太网流量分配至独立的流量类别,但其拥塞控制算法也可与其他流量共享交换机缓冲区,实现协同工作。超以太网采用与 IPv4 或 IPv6(OSI 模型第 3 层)兼容的(可路由)地址与包头格式,确保无缝集成。超以太网将结构端点(Fabric Endpoints,简称 FEP)定义为逻辑实体,负责终止单播操作中传输层的两端。从功能上看,结构端点(FEP)大致相当于传统的网络接口控制器(Network Interface Controller,简称 NIC,即网卡)。

超以太网的关键特性包括:
采用临时数据包传输上下文(Ephemeral Packet Delivery Contexts,简称 PDC)的高可扩展性无连接传输协议;
在语义层去除面向连接的依赖,包括缓冲区地址映射、访问授权与错误模型;
原生支持逐包多路径传输(“数据包喷洒”,packet spraying),结合灵活可扩展的负载均衡方案,且无需接收端进行乱序重组;
支持可靠与不可靠两种传输模式,且每种模式下均支持按序与乱序交付,可最优覆盖各类应用场景;
支持有损(尽力而为)传输模式,避免队首阻塞(Head-of-Line Blocking),同时结合可选的数据包裁剪及其他快速丢包检测方案,实现快速恢复;
创新性的拥塞管理方案,可快速适应入向拥塞(incast traffic)与网络内拥塞;
支持厂商提供纯硬件、纯软件或软硬件混合部署的产品;
集成可扩展的端到端加密与认证功能;
链路层优化,支持硬件加速部署。
下文将在超以太网架构部分详细阐述这些特性及其他功能。在此之前,首先介绍基于 ECMP 的数据包喷洒技术——这是超以太网中负载均衡的基础概念。
ECMP 数据包喷洒
等价多路径(ECMP:Equal-Cost Multi-Pathing)是一种用于网络流量负载均衡的方案。支持 ECMP 的交换机不会将目标地址直接映射到单一端口,而是映射到一组通往目的地的等价成本路径所对应的端口。随后,通过确定性哈希函数p=H(x)为每个数据包选择输出端口P。哈希函数的输入通常是可配置的,一般包含完整的 IP 五元组(源地址、目的地址、源端口、目的端口及协议类型)。因此,若直接采用传统 ECMP 方案,同一流的所有数据包会沿同一条确定性路径传输(无故障情况下)。超以太网对其中一个字段进行重新定义,用于承载所谓的熵值(Entropy Value,简称 EV)。例如,若采用标准 UDP/IP 协议,该字段为 UDP 源端口(传统场景下此端口未被使用)。
互联网号码分配机构(IANA)已将超以太网传输层协议(UET)分配至 UDP 4793 端口,该端口不仅是一个较大的质数,同时也是 RoCEv2 端口号的增量值(++RoCEv2++)。超以太网还支持原生纯 IP 模式,在此模式下,熵值(EV)的位置与 UDP 源端口保持一致。此时,源结构端点(FEP)可为每个需沿不同路径传输的数据包选择不同的熵值(EV);若需按序交付,则为数据包分配相同的熵值(EV)。
图 2 展示了基于 8 端口交换机(绿色圆圈)构建的全 Clos 网络架构,该架构支持 64 个端点(灰色方块)。图中重点标注了第二层的交换机 X,其包含 4 个上行端口与 4 个下行端口。数据包在网络中传输时,首先通过下行端口进入交换机,除非目的地是该交换机所属树形结构的上层节点,否则将通过上行端口转发。在 Clos 网络中,当数据包到达源端点与目的端点的公共上层交换机后,会转向唯一的下行路径。以图中网络为例,64 个端点分为 4 组,每组 16 个端点;同一组内任意两个节点(如节点 C 与节点 D)之间存在 4 条等价成本路径(均需经过 3 跳交换机,图中绿色与红色路径);不同组内任意两个节点(如节点 A 与节点 B)之间则存在 16 条路径(图中紫色与黄色路径)。

由于设计简洁,传统 ECMP 方案存在一定局限性:节点无法直接选择路径,仅能确定在无故障场景下,具有相同熵值(EV)的两个数据包会沿同一路径传输;但无法确定不同熵值(EV)是否会因哈希冲突而共享同一条路径。事实上,这种哈希冲突及相关的(子)路径共享是普遍存在的!以同一组内节点为例,仅存在 4 条不同路径,但熵值(EV)的取值范围却高达216种。因此,对于理想的均匀分布哈希函数,随机选择两个熵值(EV)时,冲突概率高达 25%;而不同组内节点间的冲突概率也仍有 6.25%。在实际部署中,若采用更大端口数的交换机,上述概率可能会有所不同。
若两条路径发生冲突,每条路径的可用带宽将减半,可能导致严重的性能损失。在传统以太网系统中,路径一旦确定便不再改变,这会引发一种名为 “流量极化”(traffic polarization)的现象,问题将更为突出。
UE 的数据包喷洒技术通过为每个数据包分配不同 EV,可避免此类极化现象,从而在统计意义上实现数据包在所有交换机间的均匀分布。即使发生哈希冲突,冲突持续时间也较短,且交换机缓冲区可吸收由此产生的流量不均衡,最终实现网络带宽的充分利用与长期平均流量均衡。若所有端点均实现均匀喷洒,数据包喷洒机制将非常简洁;但部分流需按序交付(因此需确定性占用部分路径)时,机制实现将更具挑战性。UE 提供多种可选负载均衡算法,用于确定每个数据包的 EV 分配方式;最优方案的选择仍为厂商差异化与学术研究保留空间。
超以太网配置文件
UE规范提供了三个配置文件(HPC、AIFul和AlBase),以支撑不同的功能集,从而支持不同复杂度的实现。HPC配置文件提供了最丰富的功能集,包括通配符标记匹配,并针对MPI和OpenSHMEM工作负载进行了优化。AIFul配置文件是AlBase配置文件的超集。两者都针对无需通配符标记匹配或其他高级通信操作的集合通信库(*CCLs)而设计。两个AI配置文件都提供了可延迟的发送功能,该功能专为*CCL通信卸载而设计。此外,AIFuIl提供精确的标签匹配功能。Al Base 设计时考虑到实现复杂度最低,假设匹配协议的其他部分由libfabric提供者或客户端库(例如 CCL)来处理。
HPC配置文件是Al Base配置文件的超集,通过实现可延迟发送,-个实现可以同时提供HPC配置文件和AI Full配置文件。libfabric定义在UE上使得一个端点可以宣传多个配置文件,然后与具有最大公共特性集的相应配置文件进行协商。
超以太网架构
下文将详细拆解 UE 架构的组成部分,按照 TCP/IP 标准分层模型(从第一层到第四层)展开,架构示意图如图 3 所示。

我们从图的最左下角开始,即以太网中的最低层,即物理(PHY)层。该层基本上未因UE而改变,以保持与任何以太网部署的兼容性。首批UE产品将支持100G/lane信令或200G/lane信令。接下来的层是(数据)链路层,该层也与标准以太网兼容,以实现互操作性。它包含两个可选且兼容的UE扩展:基于信用的流量控制(CBFC)和链路级重试(LLR),我们将在第3.5节中予以说明。 网络层采用相应的RFC所定义的标准的IPv4或IPv6,以允许沿用旧有的数据中心路由和操作方式。在网络层内,交换机可以实施包修剪功能,这是一种可选特性,使目标能够检测网络中的丢失包。传输层是迄今为止最显著的改变,因为它被专门定义用于UE。它被设计用于在标准IP/UDP上运行或者原生在IP上运行。它可以被细分为四个子层:语义层(SES)、包交付层(PDS)、拥塞管理层(CMS)以及传输安全层(TSS)。
