人类能从有限的感官输入中构建具有预测能力的世界模型,从而预测未来结果并适应新场景。受此启发,世界模型也推动了机器人操作领域的研究。世界模型能让机器人具备交互推理、动态预测及未知环境的适应能力。
如何有效表示、构建并利用世界模型以增强机器人操作能力?这种需求对现有表示方法与模型提出了重大挑战。基于视频的生成模型对图像输入依赖,容易受到未知视觉变化的影响,缺乏3D几何和空间理解。多视图3D重建方法,如3DGS,能对3D场景进行显式的per-Gaussian建模。但这些方法主要依赖于离线的per-scene重建,其计算需求在机器人操作中存在重大挑战,限制了其可扩展性。
为此,清华大学联合北京通用人工智能研究院BIGAI、南洋理工大学提出一种将3DGS与生成模型相结合的创新3D高斯世界模型GWM,用于机器人操作领域。该模型通过高斯扩散Transformer与高斯VAE实现高效的动态建模,能在无需人工干预的端到端方式下准确预测未来状态与动力学。

在仿真实验中,GWM相对基线模型性能平均提高了16.25%;在真实场景中,模型在20次实验中性能提高了30%,验证了其可行性。与GWM相关的论文成果已收录于ICCV 2025。

论文标题:《GWM: Towards Scalable Gaussian World Models for Robotic Manipulation》
论文链接:https://arxiv.org/abs/2508.17600
项目主页:
https://gaussian-world-model.github.io/
收录情况:ICCV 2025
1
方法
1.1 整体架构
GWM的整体架构如下图所示,核心是构建高斯世界模型用来推断3D高斯基元表征的未来场景重建结果。GWM包含一个3D变分编码器和一个潜在扩散transformer。3D变分编码器由基础重建模型估计出的高斯泼溅嵌入到一个紧凑的潜在空间中,而扩散transformer则作用于这些潜在patches,以机器人动作和去噪时间步长为条件,交互式地推演出未来的高斯泼溅。

1.2 世界状态编码World State Encoding
前馈式3D高斯泼溅
给定世界状态的单视图或双视图图像输入 ,首先要将场景编码为3D高斯表示,以便进行动态学习和预测。3DGS使用多个非结构化的3D高斯核
,首先要将场景编码为3D高斯表示,以便进行动态学习和预测。3DGS使用多个非结构化的3D高斯核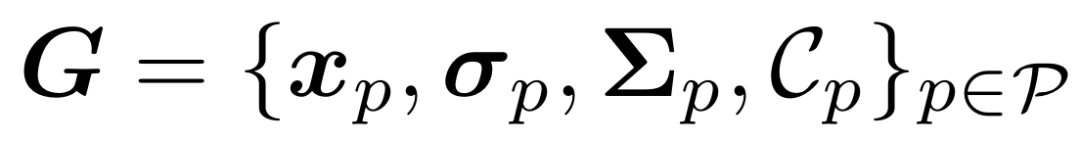 来表示一个3D场景,其中
来表示一个3D场景,其中 分别代表高斯图元的中心、不透明度、协方差矩阵和球谐系数。为了从给定视角获取每个像素的颜色,3DGS将3D高斯图元投影到图像平面上,并按如下公式计算像素颜色:
分别代表高斯图元的中心、不透明度、协方差矩阵和球谐系数。为了从给定视角获取每个像素的颜色,3DGS将3D高斯图元投影到图像平面上,并按如下公式计算像素颜色:

