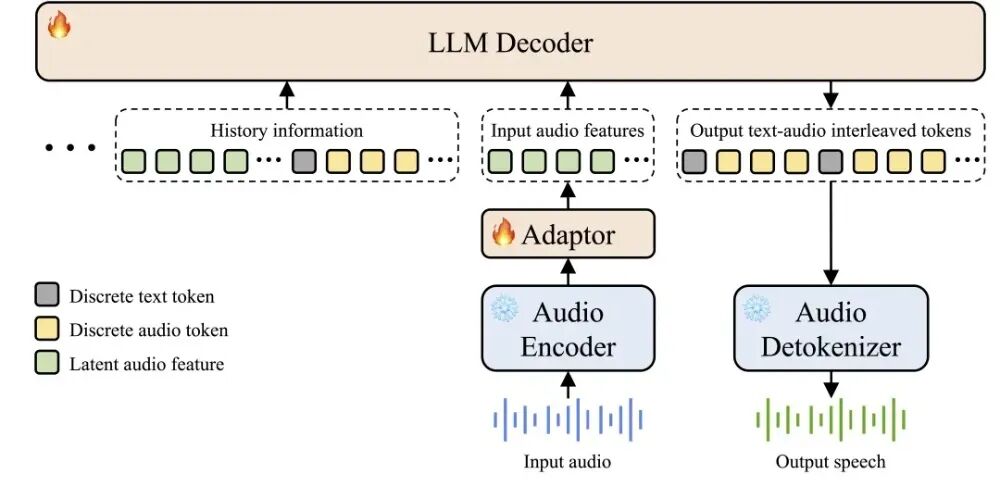

在通用多模态音频理解测试集MMAU上,Step-Audio 2 mini以73.2的得分位列开源端到端语音模型榜首;
在衡量口语对话能力的URO Bench上,Step-Audio 2 mini在基础与专业赛道均拿下开源端到端语音模型最高分,超越Qwen-Omni和Kimi-Audio;
在中英互译任务方面,Step-Audio 2 mini在CoVoST 2和CVSS评测集上分别取得39.3和29.1的分数,领先GPT-4o Audio;
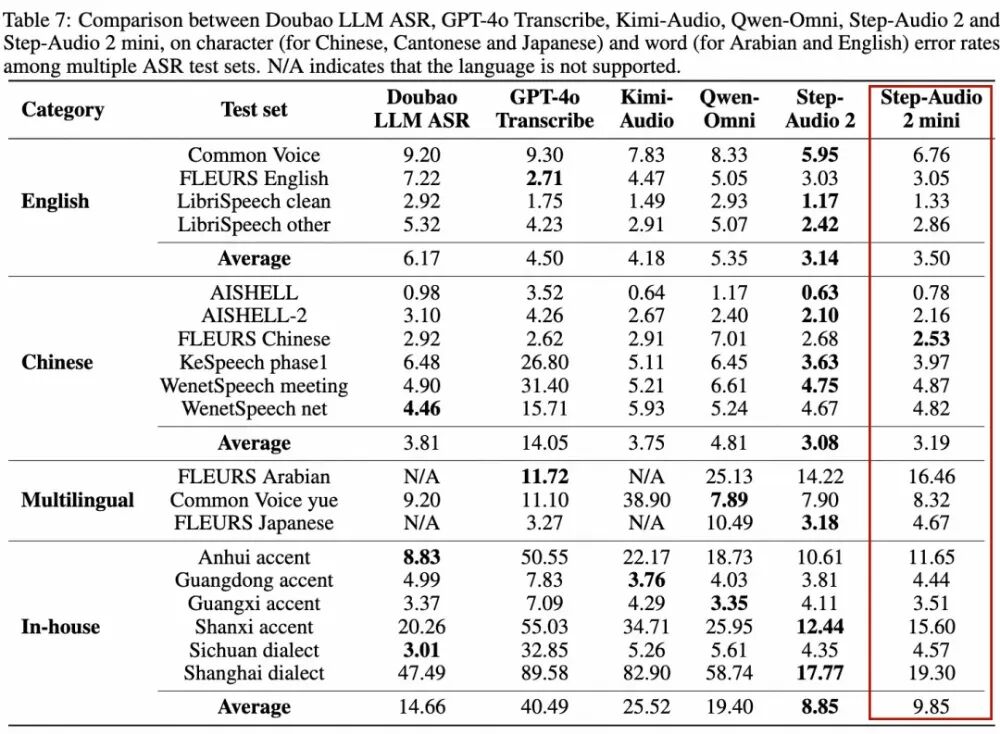
在语音识别任务上,Step-Audio 2 mini取得多语言和多方言第一。其中开源中文测试集平均CER(字错误率)3.19,开源英语测试集平均WER(词错误率)3.50。