TSS 对 PDS和 SES(包括有效载荷)进行加密,并通过验证IP地址来限制利用传输标头字段欺骗或“猜测”的攻击。与 PDS结合使用时,TSS 旨在防止重放攻击,并通过与语义子层(SES)集成来减少协议层攻击,如不当使用凭据。CMS在字节级别工作,并使用拥塞控制上下文(CCCs)来控制发送窗口的大小。PDS将一个或多个数据包交付上下文(PDC)与每个 CCC 关联,并在数据包级别工作。PDS负责可靠地传输数据包,并在消息处理方面与 SES 合作。SES管理使用数据包实现的通信事务。它直接与应用程序层中的 libfabric接口相连。UE 1.0 使用libfabric作为与更高层次软件及库(如 CCL和 MPI)交互的接口。SES还管理在目标上执行的操作,例如将 RMA操作提交到内存中。
传输语义子层(SES)
libfabric 接口利用超以太网传输(UET)层的 SES,来提供用户标记的发送 / 接收和 RMA 操作。超以太网的 SES 定义了一种受 Portals 4 规范 [9] 启发的有线协议和语义,以实现高效、轻量级的 libfabric 提供程序。与许多网络 API 不同,libfabric 和 Portals 4 一样,将传统的网络语义(寻址、完成、授权和故障处理)与连接的概念分离开来。下面将更详细地探讨这种差异如何驱动传输层的定义。
一、地址解析
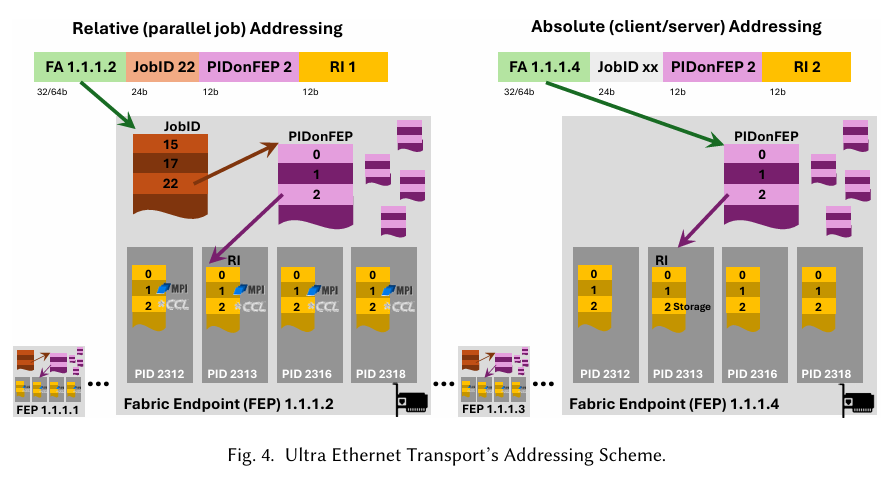
与多数基于以太网的网络 API 一致,UE 采用 IP 地址(即结构地址,Fabric Address,FA)选择端点(FEP)。为实现可扩展地址解析,UE 进一步通过 “作业标识(JobID,24 位)”、“目标 FEP 上的进程标识(PIDonFEP,12 位)” 与 “资源索引(RI,12 位)”,定位每个端点上的逻辑上下文。UE 定义两种地址解析模式,核心差异在于 PIDonFEP 的解读方式(PIDonFEP 用于标识目标 FEP 上的地址空间(进程));资源索引则用于选择目标进程中的接收上下文(如 send/recv 队列、RMA 匹配缓冲区与完成队列)。
支持的两种进程寻址模式,分别是用于集群中分布式并行作业的相对寻址,以及用于客户端-服务器应用程序的绝对寻址。它们通过数据包报头中的 rel 位来区分。在相对寻址中,每个并行作业由唯一的 JobID 标识。在这里,FA 标识系统中的一个 FEP(灰色节点)。每个 FEP 都有一个全局 JobID 表,传入的数据包会与该表进行匹配。每个 JobID 表项标识系统中在该节点上运行进程的一个作业,并指向本地的 PIDonFEP 表。PIDonFEP 表标识由 JobID 标识的作业中的所有进程(地址空间)。然后,表项会解析为每个进程的资源索引表,该表本身附带服务或其他进程本地资源。
在图 4 所示的示例中,该地址标识了 FEP 为 FA 1.1.1.2 的节点上,进程 2313 中的 MPI 端点。如果所有端点的进程数量相同,相对寻址方案支持将节点本地寻址和全局寻址解耦。在直接寻址中,每个源进程需要存储 N*P 个条目,以寻址 N 个节点,每个节点有 P 个进程。而使用超以太网的相对寻址,每个源节点只存储 N 个条目,并可以将目标进程计算为相对于每个节点的 PIDonFEP 表偏移量。
如图 4 右侧所示,绝对寻址用于客户端 / 服务器应用程序,以访问固定的网络服务,如存储或微服务。此类服务不属于作业的一部分,因此 JobID 不用于寻址(它仍在报头中携带,可作为认证令牌)。在绝对寻址模式下,PIDonFEP 可像 UDP 端口一样使用。超以太网还支持将 PIDonFEP 和资源索引(RI)合并到单个表中。
通常,发送/接收、带标记操作和 RMA 操作使用不同的 RI 表。RMA 操作携带一个额外的内存密钥(在 64 位匹配位中),用于在 RI 上下文中识别目标缓冲区。如果缓冲区可以直接与 RIs 关联,则可以在优化的报头格式中省略此内存密钥。授权通过 JobID 来确保,因此 JobID 需要由可信实体分配。可使用 3.4 节中描述的 TSS 来防止网络内的操作篡改。
这些寻址机制实现了超以太网提供的关键可扩展性增强之一。与现有机制相比,例如 InfiniBand 的 Verbs [23],最初设计为将每个队列对(QP)与一个接收队列相关联。然而,用户很快发现,在一个拥有 10,000,000 个核心的系统中,为每个通信对等方关联一个接收队列所需的内存是难以承受的,因此创建了共享接收队列。相比之下,超以太网模型允许用户在源端无需上下文即可寻址队列。JobID + PIDonFEP + RI 唯一地寻址一个 FEP 上的单个队列,这使得传统 RDMA 网络中的共享接收队列概念变得多余。应用程序中的任何一方都可以向此队列发送数据,并且 JobID 提供了写入该队列的授权。
这种没有队列对作为连接的设计,还有一个有利的副作用,即它实现了更简单的每个事务故障和错误处理,避免了传统 RDMA 系统中队列错误状态带来的显著复杂性。
二、消息传递和匹配
在接收端,每个 RI 都有一个关联的接收队列,到达的消息会与该队列中的一个条目进行匹配。无标记操作按在接收端添加条目的顺序使用这些条目。带标记的消息使用标记选择一个条目。如果消息是 “意外的”(没有匹配条目),接收端可以丢弃该消息并发送 “缓冲区未准备好” 响应,或者缓冲其报头。可选地,接收端也可以缓冲部分有效载荷,直到接收缓冲区被提交,详见下文的可延迟发送和会合协议。
硬件消息匹配通过数据包携带的发起者 ID(32 位)和匹配密钥(64 位)来支持。MPI或集体通信库(CCL)程序会将源等级编码到发起者 ID 中。额外的匹配密钥位可用于编码通信上下文(例如 MPI 通信器)和消息标记。HPC 配置文件支持有序通配符匹配,这在硬件实现上存在一些挑战 [15]。AI Full 配置文件使用精确匹配且无需排序,以支持简单的基于哈希或内容寻址存储器(CAM)的实现。AI Base 配置文件在传输层不支持匹配。
为什么要选择纳入匹配功能呢?简单来说,匹配是 HPC(例如 MPI)中的基本语义,在无序网络中,它成为支持最常见的 CCL 消息传递语义的有用工具。通过将 AI Full 配置文件限制为精确匹配,并简化意外消息语义(见下文),可以保持实现的简洁性。在此过程中,我们获得了一个强大的工具:使用带标记的匹配,消息(例如 nccl_send)可以通过无序协议在网络中传输,并最终到达正确的缓冲区。这是通过让上层(即 CCL)将消息序列号放入匹配位来实现的。
处理大型意外消息:可延迟发送和会合协议:传统上,短的意外消息会直接在接收端缓冲,然而,大型意外消息需要不同的处理机制。三种配置文件对大型意外消息(在超以太网中,大型消息指超过当前发送窗口大小的消息。在许多现有通信库中,为简单起见,该大小通常由一个名为 “热切限制”se 的可配置参数定义)的处理方式各不相同。如果消息到达时,接收地址已知(即应用程序已调用接收操作),则该消息在接收端被称为预期消息,否则为意外消息。由于各种因素,如负载不平衡,意外消息往往难以避免,在某些应用程序中甚至非常常见。