由于标准3DGS依赖耗时的离线逐场景优化,该团队采用可泛化的3DGS来学习从图像到3D高斯图元的前馈映射,以加速此过程。
3D高斯变分自编码器
由于每个世界状态学习到的3D高斯图元数量可能因场景和任务的不同而有显著差异,采用一个3D高斯VAE 将重建的3D高斯图元G编码为固定长度N的潜在嵌入
将重建的3D高斯图元G编码为固定长度N的潜在嵌入 。
。
1.3 基于扩散的动态建模
在给定时间 t 的编码世界状态嵌入 及其未来状态
及其未来状态 的情况下,目标是学习世界动态
的情况下,目标是学习世界动态 ,其中
,其中 和
和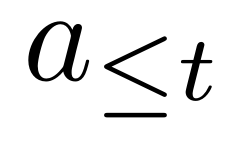 分别表示历史状态和动作。具体来说,该团队利用一个基于扩散的动态模型,将动态学习转化为一个条件生成问题,即以历史状态和动作
分别表示历史状态和动作。具体来说,该团队利用一个基于扩散的动态模型,将动态学习转化为一个条件生成问题,即以历史状态和动作 为条件,从噪声中生成未来状态
为条件,从噪声中生成未来状态 。
。
扩散公式
为生成未来状态,首先定义扩散过程: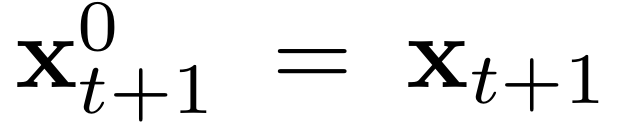 。
。
对真实未来状态添加噪声,通过高斯扰动核得到带噪未来状态样本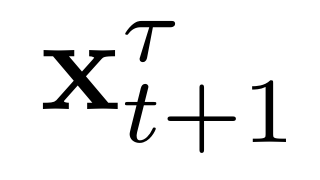 ,公式如下:
,公式如下: 。该扩散过程可描述为随机微分方程(SDE)的解:
。该扩散过程可描述为随机微分方程(SDE)的解: 。
。
基于EDM的学习
研究表明,直接学习去噪器 易受噪声幅度变化等问题影响。为此,本文借鉴EDM的方法,通过预条件化学习网络,具体将去噪器参数化为:
易受噪声幅度变化等问题影响。为此,本文借鉴EDM的方法,通过预条件化学习网络,具体将去噪器参数化为:

1.4 用于策略学习的GWM
用于强化学习的GWM
GWM可以无缝集成到现有的基于模型的强化学习MBRL方法中。马尔可夫决策过程 (MDP) 由元组 定义。S 和 A 是状态和动作空间,
定义。S 和 A 是状态和动作空间, 是折扣因子,
是折扣因子,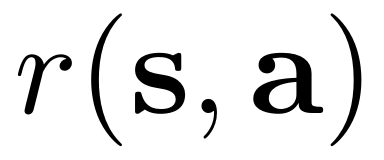 是奖励函数。基于模型的RL目标是学习一个策略 π,以最大化期望折扣回报之和:π∗ =
是奖励函数。基于模型的RL目标是学习一个策略 π,以最大化期望折扣回报之和:π∗ =  ,同时利用策略roll-out的数据构建一个动态模型
,同时利用策略roll-out的数据构建一个动态模型 。研究人员在算法1中提供了基于模型的RL策略学习的伪代码。
。研究人员在算法1中提供了基于模型的RL策略学习的伪代码。

在此框架下,研究人员在GWM之上添加了一个额外的奖励预测头来参数化动态模型 。
。
用于模仿学习的GWM
在模仿学习中,GWM可作为更有效的编码器,为策略学习提供更好的特征。具体来说,研究人员将扩散过程中第一步去噪后的特征向量作为下游策略模型(如BC-transformer和diffusion policy)的输入。第一次去噪保留了具有代表性的空间信息,可应对较强的噪声。在实现中,通过预测顺序块中的动作,实现机器人控制的一致性。
2
实验
2.1 实验设置
实验重点关注以下问题:
在不同领域中,动作条件视频预测的结果质量如何?
高斯世界模型是否有利于下游的模仿学习和强化学习?与基于图像的世界模型相比,是否具有更强的鲁棒性?
高斯世界模型如何帮助典型策略(如扩散策略)提升真实世界机器人操作任务性能?
实验环境
为全面分析GWM的能力,在两个仿真环境和一个真实世界环境中评估:(1) 用于学习机器人操作RL策略的仿真环境Meta-World;(2) 大规模、多场景的仿真环境RoboCasa,专注于厨房环境中的多样化机器人操作任务;(3) 使用Franka Emika FR3机械臂的真实世界抓放环境Franka-PnP。
任务:
研究人员设计了四种类型的任务来评估GWM:(1) 动作条件场景预测,用于评估GWM在世界建模和未来预测的能力;(2) 基于GWM的模仿学习,用于评估GWM表征质量及其对提升基于模仿学习的机器人操作的性能;(3)基于GWM的强化学习,用于探索其在基于模型的强化学习中的潜力;(4) 真实世界任务部署 ,评估GWM在真实世界机器人操作中的鲁棒性。
2.2 动作条件化场景预测
实验设置:世界模型生成高保真度且与动作对齐的滚动序列(rollout)的能力对于策略优化至关重要。为评估此能力,研究人员在本文涉及的所有仿真环境(如Meta-World, RoboCasa)和真实世界环境(Franka-PnP)中,使用这些环境里所能提供的、由人类专家演示的操作数据,对GWM模型进行了训练;并通过以验证集中采样的未见过的动作轨迹为条件评估其预测未来的质量。
对于定量评估,采用生成质量的常用指标,包括衡量时间一致性的FVD、衡量像素级精度的基于图像的指标PSNR以及衡量感知质量的SSIM、LPIPS。
结果与分析:下表展示了GWM与iVideoGPT的定量比较。结果表明,在仿真与真实世界环境中,GWM均优于iVideoGPT,验证了基于扩散的高斯世界模型学习流程的有效性。