会合协议:在传统的 HPC 会合协议中,小消息通过单步发送,而大消息则分两步发送 —— 首先发送大小为se 的第一部分,以及剩余数据的本地地址,然后通过 RMA 读取从源地址获取第二部分。图 5 左侧展示了预期和意外大消息的协议流程。在发送会合发送之前,实现可能会查询当前窗口大小,以便将发送大小调整为最佳值。预期情况中,热切发送步骤用绿色表示,读取步骤用蓝色表示。意外情况则有一个额外的控制消息,用于通知源端消息未匹配。
可延迟发送:可延迟发送协议如图 5 中间部分所示。预期消息会像普通发送一样处理,无论大小,消息都会被完整发送并复制到接收缓冲区。与会合协议类似,小的意外消息可能会在接收端缓冲。如果无法缓冲的大型意外消息的第一个数据包到达,接收端会立即回复一个响应消息,告诉源端延迟(停止)发送。大型意外消息允许在接收端部分缓冲数据包(例如,一个窗口大小)。在接收端为延迟消息发布匹配的接收操作后,会向发送端发送恢复消息的请求。为简化实现,每个可延迟发送都携带一个来自源端的令牌(发起者重启令牌,irt),用于标识消息,每个响应都携带本地存储数据的大小,以及接收端的消息标识令牌(目标重启令牌,trt)。这种令牌的使用允许双方进行简单的基于表的匹配。可延迟发送支持高效的低资源硬件卸载实现,因为它们不需要 RMA 读取支持(注:超以太网联盟决定在 AI Full 中强制要求支持 RMA 读取,以支持存储用例)。它们也可以被视为对传统的、有时很麻烦的 “接收方未准备好”(RNR)流 [22] 的优化,将难以配置的超时替换为明确的信号。此外,可延迟发送可以在发送过程中对发送窗口大小的变化做出反应,因此总是发送最佳大小的数据,以充分利用带宽,避免众所周知的从热切发送到会合发送的带宽下降 [37]。
接收方发起:AI Base 配置文件不要求支持上述任何选项。相反,实现者可以选择由软件驱动的接收方发起协议,如图 5 右侧所示。在此方案中,硬件支持可以最小化,仅支持将单个数据包发送操作到专用缓冲区,以及仅支持 RMA 写入。单个数据包发送操作用于将所有有效载荷的 RMA 写入所需的所有信息发送给发送方,从而使发送方从软件(即提供程序实现)发起写入操作 [16]。其代价是发送方需要一些异步活动(例如一个线程)来发起写入。此外,在最坏的情况下,如果发送操作恰好在接收操作发布前21 RTT 时提交,该协议会增加一个往返时间(RTT)。

在图 5 中,UET 框表示超以太网传输层在流程中的参与。红色闪电表示意外消息的到达。我们假设接收端仅存储报头(超以太网允许不存储任何内容,这将要求发送方在超时后重新传输;仅存储报头;或者存储原始事务的报头和(部分)有效载荷,这将在提交接收操作时导致本地复制步骤)。蓝色星号表示发送端的完成,黄色星号表示接收端的完成。为了便于阅读,省略了 PDS 确认;如果考虑这些确认,源端的完成事件将延迟最多 1 个 RTT。
现在,我们可以针对每个配置文件,区分预期、意外、小消息和大消息的所有组合的四种不同情况。下表模拟了每个配置文件中四种情况下接收端(黄色星号)的完成时间。我们用 α 表示延迟(½RTT),β 表示带宽倒数(每字节时间),s 表示消息大小。发送操作在ts 时刻提交,接收操作在tr 时刻提交;在预期情况下,ts≥tr−α ,在意外情况下,ts<tr−α 。该表显示了上述讨论的最坏情况下ts 和tr 的延迟。我们假设接收端仅能缓冲报头。

请注意,会合协议和可延迟发送在运行时看似相同——这仅适用于发送窗口恒定且精确的情况。由于额外的 RTT(2α)惩罚,如果接收操作可以在tr<ts−α 时提交,则接收方发起的传输预计在处理非常大的消息时表现最佳。
RMA 读/写:超以太网支持存储或单边分布式算法及同步(例如图问题 [4])等工作负载的 RMA 读和写操作。超以太网的写操作很直接,将完整的地址,包括 Job ID、PIDonFEP、资源索引、目标内存密钥、目的地址和偏移量,编码到每个数据包中,以便数据包可以无序写入目标缓冲区。顺便提一下,这同样适用于发送/接收消息传递。
超以太网的读操作旨在最小化目标 FEP 上典型读操作的状态,并在读取者之间提供一定的公平性。因此,它采用单数据包读取方式,发起者发出一系列≤MTU 大小的读请求,目标逐个满足这些请求(也可能是无序的)。如果目标不需要完成通知,则在此协议中只有发起者会保留每个消息的状态。发起者可以在必要时对请求进行速率限制,并且来自多个发起者的许多读取操作可以在目标端交错进行。这与目标端传出拥塞控制上下文中基于窗口的流控制形成了复杂的关系,每个实现都需要对其进行管理。
超以太网在网络结构中设计使用两类流量类别(TC):拥塞管理子系统(CMS)将一类用于批量数据传输,另一类用于控制流量(如确认帧 ACK)。这种分类机制加快了拥塞信息的传递速度,并降低了携带拥塞信息的确认帧丢失概率。尽管超以太网的核心设计面向尽力而为(有损)网络,但它同样支持无损网络(如 Slingshot [13])。为避免协议相关(或消息相关)的死锁问题,超以太网为无损网络定义了两类流量类别的独立映射规则。早期部分大规模并行处理(MPP)设计通过两类消息类别(或虚拟通道类别)避免消息相关死锁;对于消息传递系统,宋等人基于早期死锁避免路由算法的核心原理,对这一机制进行了形式化定义。
在无损网络中,当请求与响应之间存在资源依赖关系(如数据包与确认帧、读请求与读响应)时,可能引发死锁:若缓冲空间耗尽,目标端因无法生成响应而无法继续接收请求,死锁便会产生。有损网络通过在传输无法推进时直接丢弃数据包来解决死锁问题;纯发送或纯写操作类协议则可借助累积确认机制避免死锁 —— 该机制允许写操作持续被接收而无需立即生成确认。而集成读操作的无损网络协议主要分为两类:一类通过两类流量类别(分别用于读请求和读响应)实现,另一类则在目标端为读请求预先预留缓冲空间(如 RoCE 和 InfiniBand)。长期以来,资源预预留的要求导致远程直接内存访问(RDMA)读操作的性能表现不佳,且这些预预留资源通常与连接结构(如队列对)相关联,而超以太网中并不存在此类结构,因此超以太网选择采用第二类流量类别来解决这一问题。
传输层数据包交付子系统(PDS)
超以太网引入了创新性的数据包交付子系统(PDS),该系统借助临时数据包交付上下文(PDC)管理数据包从源端到目标端的可靠传输。数据包交付上下文(PDC)可在首个数据包到达时即时建立,无需额外延迟。同时,超以太网禁止在网络中对数据包进行分片处理,除消息的最后一个数据包外,所有数据包均以满最大传输单元(MTU)有效载荷的形式发送,这一设计大幅简化了数据包跟踪逻辑。
超以太网传输层(UET)的数据包交付子系统(PDS)定义了三类数据包:一是请求数据包,用于传输数据(写操作和发送操作中从发起者到目标端,或读操作中从目标端到发起者);二是确认数据包,用于携带此前请求数据包的相关信息;三是控制数据包,用于传输层特定控制操作(如检查接收端的数据包状态或路径状态)。
数据包传输模式:超以太网的设计可支持多种应用场景,包括需严格按序传输的向后兼容工作负载、完全无序的传输场景,以及介于两者之间的各类场景。它提供四种数据包排序与可靠性传输模式,分别是可靠无序交付(RUD)、可靠有序交付(ROD)、不可靠无序交付(UUD)和幂等操作可靠无序交付(RUDI);由于在规范制定时未发现相关应用场景,超以太网暂不支持不可靠有序交付模式。
可靠无序交付(RUD)是默认的批量传输模式,适用于所有大型消息传输场景,且在无需通配符匹配的场景(如 AI 类配置文件)中,可用于所有传输操作。对于 AI Full 配置文件中的可靠无序交付(RUD),一种可能的实现方案是为每个已提交的发送和接收操作分配消息标识(mid,从 0 开始递增),并将消息标识(mid)与通信器标签共同纳入匹配逻辑 —— 这样一来,无论数据包在传输过程中的顺序如何,发送至特定目标端的首个发送操作都能与该目标端的首个接收操作匹配,且本地每提交一次发送或接收操作,消息标识(mid)都会递增。由于可靠无序交付(RUD)支持数据包喷洒技术(详见 3.3 节),因此它被视为超以太网中效率最高的可靠传输模式。
若在数据包级别需严格按序保障(如 RoCE 或 InfiniBand 的按序要求),可采用可靠有序交付(ROD)模式。例如,在 HPC 配置文件中,MPI(消息传递接口)要求支持带按序保障的通配符匹配,此时便需使用该模式。一种简单的协议实现方式是:通过可靠有序交付(ROD)通道传输会合消息(rendezvous message)的所有 “即时部分”(eager portion),同时通过可靠无序交付(RUD)通道发起读操作。此外,先进的消息匹配策略可能进一步放宽这一限制 [15]。对于资源受限的端点(如网络内计算交换机或简单存储设备),可靠有序交付(ROD)同样适用 —— 它仅需实现简单的 “回退 N 帧”(go-back-N)机制(与 RoCE 类似)。但由于可靠有序交付(ROD)为每个流单元(flowlet)仅使用一条网络路径 [7,36],因此它被视为超以太网中效率较低的可靠传输协议。
若需实现不可靠数据报通信,可采用不可靠无序交付(UUD)模式,该模式有助于实现基于软件的协议部署或系统管理任务。
幂等操作可靠无序交付(RUDI)旨在支持可在目标端多次执行的幂等操作——例如,在应用程序未访问或修改目标值的前提下,相同的读或写操作可多次执行且不改变最终结果。该模式允许实现者在目标端省略对重复数据包 / 消息(重传)的过滤步骤,以提升实现效率。由于无需维护接收端状态,幂等操作可靠无序交付(RUDI)是扩展性最优的模式,但它的使用门槛较高(用户需确保同步周期内的数据一致性),且不适用于原子加法等非幂等操作。该协议仅针对特殊应用场景设计,且仅在 HPC 配置文件中提供。
需注意的是,所有无序数据包传输模式均可能导致数据无序到达主内存,因为语义子层(SES)不会对数据包进行重排序处理。
超以太网(UE)报头:每个超以太网数据包均携带各子层的报头,其中许多报头为可选或可配置类型,因此数据包报头存在多种不同大小的配置方案。如图 3 所示,每个数据包均包含 14 字节的标准以太网报头和 4 字节的帧校验序列(FCS)。超以太网传输层(UET)可在 UDP/IP 之上运行,也可选择原生在 IP 上运行(此时会用 4 字节的熵值报头替代 8 字节的 UDP 报头)。数据包交付子系统(PDS)报头的大小根据传输模式有所不同:可靠无序交付(RUD)和可靠有序交付(ROD)模式下为 12 字节(若使用 RCCC 拥塞控制则为 16 字节,详见 3.3 节),幂等操作可靠无序交付(RUDI)模式下为 8 字节,不可靠无序交付(UUD)模式下为 4 字节。在帧校验序列(FCS)之前,可选择添加 4 字节的端到端循环冗余校验(CRC)字段,用于对报头和数据进行完整性校验。语义子层(SES)报头则包含三种类型:标准操作使用 44 字节报头,不超过 8 千字节(8kiB)的匹配消息使用 32 字节报头,非匹配消息使用最小 20 字节报头。当需要安全保障时,可在数据包交付子系统(PDS)报头前添加可选的传输安全子层(TSS)安全报头(若使用显式源标识则为 16 字节,否则为 12 字节),并在数据包末尾、帧校验序列(FCS)之前添加 16 字节的完整性校验值(ICV)。由于完整性校验值(ICV)的安全性远高于数据包交付子系统(PDS)的循环冗余校验(CRC),若使用完整性校验值(ICV),可省略循环冗余校验(CRC)字段。超以太网报头的整体结构可参考图 3。
超以太网提供多种报头选项,为厂商差异化创新提供空间。例如,拥塞控制字段包括目标拥塞控制上下文中的接收字节数(RCVD_BYTES)、目标端本地处理数据包的时间(SERVICE_TIME),以及用于直接调整发送窗口大小的信用额度(CREDIT)字段;同时支持选择性确认(SACK)偏移量、64 位位图(Bitmap),以及可选的无序数据包计数(OOO_COUNT),以支持无序数据包处理。这些字段有助于实现更优的流控和拥塞管理。此外,厂商可通过专用编码携带私有信息以实现特定扩展——超以太网在数据包交付子系统(PDS)类型、语义操作码和确认状态的编码空间中,专门为厂商扩展预留了部分空间。
动态数据包交付上下文(PDC)创建:数据包交付上下文(PDC)的创建无需额外延迟,因为建立连接所需的所有状态信息均包含在数据包包头中。该协议甚至支持为无序可靠无序交付(RUD)通道建立连接。图 6 左侧展示了发起者和目标端的简化数据包交付上下文(PDC)状态机,右侧则展示了数据包交付上下文(PDC)的建立与关闭流程。其中,数据包序列号(PSN)用于标识数据包,数据包交付上下文标识(PDC ID)用于在源端和目标端标识数据包交付上下文(PDC)。该状态机未包含初始化阶段的大部分错误/数据包丢失处理逻辑(同步(SYN)状态下的红色自循环),以及可能需要重传的中间状态转换过程。
右侧场景展示了三条消息的传输过程:首先是包含 5 个数据包的写操作(数据包序列号 PSN 4-8),随后是包含 3 个数据包的读操作(数据包序列号 PSN 9-11 和 PSN 2-4),期间发起者收到关闭请求。
该场景初始状态为无数据包交付上下文(PDC),且存在语义子层(SES)发起的写请求。源端通过发送首个数据包建立标识为 7 的数据包交付上下文(PDC),并发送以随机数据包序列号 4 开头的三个数据包至目标端。当首个数据包到达目标端时,目标端创建新的数据包交付上下文(PDC)(本场景中标识为 19),并在每个确认数据包中携带新建立的数据包交付上下文标识(PDCID)。一旦源端收到包含有效目标端分配数据包交付上下文标识(PDCID)的首个确认数据包,便会转换至 “已建立”(ESTABLISHED)状态,并继续发送无需携带同步(SYN)标识的数据包——需注意的是,在数据包交付上下文(PDC)建立过程中,源端始终以满速率发送数据包。当首个不携带同步(SYN)标识的数据包到达目标端时,目标端同样转换至 “已建立”(ESTABLISHED)状态。双方均进入 “已建立” 状态后,数据包交付上下文(PDC)将正常工作,数据包序列号(PSN)空间保持同步。