值得注意的是,iVideoGPT等基于图像的模型难以捕捉动态细节(如夹爪)。这些细节不会导致视觉指标出现大幅差异,但会显著影响策略学习。
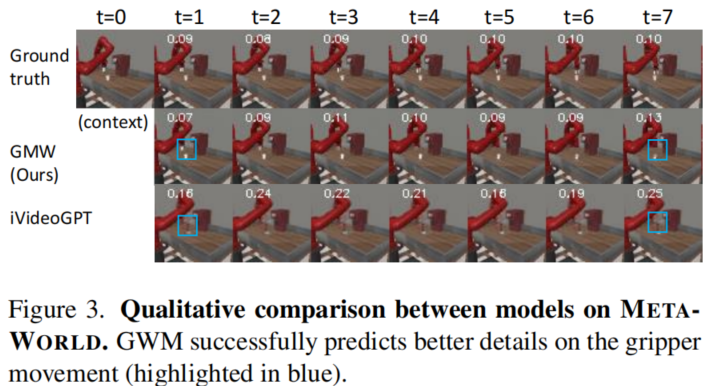
下图展示了GWM在RoboCasa和Franka-PnP上预测结果的可视化。

2.3 基于GWM的模仿学习
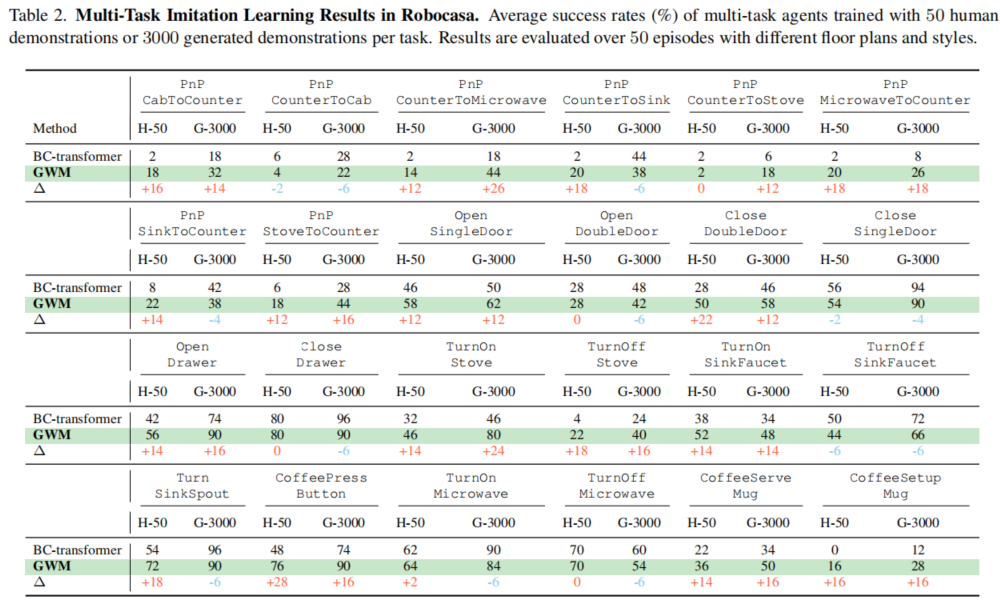
实验设置:GWM可用于从图像观测中提取丰富的信息,有望提升模仿学习性能,在RoboCasa上测试这一特性。RoboCasa任务包含24个原子任务及厨房环境的语言指令,包括抓放、打开和关闭等动作。每个任务提供了50条人类演示数据(H-50)与3000条由MimicGen生成的演示数据(G-3000)。在这些数据上训练了GWM,并将其作为状态编码,与当前最优方法BC-transformer在成功率指标上进行定量对比。
结果与分析:在RoboCasa上的实验结果如下表所示。在24个厨房操作任务中,GWM优于BC-Transformer基线。在有限的人类演示(H-50)下,GWM平均成功率提升了10.5%。在G-3000上训练时,GWM保持了可扩展性,成功率平均提升7.6%。值得注意的是,GWM在复杂操作任务和交互任务中表现突出,性能提升最为显著。实验结果表明,GWM能够从图像观测中提取丰富的信息,提升机器人模仿学习能力。
2.4 基于GWM的强化学习
实验设置:该团队在Meta-World的6项复杂的机器人操作任务上测试GWM。实现了一种受MBPO启发的基于模型的RL方法,使用GWM生成合成数据来扩充DrQ-v2 actor-critic算法的回放缓冲区。将G最先进的基于图像的世界模型iVideoGPT作为强基线模型,与GWM进行对比。为公平比较,两种方法均未使用预训练初始化,所有比较方法使用相同的上下文长度、预测步长,且最多训练1×105步。
结果与分析:实验结果为下图所示。在6项任务中,GWM均优于iVideoGPT。GWM的平均收敛速度约为iVideoGPT的2倍;在复杂操作任务中,GWM能达到更高的渐近性能。
GWM的性能优势源于其3D高斯表示:与基于图像的方法相比,3D高斯表示能更准确地预测操作过程中的动态与物体运动。实验结果证明了GWM对强化学习策略的提升的有效性。