当数据包交付上下文(PDC)处于空闲状态时,由发起者启动关闭流程。发起者无需在数据包交付上下文(PDC)空闲后立即关闭,目标端可通过控制数据包或确认数据包中的标志位,请求发起者关闭数据包交付上下文(PDC)。一旦源端开始关闭数据包交付上下文(PDC),便会进入 “静默”(QUIESCE)状态:此时仍会继续发送关闭请求发起前已开始的消息对应的数据包,但会拒绝新的消息请求。待所有消息处理完毕后,源端进入 “确认等待”(ACK WAIT)状态,直至收到所有未完成的响应。收到所有响应后,源端向目标端发送最终关闭命令,目标端随之关闭数据包交付上下文(PDC)。当源端收到针对关闭命令的最终确认数据包时,源端的数据包交付上下文(PDC)资源将被释放。

快速数据包丢失检测
当超以太网数据包丢失时,需从源端重新传输。目前,超时机制是重传丢失数据包的常用标准方法,但超时机制并非可靠的丢包检测手段——数据包可能仍在交换机缓冲队列中等待转发,而源端已因超时触发重传,导致带宽浪费和重复传输。若要确保超时数据包未在网络中等待,需设置极高的超时阈值(尤其在深度缓冲的数据中心交换机和长路径场景中),但这会导致拥塞丢包链路的带宽利用率大幅降低。在实际应用中,很难找到兼顾 “避免不必要重传” 与 “保证带宽利用率” 的最优超时阈值。因此,超以太网定义了多种更快速的丢包检测机制作为替代方案。
超以太网将数据包丢失分为三类(此处称为 “网络中的三类丢包”):一是拥塞丢包,即交换机缓冲空间满时发生的丢包;二是损坏丢包,即数据包因比特错误未通过校验和检查导致的丢包;三是配置丢包,即网络因配置原因(如防火墙拦截、生存时间(TTL)过期)导致的丢包。超以太网定义了三种可选的丢包检测机制,均能检测拥塞丢包,其中一种还可可靠检测损坏丢包。
第一种也是最简单的机制是数据包裁剪(packet trimming),但该机制需交换机支持。在该机制下,可配置交换机对即将丢弃的数据包进行有效载荷裁剪,仅保留报头,并可能以更高优先级将裁剪后的数据包转发至目标端。目标端收到裁剪数据包后,即可知晓数据包有效载荷已丢失,并能快速请求源端重传。超以太网规范定义了基于交换机的数据包裁剪的详细行为,但该机制无法检测损坏丢包。
第二种机制是无序计数(out-of-order count),通过计算最后接收的数据包序列号(PSN)与最早缺失的数据包序列号(PSN)之间的差值,估算丢失数据包数量。该计数可在目标端计算后通过可选的无序计数(OOO_COUNT)确认扩展报头字段发送至源端,也可由源端自行估算。若该计数器超过特定阈值,系统则判定数据包丢失。相较于超时机制,该机制的准确性更高,但在数据包喷洒场景中,若不同路径的数据包延迟差异过大,仍可能导致重复传输。
第三种机制是基于熵值(EV)的检测方案,可实现精确丢包检测。最简单的方案是在源端维护已发送数据包的(熵值EV,数据包序列号 PSN)有序列表,并将每个传入的确认数据包与该列表进行匹配。由于超以太网的确认数据包按到达顺序生成,且携带与被确认数据包相同的熵值(EV),在无硬件故障的情况下,一个熵值(EV)对应一条唯一路径——因此,源端只需在发送列表中查找具有相同熵值(EV)的最早条目,若接收的数据包序列号(PSN)与该条目不匹配,即可推断所有具有相同熵值(EV)且数据包序列号(PSN)小于接收值的数据包均已丢失。这一简单但效率较低的方案可通过 “k个时隙轮询喷洒数据包” 的机制优化:此时每个时隙预期接收的数据包序列号(PSN)为i、i+k、i+2k…… 若确认数据包对应的数据包序列号(PSN)晚于预期值,则可推断发生丢包。对于尾部丢包(tail loss),可通过沿特定路径(熵值EV)发送探测控制数据包检测;此类探测数据包也可用于负载均衡场景中调整特定时隙的熵值(EV)。
数据包喷洒与可靠性
在数据包喷洒网络中,由于数据包到达顺序与发送顺序不一致,可靠传输和消息语义机制面临独特挑战。目标端维护位图(bitmap)用于消息完成状态跟踪和可靠性管理。超以太网定义了累积确认(CACK)数据包序列号(PSN),使得一个确认数据包可确认多个数据数据包,该机制在确认数据包丢失时尤为有用。此外,超以太网支持可选的确认合并(ACK coalescing)机制,允许接收端无需对每个数据数据包单独生成确认——这一机制适用于 “生成每个确认数据包成本过高” 的系统。超以太网的确认数据包还携带 64 位选择性确认(SACK)位图,位图中置 1 的位表示对应数据包已到达目标端,据此可推断部分数据包的丢失情况。
可靠无序协议的核心实现挑战是“数据包乱序程度控制”——目标端需通过位图等结构跟踪乱序到达的数据包。最坏情况下,无序网络可能 “先交付最后一个数据包”;高带宽网络上的小消息(目标 RTT 为 10μs)需覆盖 “带宽延迟积(BDP)” 的大幅位图,超出部分实现的资源承载能力。考虑到 UE 的无连接特性(无需往返握手即可启动通信)与 “位图资源动态分配需求”,UE 引入 “最大 PSN 范围(Maximum PSN Range,MP_RANGE)” 概念:线协议的 MP_RANGE 字段允许通信目标端 “动态调整允许的未完成 PSN 范围”,明确限制数据包跟踪所需的资源。与 UE 的多数设计一致,通信初始阶段采用 “乐观假设”(目标端可跟踪所有发送的数据包),为 “优化实现与调优应用” 提供性能保障;若后续目标端资源受限,协议可平滑恢复,避免资源溢出。
传输层拥塞管理子系统(CMS)
超以太网传输层(UET)的拥塞管理子系统设计仅要求交换机基础设施提供最低限度的支持,以便能在传统网络环境中部署。该子系统既包含用于限制网络中字节数量的拥塞控制(CC)功能,也包含用于选择优质路径的负载均衡(LB)功能,仅要求交换机支持出口端的基础显式拥塞通知(ECN)标记和等价多路径(ECMP)负载均衡。超以太网的拥塞管理子系统针对尽力而为型网络进行了设计和仿真测试,能够充分利用数据包裁剪等快速丢包检测机制。
当超以太网与其他流量共享网络时,其设计假设是可利用以太网的服务类别(CoS)功能将超以太网流量分配到独立的流量类别中。未来版本可能会增加对先进拥塞信令技术和其他网络内遥测技术的支持。如前文所述,超以太网定义了多种控制数据包类型,可用于探测路径状态,以收集更多拥塞信息或检测丢包情况。
从本质上讲,超以太网的拥塞管理通过拥塞控制上下文(CCC)实现,一个拥塞控制上下文可服务于一个或多个数据包交付上下文(PDC)。通常,一个拥塞控制上下文会协调同一对结构端点(FEP)之间相同流量类型的所有数据包交付上下文。在发送端,拥塞控制上下文会维护一个拥塞窗口,用于限制网络中未确认字节的数量,该窗口可看作是发送端在等待确认前能向网络中发送的字节数(信用额度)。
超以太网提供两种互补的拥塞控制算法:基于网络信号的拥塞控制(NSCC)和基于接收端信用的拥塞控制(RCCC)。基于网络信号的拥塞控制在源端运行控制循环以调整窗口大小,所有超以太网网卡(NIC)均支持该算法;基于接收端信用的拥塞控制则定义了一种由接收端驱动的信用分配算法,该算法为可选实现。这两种算法均可在运行时禁用,因此实现了基于接收端信用的拥塞控制的系统可支持所有可能的配置模式:仅使用基于网络信号的拥塞控制、仅使用基于接收端信用的拥塞控制,或两者结合使用。