2.5 真实世界部署
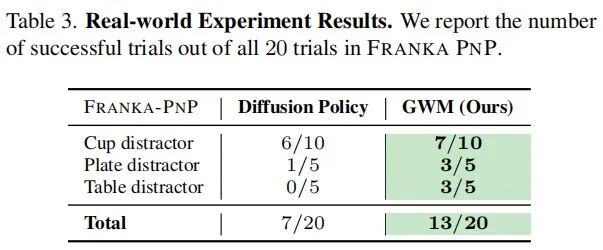
实验设置:该团队将GWM模型部署在一个Franka Emika FR3机械臂和一个Panda夹爪,作为真机实验平台。任务为“让机器人抓取一个彩色的杯子并将其放到桌面上的盘子里”。实验收集30条通过Mujoco AR遥操作界面获取的演示数据,并使用一个Realsense D435i相机提供无位姿RGB图像作为观测。

结果与分析:实验结果如下表所示。在20次(包含不同初始起始位置和干扰物)的实验中,GWM的平均成功率65%,显著优于成功率35%的Diffusion Policy。实验表明,GWM在存在干扰的任务中能保持一致的性能,原因在于该模型能捕捉任务相关动态,同时对视觉差异具有鲁棒性,证明了GWM在真实世界机器人操作任务中具有鲁棒的时空理解能力。
3
总结
本论文中,清华大学联合BIGAI、南洋理工大学提出一种将3DGS与生成模型相结合的创新3D高斯世界模型GWM,用于机器人操作领域。该模型通过整合鲁棒的几何信息,解决了基于图像的世界模型的局限性。GWM通过建模机器人动作作用下高斯基元的传播过程,重建未来状态;该方法结合扩散Transformer(DiT)与具备3D感知能力的变分自编码器,借助高斯泼溅实现精确的场景级未来状态重建。在仿真与真机实验表明,GWM在预测未来场景与训练更优策略方面具有有效性。
END
推荐阅读
灵巧手抓放任务成功率100%!帕西尼联合上交大提出融合触觉的VLA模型OmniVTLA
全面优于π0!星海图开源端到端双系统VLA模型G0:基于500小时真机数据预训练
训练数据65万条!上海AI Lab联合提出端到端VLA模型InstructVLA,真机实验成功率超OpenVLA
20亿参数+全面超越π0!清华朱军团队&地平线提出全新VLA模型H-RDT,有效从人类操作数据中学习
机器人非抓取操作重大突破!北大&银河通用王鹤团队提出自适应世界动作模型DyWA | ICCV 2025
点击下方名片 即刻关注我们