基于网络信号的拥塞控制(NSCC):基于网络信号的拥塞控制(NSCC)受此前多种算法启发,其早期版本已由超以太网拥塞管理子系统团队记录并分析 [6],后续有一个子团队发布了相关分析报告 [27]。该算法结合了两种核心信号:往返时间(RTT)和从请求数据包到响应数据包的显式拥塞通知(ECN)标记。下文假设采用逐包确认(ACK)机制,以便能精确测量这两种信号;该算法也支持累积确认(CACK)和选择性确认(SACK,可确认多个数据包),但这两种确认方式可能会导致更复杂的情况。
显式拥塞通知(ECN)标记 [29] 可视为一种统计型 1 位信号。交换机被配置为以概率方式标记数据包,若观测到足够多的数据包且路径上交换机缓冲区状态未发生变化,源端就能准确了解路径的拥塞情况。然而,即使路径上有多个交换机都要设置显式拥塞通知拥塞经历(ECN-CE)标志(简称 “ECN 位”),该标志最终也只会被设置一次。遗憾的是,这种方式可能需要观测大量数据包才能收敛,且缓冲区状态通常处于动态变化中。超以太网要求在数据包离开交换机时(出口端)进行 ECN 标记,这与 RFC 3168 标准的规定不同,但却是当前交换机的常见实践方式。通过出口端标记,信号生成可绕过队列,从而快速反馈给发送端。目前已有多种拥塞控制方案仅依赖 ECN 实现。
另一方面,往返时间(RTT)可视为一种多位信号,因其能根据本地计时器的精度记录从请求到响应的精确时间。但往返时间会显著延迟拥塞信号的反馈,因为它无法绕过任何拥塞的交换机队列。若交换机缓冲区容量大且已接近填满,同时路径跳数较多,发送端要获取用于拥塞控制的往返时间信息可能需要较长时间。即便在稳定状态下,随着网络状态的快速变化,往返时间信息也可能迅速过时。超以太网在测量往返时间时,会排除接收端的服务时间。目前也有多种拥塞控制方案仅基于往返时间实现。
基于网络信号的拥塞控制同时利用这两种信号——快速的 ECN 1 位信号和滞后的 RTT 多位信号,并定义了确认数据包到达时的以下四种情况:
(1)存在 ECN 标记 + 低往返时间:表明至少有一个交换机缓冲区的拥塞正在加剧;
(2)存在 ECN 标记 + 高往返时间:表明网络已出现拥塞,可能处于过载状态;
(3)无 ECN 标记 + 低往返时间:表明网络无拥塞,可能处于未充分利用状态;
(4)无 ECN 标记 + 高往返时间:表明网络拥塞状况正在缓解。
为区分往返时间的 “低” 与 “高”,基于网络信号的拥塞控制会持续维护一个数值,用于表示其对当前预期无负载往返时间的最佳估算。该算法在第一种情况下不做响应,但会在其他三种情况下调整拥塞窗口大小:第二种情况下,会针对每个传入的确认数据包大幅减小拥塞窗口;第三种情况下,会根据测量到的往返时间与预期往返时间的差值快速增大拥塞窗口;第四种情况下,则会平缓增大拥塞窗口。
除上述四种情况外,基于网络信号的拥塞控制还采用快速自适应(QA)算法来估算网络中的瓶颈(如接收端入向拥塞或交换机处拥塞)。该算法利用丢包信号(如数据包裁剪等快速丢包检测机制),根据成功交付数据包的比例快速调整发送速率。关于上述四种情况及快速自适应算法的详细解释、测量数据和设计思路,可参考 SMaRTT 论文。
基于接收端信用的拥塞控制(RCCC):超以太网传输层的基于接收端信用的拥塞控制(RCCC)受早期同类方案启发 [18]。与基于网络信号的拥塞控制不同,发送端不会根据网络信号调整窗口大小,而是在发送数据包时减小窗口,并在收到接收端反馈的信用额度时增大窗口。所有信用额度管理均由接收端负责,接收端知晓传入流量的精确数量,并以特定速率向发送端分配信用额度。这种机制对多种流量模式都极为有利,还能考虑源端的需求,为流量需求不稳定的工作负载高效调度各源端的速率。
这种方法的主要优势在于简洁性,且对多种相关工作负载均有效。在接收端出现入向拥塞(incast)时,基于接收端信用的拥塞控制能很好地控制流量,而基于网络信号的拥塞控制对此只能通过快速自适应算法进行推测。但该算法无法应对网络中的拥塞或源端的出向拥塞(outcast),因此超以太网建议在超订阅网络中同时启用基于网络信号的拥塞控制。基于接收端信用的拥塞控制也可采用专有实现,利用接收端的其他信号来调整速率。将两种算法结合使用可实现最高吞吐量,下文将概述三种典型拥塞场景及两种算法在各场景下的表现。
入向拥塞、出向拥塞与超订阅:基于接收端信用的拥塞控制和基于网络信号的拥塞控制均采用乐观策略,初始时以满速率(线路速率)运行,拥塞窗口大小等于或略大于带宽延迟积(BDP)。若网络无拥塞,两者会持续以该速率运行,其核心目的是在拥塞发生时控制网络负载。

图 7 展示了三种常见的拥塞场景:在 2:1 超订阅胖树网络中,彩色线条代表从源端到目的端的流量。右侧第 4 组展示了典型的入向拥塞场景:节点 j、k、l、m 均向节点 I 发送流量。基于接收端信用的拥塞控制会检测所有传入流量,并为每个流量分配 25% 的带宽。每条流量旁标注的 “x/y%” 表示基于接收端信用的拥塞控制为该流量分配了 y% 的带宽,实际交付速率为 x%;在入向拥塞场景下,带宽利用率可达到最优。基于网络信号的拥塞控制最终也能达到相同的带宽利用率,但所需时间更长(需通过快速自适应算法检测丢包,或通过往返时间 / ECN 信号机制调整)。
左侧第 1 组展示了与入向拥塞相反的出向拥塞场景:这种场景下,基于网络信号的拥塞控制可轻松应对,但基于接收端信用的拥塞控制可能面临挑战。节点 O 向节点 p、q、r、v 发送流量,同时节点 w 也向节点 v 发送流量。基于接收端信用的拥塞控制会为节点 p、q、r 的传入流量分配 100% 带宽,为节点 v 的传入流量分配 50% 带宽(因节点 v 存在本地入向拥塞)。此时节点 O 的发送速率上限为 100%,因此会向每个目标节点发送 25% 的流量,这本身并无问题;但运行在节点 v 上的基于接收端信用的拥塞控制仅为来自节点 w 的流量分配 50% 带宽,而实际可分配带宽为 75%,导致 25% 的带宽被浪费。基于网络信号的拥塞控制虽然收敛速度较慢,但最终能调整到最优配置。
中间第 2 组和第 3 组展示了更复杂的网络内拥塞场景:第 2 组中标记为 “C” 的 12 个节点分别以线路速率向第 3 组中同样标记为 “C” 的对应节点发送流量。在无阻塞网络中,这种传输是可行的;但在超订阅网络中,瓶颈交换机(标记为 “B”)需接收 12 条流量,却仅有 4 个上行端口,因此只能满足 33% 的带宽需求。若此时第 3 组中的节点 v 向某一 “C” 节点发送流量,运行在该 “C” 节点上的基于接收端信用的拥塞控制仅会为该流量分配 50% 带宽,而实际可分配带宽为 67%,再次导致带宽利用率低下。
出向拥塞、入向拥塞和网络内拥塞是推动使用基于网络信号的拥塞控制的典型场景——尽管受信号传播延迟影响,其收敛速度可能较慢。基于接收端信用的拥塞控制虽能完美应对入向拥塞,但在两种场景下仍需依赖基于网络信号的拥塞控制,因此超以太网建议在启用基于接收端信用的拥塞控制时,同时启用基于网络信号的拥塞控制。当然,在某些场景下(如全带宽网络且工作负载无出向拥塞模式),单独使用简单的基于接收端信用的拥塞控制算法也有望实现良好性能。
目的端流控制:通过拥塞控制调节网络速率只是实现端点间成功数据传输的一部分。接收端、目的端内存或本地总线可能会因速度较慢或负载过高,无法始终以满速率处理传入数据包,这会导致目的端结构端点(FEP)与目的端内存之间出现丢包,进而需要重传。超以太网的目的端流控制(DFC)是一种简单协议,即便在网络已允许的情况下,也能进一步限制发送端的速率。
在基于接收端信用的拥塞控制中,目的端流控制通过降低向发送端的信用额度分配速率实现,从而根据目的端拥塞情况调整发送速率;在基于网络信号的拥塞控制中,接收端会向发送端发送一个 8 字节的拥塞窗口惩罚值,发送端利用该值调整拥塞窗口大小。目的端流控制能让两种算法快速响应目的端内存的瞬时或持续拥塞情况。
负载均衡:超以太网为可靠无序交付(RUD)和幂等操作可靠无序交付(RUDI)流量定义了多种负载均衡机制。在超以太网 1.0 版本中,特定数据包交付上下文(PDC)的所有可靠有序交付(ROD)流量必须沿同一条路径传输。超以太网不允许端点选择特定路径,但可通过熵值(EV)控制路径切换时机 —— 实际路径由基于报头(含熵值)的哈希函数决定。理论上,可构建仅将熵值作为输入的特殊哈希函数系统,使端点能选择特定路径,但此类系统在处理故障时可能较为复杂。超以太网仅对无故障场景做最低限度的保证:(1)相同熵值会选择同一条路径;(2)不同熵值大概率会选择不同路径,这通常可通过当前广泛使用的高混淆度哈希函数实现。
超以太网传输层的设计确保即便每个数据包选择不同的熵值/路径,系统仍能正常运行,因此负载均衡可独立于可靠性、拥塞控制等其他功能实现。需注意的是,超以太网的拥塞控制基于拥塞控制上下文(CCC)而非单条路径实现,因此在整体系统架构设计中,必须考虑负载均衡与拥塞控制之间的相互作用。负载均衡策略在拥塞控制上下文层面实现,适用于所有关联的数据包交付上下文。
最简单的负载均衡方案是 “无感知喷洒”:源端拥塞控制上下文为每个注入的数据包分配不同的熵值。熵值的数量可能有限制,也可能随机选择,但这种方案不考虑路径反馈信息。超以太网建议将无感知喷洒与数据包裁剪等快速丢包检测机制结合使用,这样既能快速恢复丢失的数据包,又能实现网络流量的统计均衡。若同一流量类别的所有端点均配置无感知喷洒,且无其他流量干扰,该方案的效果最佳。
若存在其他流量(如可靠有序交付流量)共享网络或流量类别,无感知喷洒的效果可能不佳。此类场景下,超以太网建议采用 “路径感知喷洒”:通过跟踪不同熵值对应的吞吐量来平衡负载。若收到裁剪数据包的否定确认(NACK)或带 ECN-CE 标记的确认数据包,负载均衡方案会判定对应熵值的路径存在拥塞。超以太网还提供了一种机制,可区分最后一跳的裁剪与网络内的裁剪 —— 因调整熵值无法解决最后一跳的裁剪问题。超以太网通常将熵值选择方式和路径质量跟踪方法交由具体实现决定,并提供了两种示例选择机制:
(1)循环熵值喷洒(REPS):其最简形式不维护任何端点状态,依赖简单的控制循环:发送数据包时,优先使用通过确认数据包返回的 “循环熵值”;若无可用循环熵值(如启动阶段),则随机选择新的熵值。这些熵值用于发送新数据包后,会通过确认数据包返回。该机制具有自计时特性 —— 例如,若存在一条慢路径和一条快路径,最终两条路径会因确认数据包的返回速率不同而均以最优容量运行。在稳定状态且网络条件不变的情况下,循环熵值喷洒可收敛至每条路径的最优带宽。
(2)超以太网规范中提及的另一种方案:在源端维护一组随机熵值及对应的位图。若某一熵值对应的路径检测到拥塞,源端会将位图中对应位置的比特置 1;发送数据包时,源端会循环遍历熵值,跳过位图中比特为 1 的熵值;被跳过的熵值对应的比特会在后续操作中置 0,以便在下一轮循环中被重新选择。熵值的数量可动态调整,以改变重试拥塞熵值的频率。
超以太网中的所有负载均衡方案均为可选,厂商还可自行研发其他方案。不同负载均衡方案在网络中可能存在复杂的相互影响,因此在系统设计时需格外注意。
传输层安全子系统(TSS)
超以太网在设计之初就充分考虑了安全性,其设计灵感源自 sRDMA 、ReDMArk ,以及 PSP、IPSec和 MACSec 规范。传输层安全子系统(TSS)采用 “零信任” 安全模型,为一组结构端点(FEP)之间提供端到端的机密性和认证服务。作为传输层安全服务,它不定义与主机内存的交互,但设计为可与 PCI Express 可信执行环境设备接口安全协议(TDISP)等机制协同工作,以提供完整的安全解决方案。语义子层(SES)、数据包交付子层(PDS)和传输层安全子层均支持多种计数器,可记录可能表明攻击行为的错误。
TSS 加密:传输层安全子系统(TSS)是一项可选服务,可对数据包交付子层(PDS)报头、语义子层(SES)报头、有效载荷以及数据包的 IP 地址进行认证。系统提供灵活配置选项,可选择对数据包的哪些部分进行加密 —— 这需要在信息泄露风险与网络可见性之间进行权衡。在零信任模型中,交换机不可信,但需提供拥塞和服务质量信息。因此,显式拥塞通知(ECN)标记和数据包裁剪操作不进行认证,且会通过严格处理将攻击面降至最低(例如,裁剪数据包不得触发数据包交付上下文(PDC)的创建)。
传输层安全子系统定义了 “安全域(SD)” 概念:安全域为一组结构端点提供机密性和认证服务,实现与其他安全域及未加密流量的完全数据隔离。一个安全域可服务于多个作业,也可专用于单个作业,以提供可扩展的架构。安全域的所有成员均使用相同的对称加密安全域密钥(SDK)作为认证和机密性服务的基础,该密钥由管理实体(SDME)分发给安全域的所有成员,同时管理实体还负责更新密钥和维护安全域成员列表。
根据使用场景,SD提供了几种机制来获取用于每个数据包的symmetrickeys。最简单的方法是直接使用SDK。第二种模式针对分布式通信进行了优化,它使用密钥推导函数(KDF),这是一种确定性的不可逆函数,它从域密钥和一些参数(例如源或目标地址)推导出源密钥。最后,用于客户端-服务器通信的模式使用KDF和目标地址来推导每个源密钥,从而提升服务器的扩展能力。
UE采用认证加密与关联数据(AEAD)技术。默认算法为AESGCM。使用256b密钥和16B身份验证标签或ICV(完整性校验值)。一个关键的安全参数是密码的初始化向量(IV),它被当作一次性使用的数值,不得在群组的所有成员间重复使用。SD的一个关键特性是,域中的所有成员都拥有相同的密钥,而确保IV不被重复使用是该协议设计的关键部分。每个数据包中都包含一个时间戳计数器(TSC),它由16位的纪元标识符和48位的包计数器组成纪元由SDME管理,用于协助成员的增加和移除,而包计数器则用于记录FEP发送的每个数据包的递增计数。
为应对 IETF(互联网工程任务组)RFC 9001 附录 B 中所述的、针对 “AES-GCM 算法因使用固定随机数(nonce)、已认证数据及加密数据而遭受的攻击”,传输安全子层(TSS)定义了一种初始化向量(IV)掩码。在将数据包的 IV 输入密码算法之前,需先将该 IV 与 IV 掩码进行异或运算。此操作可确保 IV 具备随机性,且不会被攻击者直接获取。IV 掩码既可以作为安全域(SD)的属性进行存储,也可以通过密钥派生函数(KDF)生成。
提供了几种机制来管理关键生命周期,即在此上下文中指的是使用同一密钥加密的包数量。根据安全模型的假设(单用户 vs.多用户),限制范围在227到234.5个包之间。
密钥轮换会更新安全域密钥(SDK)与关联编号(AN)。每个接收端会为每个安全域(SD)维护多个关联编号密钥(AN 密钥),以支持无缝密钥轮换。此外,还可将时间戳计数器(TSC)的部分字段接入密钥派生函数(KDF),实现 “随着数据包计数增加,自动周期性更新源端密钥” 的功能。
防止重放攻击:为防止数据包序列号(PSN)回绕时出现重放攻击,使用加密功能的每个数据包交付上下文(PDC)在发送 20 亿个数据包后,必须关闭并重新建立。此外,数据包交付子系统(PDS)本质上是无状态的,因此若其在建立新 PDC 时接受任意初始数据包序列号(PSN),可能容易遭受重放攻击——初始数据包中携带的事务可能会以非预期方式修改目标端状态。因此,在使用加密功能时,数据包交付子系统需通过以下两种方式之一安全地建立初始数据包序列号(PSN)。
第一种方式需额外增加一个往返时间(RTT)来建立安全的 PSN:发起方向目标端发送的第一个数据包为 “无操作”(NOP)数据包,用于查询起始 PSN;目标端随后返回本地已知的随机起始 PSN,并创建处于 “待处理” 状态的 PDC。尽管该方案通过协商随机起始 PSN 可防止重放攻击,但额外增加的 RTT 可能不符合部分场景的需求。
第二种方案支持 “零开销启动”,但需在安全域(SD)内进行一定协调:为每个安全域关联存储两个初始值均为 0 的参数——start_psn和expected_psn。其中,start_psn用于新请求建立的 PDC,expected_psn则是新接入 PDC 的最小可接受 PSN。若目标端收到的连接请求中 PSN 小于expected_psn,会生成否定确认(NACK)并指明应使用的起始 PSN;反之则接受该请求。当某个 PDC 关闭时,目标端会将expected_psn更新为该关闭 PDC 的当前 PSN+1,确保无法进行重放攻击。更新后的expected_psn会随 PDC 关闭确认(ACK)数据包反馈给源端,源端随后将start_psn更新为该值,以确保后续连接可实现 “零 RTT” 建立。该方案无法保证始终实现零 RTT PDC 建立,失败时会回退到 “一 RTT” 建立方式,同时允许通过额外启发式算法设置start_psn或expected_psn,以提高零 RTT 建立的概率。两种方案可实现互操作。
链路层特性
超以太网兼容的链路层引入了两项独立的可选特性:链路层重试(LLR)和基于信用的流控制(CBFC)。为保持以太网兼容性,链路层通过链路层发现协议(LLDP)与对等设备协商是否启用这两项特性。
链路层重试(LLR):随着链路带宽的提升和误码率的潜在增加,传统端到端重传机制可能对延迟敏感型工作负载产生负面影响。链路层重试(LLR)机制可在传输以太网帧时,在链路层本地处理错误:发送端将所有符合 LLR 条件的帧存储在重放缓冲区中,并在帧的前导码中编码序列号;接收端链路在成功接收帧后,向源端发送确认(ACK),以释放源端的重放缓冲区。对于末尾数据包的恢复,采用 “回退 N 帧”(go-back-N)重传机制——根据帧的到达顺序检测缺失的序列号,并发送否定确认(NACK);同时,通过重传超时机制防止末尾数据包(尾部丢失)或 NACK 丢失。确认(ACK)、否定确认(NACK)等控制数据包通过物理层(PHY Layer)的物理编码子层(PCS)子系统发送,编码为 8 字节的控制有序集(Control Ordered Sets)。
从超以太网传输层(UET)的新协议设计背景来看——其部分设计初衷是消除重传超时和 “回退 N 帧” 重传机制——链路层选择上述方案看似矛盾,但链路层环境与跨大规模系统的传输层环境存在本质差异:在链路层环境中,重传超时可严格限定在链路往返时间(约 1 微秒)内,且数据包仅因物理层错误(如无法纠正的前向纠错(FEC)符号错误或帧校验序列(FCS)错误)被丢弃,拥塞不会导致数据包丢弃或影响往返时间。因此,采用 “回退 N 帧” 协议并辅以短重传超时机制已足够满足需求,同时可避免链路层需理解流量排序要求的复杂设计。
基于信用的流控制(CBFC):超以太网的基于信用的流控制(CBFC)提供链路层流控功能,可与融合以太网的基于优先级的流控制(PFC)配合使用,也可替代 PFC。两种方案的目标均是提供近无损的数据包服务,消除因到达数据包缺乏缓冲空间导致的拥塞丢包——此类拥塞丢包是采用 “回退 N 帧” 重传策略的端到端可靠系统(如超以太网的可靠有序交付(ROD)服务)性能下降的主要原因。即便拥塞管理机制已优化,交换机缓冲区溢出、网络路径过长、流量模式高度可变等因素仍可能导致数据包丢失,而通过端到端(E2E)重传协议解决此类丢失至少需额外增加一个 RTT 延迟。CBFC 或 PFC 可通过构建无损链路层(第二层)网络结构,优化上述场景的性能。
与 PFC 相比,CBFC 具有以下优势:
(1)保障交付所需的缓冲空间更小;
(2)发送端可利用各虚拟通道的信用可用信息进行本地调度;
(3)配置更简单,易于实现保障交付;
(4)对吞吐量有限制的虚拟通道,可使用更少的缓冲空间。
为实现无损操作,PFC 要求每个端口配备 “RTT+MTU” 大小的头部缓冲空间。从交换机角度而言,有多种方式可优化头部缓冲空间,但 CBFC 能更高效地分配和管理该缓冲空间,具体细节可参考 Hoefler 等人的研究。
CBFC 在发送端和接收端均使用两个 20 位循环计数器,根据缓冲区占用情况跟踪 “已消耗信用” 和 “接收端释放的信用”。这些计数器按虚拟通道分别维护,并定期同步以避免信用丢失。超以太网的 CBFC 定义两种消息类型:一是从接收端发送至发送端的高频更新消息,编码为 8 字节控制有序集;二是从发送端发送至接收端的低频更新消息,编码为 64 字节数据包。
发送端在发送数据包前,会先本地检查信用可用性;数据包发送后,从信用中扣除该数据包大小。接收端在数据包离开其缓冲区后,通过更新消息将信用返还给发送端。发送端会定期向接收端发送更新消息,防止信用丢失。总体而言,该协议可确保仅当接收端有足够缓冲空间时,发送端才会发送数据包。
总结与结论
超以太网(UE)的研发历时 30 个月,凝聚了众多参与者的努力。其 1.0 版本在多个领域实现创新,助力以太网生态系统为人工智能(AI)和高性能计算(HPC)工作负载提供高效、经济且安全的网络支持。首个版本的规范后续大概率需要经过多轮勘误澄清与修复。目前,首批超以太网相关产品已正式发布,预计数月内可投入使用。
参考链接
致谢本文作者:

*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
END
今天是《半导体行业观察》为您分享的第4143期内容,欢迎关注。
推荐阅读

加星标⭐️第一时间看推送,小号防走丢